深入解读DC/OS核心功能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解读DC/OS核心功能相关的知识,希望对你有一定的参考价值。
一、 DC/OS的总体架构
DC/OS,全称数据中心操作系统,基本思想是使得IT人员操作整个数据中如操作一台电脑一样,架构如图:
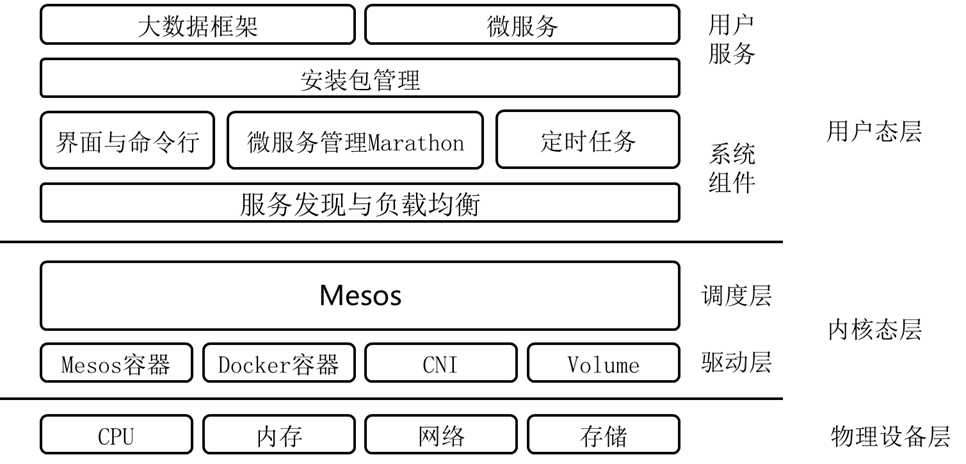
层次一:物理设备层
无论是哪种操作系统,都需要管理外部的硬件设备,例如CPU,内存,存储,网络。
层次二:内核态层
最初使用汇编语言写程序,是需要指定使用那些硬件资源的,例如指定哪个寄存器,放在内存的哪个位置,读取那个串口等,对于这些资源的使用,需要程序员自己心里非常的清楚,否则一旦JUMP错了位置,程序就无法运行。正如运维数据中心的一台台物理机一样,那个程序放在了哪台机器上,使用多少内存,多少硬盘,都需要心里非常的清楚。
为了将程序员从对硬件的直接操作中解放出来,有了操作系统这一层,实现对于硬件资源的统一管理。程序使用哪个CPU,哪部分内存,哪部分硬盘,只需调用API即可,由操作系统自行分配和管理,操作系统只做了一件事情,就是调度。对应到数据中心,也需要一个调度器,将运维人员从指定物理机或者虚拟机的痛苦中解放出来,这就是Mesos。Mesos即使数据中心操作系统的内核。
使用操作系统的时候,可以开发驱动程序来识别新的硬件资源,可以开发内核模块(例如openvswitch.ko)来干预对于硬件资源的使用,对于Mesos,同样可以开发isolator来识别新的硬件资源例如GPU,也可以开发Executor来干预资源的使用。
层次三:用户态层
在内核之上,就是系统服务,例如systemd,是用来维护进程运行的,如果systemctl enable xxx,则保证服务挂掉后自动重启。对于DC/OS,保持服务long run的是marathon,但是仅仅只有marathon还不够,因为服务是启动在多台机器上,并且是有依赖关系的,一个服务挂掉了,在另外一台机器启动起来,如何保持服务之间的调用不需要人工干预呢?这需要另外的技术,称为服务发现,多是通过DNS,负载均衡,虚拟机IP等技术实现的。
使用操作系统,需要安装一些软件,于是需要yum之类的包管理系统,使得软件的使用者和软件的编译者分隔开来,软件的编译者需要知道这个软件需要安装哪些包,包之间的依赖关系是什么,软件安装到什么地方,而软件的使用者仅仅需要yum install就可以了。DC/OS就有这样一套包管理软件,和其他的容器管理平台需要自己编译Docker镜像,自己写yml,自己管理依赖不同,DC/OS的软件使用者只需要dcos package install就可以安装好软件了,软件的配置,节点数目,依赖关系都是有软件编译者设置。
二、DC/OS的调度功能
DC/OS的调度功能是通过Mesos实现的,Mesos的调度过程如图所示:
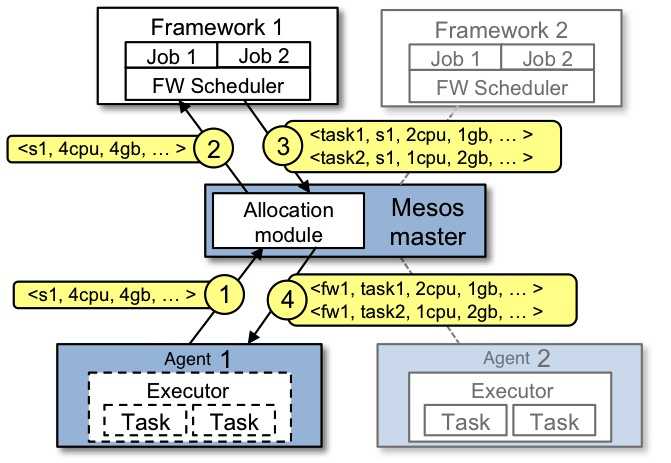
Mesos有Framework, Master, Agent, Executor, Task几部分组成。这里面有两层的Scheduler,一层在Master里面,allocator会将资源公平的分给每一个Framework,二层在Framework里面,Framework的scheduler将资源按规则分配给Task。
Mesos采用了DRF(主导资源公平算法 Dominant Resource Fairness),Framework拥有的全部资源类型份额中占最高百分比的就是Framework的主导份额。DRF算法会使用所有已注册的Framework来计算主导份额,以确保每个Framework能接收到其主导资源的公平份额。
举例说明,考虑一个9个CPU,18GB 内存的系统,拥有两个Framework,其中A运行的任务的需求为{1CPU, 4GB},B运行的任务的需求向量为{3CPU,1GB},A的每个任务消耗总CPU的1/9和总内存的2/9,所以A的主导资源是内存;B的每个任务消耗总CPU的1/3和总内存的1/18,所以B的主导资源为CPU。DRF会均衡两个Framework的主导资源的份额,执行3个A的任务,执行2个B的任务。三个A的任务总共消耗了{3CPU,12GB},两个B的任务总共消耗了{6CPU,2GB};在这个分配中,两个Framework的主导资源的份额是相等的,用户A获得了2/3的,而用户B获得了2/3的CPU。
Mesos的代码实现中,不是用原生的DRF,而是使用HierarchicalDR,也即分层的DRF.
调用了三个排序器Sorter(quotaRoleSorter, roleSorter, frameworkSorter),对所有的Framework进行排序,哪个先得到资源,哪个后得到资源。
总的来说分两大步:先保证有quota的role,调用quotaRoleSorter,然后其他的资源没有quota的再分,调用roleSorter。
对于每一个大步分两个层次排序:一层是按照role排序,第二层是相同的role的不同Framework排序,调用frameworkSorter。
每一层的排序都是按照计算的share进行排序来先给谁,再给谁。Share的计算就是按照DRF算法。
接下来我们具体分析一下这个资源分配的过程。
1. 生成一个数据结构offerable,用于保存资源分配的结果
hashmap<FrameworkID, hashmap<SlaveID, Resources>> offerable;
这是一个MAP,对于每一个Framework,都会有一个资源的MAP,保存的是每个slave上都有哪些资源。
2. 对于所有的slave打乱默认排序,从而使得资源分配相对均匀
std::random_shuffle(slaveIds.begin(), slaveIds.end());
3. 进行第一次三层循环,对于有quota的Framework进行排序
- foreach (const SlaveID& slaveId, slaveIds) {
- foreach (const string& role, quotaRoleSorter->sort()) {
- foreach (const string& frameworkId_, frameworkSorters[role]->sort()) {
对于每一个slave,首先对role进行排序,对于每一个role,对于Framework进行排序,排序靠前的Framework优先获得这个slave。
排序的算法在DRFSorter里面实现,里面有一个函数calculateShare,里面的关键点在于进行了一个循环,对于每一种资源都计算如下的share值:
share = std::max(share, allocation / _total);
allocation除以total即一种资源占用的百分比,这里之所以求max,就是找资源占用百分比最高的资源,也即主导资源。
但是这个share不是直接进行排序,而是share / weights[name]除以权重进行排序。如果权重越大,这个值越小,这个role会排在前面,分配更多的资源。
排序结束后,对于每一个Framework,将当前slave的资源分配给它。
Resources available = slaves[slaveId].total - slaves[slaveId].allocated;
首先查看这个slave的可用资源,也即总资源减去已经分配的资源。
Resources resources = (available.unreserved() + available.reserved(role)).nonRevocable();
每个slave上没有预留的资源和已经预留给这个Framework的资源都会给这个Framework,当然如果上面有预留给其他Framework的资源是不会给当前的Framework的。
offerable[frameworkId][slaveId] += resources;
slaves[slaveId].allocated += resources;
分配的资源会保存在数据结构offerable中。
4. 进行第二次三层循环,对于没有quota的Framework进行排序
- foreach (const SlaveID& slaveId, slaveIds) {
- foreach (const string& role, roleSorter->sort()) {
- foreach (const string& frameworkId_,frameworkSorters[role]->sort()) {
5. 全部分配结束后,将资源真正提供给各个Framework
- foreachkey (const FrameworkID& frameworkId, offerable) {
- offerCallback(frameworkId, offerable[frameworkId]);
- }
这里的offerCallback是调用Master::Offer,最终调用Framework的Scheduler的resourceOffers,让Framework进行二次调度。
三、DC/OS的容器功能
Mesos运行的任务会通过容器进行隔离,提供的容器有两种,一种是原生的Mesos容器,一种是Docker容器。在原来的Mesos版本中,Mesos容器主要运行普通的Mesos的任务,例如命令行,大数据等,而运行Docker的镜像还是需要通过Docker容器。
在Mesos 1.0之后引入了Universal Container Runtime,也即可以使用mesos-containerizer来运行Docker的镜像了。
- "container":{
- "type":"MESOS",
- "docker":{
- "network":"BRIDGE",
- "image":"nginx"
- }
- }
Mesos容器的运行过程:
1. 如果配置文件里面有对于镜像的配置,需要调用Provisioner来创建根文件系统
Future<ProvisionInfo> provisioning = provisioner->provision(containerId, containerImage.get());
在最新的Mesos里面,多了Provisioner这一层,通过Docker的镜像,来使用不同的存储方式(aufs, overlay等)作为backends来生成根文件系统,从而创建Mesos容器。
2. 准备一些executor的运行的环境,Mesos容器运行的一些参数,整个参数比较复杂。
- /bin/sh /root/mesos/build/src/mesos-containerizer launch --command={"shell":true,"value":"\\/root\\/mesos\\/build\\/src\\/examples\\/java\\/test-executor"} --commands={"commands":[]} --directory=/tmp/mesos/slaves/20150615-125933-16777343-5050-28128-S0/frameworks/20150615-130844-16777343-5050-14271-0000/executors/default/runs/1c8429b8-bd1b-4738-af2c-5aa324f0b22f --help=false --pipe_read=8 --pipe_write=9 --user=root
3. 使用mesos-containerizer启动容器
4. 最后调用isolate进行资源隔离的配置
默认的mesos-containerizer的隔离只包括cpu和memory,然而在最新的Open DC/OS版本里面,在配置了更多的隔离器Isolator.
MESOS_ISOLATION=cgroups/cpu,cgroups/mem,disk/du,network/cni,filesystem/linux,docker/runtime,docker/volume。
Isolator定义了很多函数,其中比较重要的是isolate函数,是容器启动的时候对于资源进行限制,例如cgroups/cpu,cgroups/mem这两个isolator,都是写入cgroup文件。
另外一个重要的函数是watch函数,例如对于disk/du这个isolator,对于硬盘使用量,其实没有cgroup可以设置,需要过一段时间du一下,这就需要实现watch函数,过一段时间查看一下硬盘使用量,超过后做一定的操作。
四、DC/OS的网络功能
DC/OS的网络功能是通过CNI (container network interface) 来实现的。
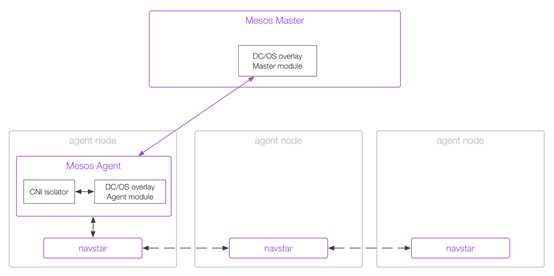
CNI需要三个模块配合工作:
模块一:DC/OS不需要外置的IPAM,而是由mesos-master的replicated_log负责管理分配IP地址,Mesos需要启动的时候,载入overlay network的modules,对应的文件是/opt/mesosphere/active/mesos-overlay-modules/lib/mesos/libmesos_network_overlay.so。
模块二:需要载入CNI isolator,这个在MESOS_ISOLATION这个环境变量里面已经配置了network/cni。
模块三:需要navstar服务来实现跨节点之间的IP互访问
每个mesos-agent的机器上都会运行一个navstar进程。
每个机器上都会创建网卡d-dcos,如果Docker容器使用CNI获取IP的容器都Attach到这个网卡上,而非docker0上。
每个机器上都会创建网卡m-dcos,如果mesos容器使用CNI获取IP的容器都Attach到这个网卡上。
每台机器的d-dcos和m-dcos的网段都不同。
每台机器都会创建一个vtep1024的网卡,作为VTEP,背后是vxlan。
每台机器都会创建默认的路由表,从本节点连接到其他的节点默认走vtep1024这个网卡。
在Mesos的配置的环境变量中,有以下的配置
MESOS_NETWORK_CNI_CONFIG_DIR=/opt/mesosphere/etc/dcos/network/cni
MESOS_NETWORK_CNI_PLUGINS_DIR=/opt/mesosphere/active/cni/
在路径/opt/mesosphere/etc/dcos/network/cni有对于DC/OS的网络的配置dcos.cni
- {"name":"dcos","type":"bridge","bridge":"m-dcos","isGateway":true,"ipMasq":false,"mtu":1420,"ipam":{"type":"host-local","subnet":"9.0.2.0\\/25","routes":[{"dst":"0.0.0.0\\/0"}]}}
这个配置文件是一个经典的CNI的配置文件,对于CNI的文档可以参考https://github.com/containernetworking/cni
如果要创建一个使用CNI的网络的容器可以使用如下的Json
- {
- "id":"nginxmesos",
- "cmd":"env; ip -o addr; sleep 3600",
- "cpus":0.10,
- "mem":512,
- "instances":1,
- "ipAddress":{
- "networkName":"dcos"
- },
- "container":{
- "type":"MESOS",
- "docker":{
- "network":"USER",
- "image":"nginx",
- }
- }
- }
当容器创建完毕之后,会调用network/cni的isolator,它会发现你指定的网络为"dcos",就会根据上面的dcos.cni的模板文件生成一个配置文件,然后定义一些CNI配置所需要的环境变量
- environment["CNI_COMMAND"] = "ADD";
- environment["CNI_CONTAINERID"] = containerId.value();
- environment["CNI_PATH"] = pluginDir.get();
- environment["CNI_IFNAME"] = containerNetwork.ifName;
- environment["CNI_NETNS"] = netNsHandle;
由于配置文件中的type为"bridge",因而调用plugin目录下面的bridge命令进行配置,bridge是用GO实现的,主要做以下的事情:
- 如果没有网桥则创建网桥ensureBridge
- 获取容器所在的namespace
- 配置veth pair,一个在namespace里面,一个在namespace外面,外面的网卡添加到网桥上
- 调用IPAM来配置容器的IP地址,由于配置文件中类型为host-local,调用host-local命令
- 配置网关和路由
五、DC/OS的存储功能
DC/OS的存储的管理主要分三种方式:本地临时存储(Local ephemeral storage),本地持久化存储(Local persistent volumes),外部持久化存储(External persistent volumes)。
第一种是存储方式,任务往往是无状态的,当一个任务在某台机器挂掉的时候,随时可以从另外一台机器上启动起来,当然原来机器上的数据也不会拷贝到新的机器上,启动的任务是全新的。
然而对于数据库之类的应用,使用第一种方式显然不合适,被调度到另外节点的数据库进程无法访问原来的数据,变成了空的数据库。
第二种方式可以部分解决有状态的服务的问题。
在创建服务的时候,指定持久化的存储路径
- {
- "containerPath": "data",
- "mode": "RW",
- "persistent": {
- "size": 500
- }
- }
这个data路径会创建在容器里面/mnt/mesos/sandbox下面,这个路径会对应于物理机器上的一个路径。在创建服务的时候,所有的服务的资源,包含CPU,内存,硬盘都被预留reserved,从而当这个服务挂掉的时候,还是会从同样的机器上启动起来,容器内部的/mnt/mesos/sandbox路径还是会被mount为相同的主机路径,所以在容器里面还是能够看到data这个目录,数据原封不动的放在那里。哪怕某个服务scale为0,资源还是被预留,从而再scale为1的时候,还是可以使用原来的路径,直到服务被terminate才不再预留。
然而当一台服务器挂掉的时候,服务会永远部署不成功,数据也就永远丢掉了。
第三种方式称为外部持久化存储,也就是说容器mount的路径不再是本地的路径,而是外部的统一存储,例如Ceph,GlusterFS,Amazon EBS,OpenStack Cinder等,这些外部存储都有自己的高可用机制,而且当容器在一台机器上挂了之后,可以将对于的存储数据的路径从这台机器上umount,然后在新的机器上mount,从而数据永远丢不了,即便服务器挂了,数据也是在的。
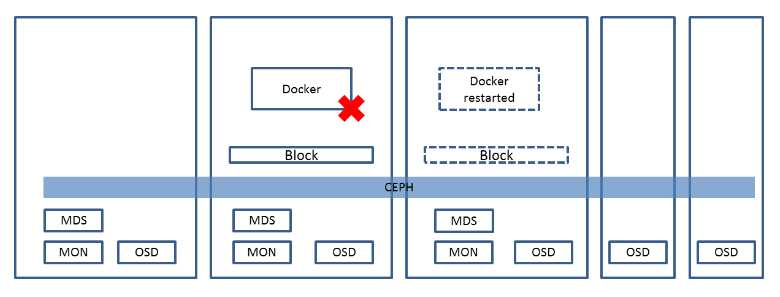
对于Docker,可以通过Docker Volume Plugin来做这件事情。
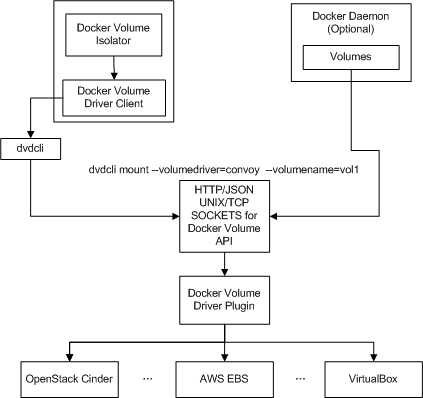
对于Mesos容器,则需要通过Docker Volume Isolator来实现,因而需要加载docker/volume。它通过执行dvdcli调用Docker Volume Plugin的API来创建volume。
- "container": {
- "type": "MESOS",
- "volumes": [
- {
- "containerPath": "test-rexray-volume",
- "external": {
- "size": 100,
- "name": "my-test-vol",
- "provider": "dvdi",
- "options": { "dvdi/driver": "rexray" }
- },
- "mode": "RW"
- }
- ]
- }
可以通过上面的json使用rexray来创建AWS EBS的volume作为外部存储。
六、DC/OS的服务发现与负载均衡功能
方式一:Mesos-DNS和marathon-lb
只有有了服务发现和负载均衡功能,才能使得服务的物理布局,服务之间的依赖关系,服务挂掉之后的自动修复不需要用户关心,才能使得用户像用一台电脑一样使用整个数据中心。
如果服务之间的相互调用不使用IP地址,而使用域名的话,问题会简单很多。
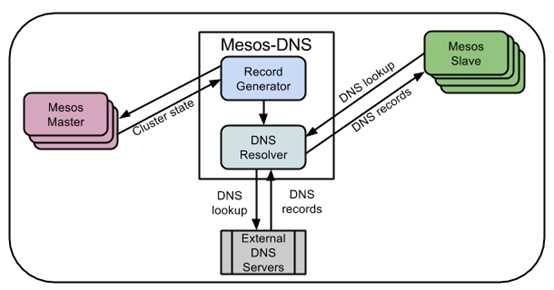
对于Mesos上运行的每一个Task,Mesos-DNS都可以通过调用Mesos-Master的API得到,并且为每个Task分配一个域名和IP的对应项。如果一个Task需要访问另一个Task,则需要配置域名即可,无论Task如何挂掉,如何分配到其他的节点上运行,域名都不会变,当然Task的IP可能会变,但是不用担心,Mesos-DNS会更新它。
servicePort为10000则说明我们注册到marathon-lb上的外部端口为10000, labels里面写的是external,也即注册到外部的负载均衡器上。
访问public slave上的10000端口,就能看到启动的nginx的页面http://54.254.148.129:10000/,内部其他的应用可以通过http://marathon-lb.marathon.mesos:10000来访问这个nginx
Minuteman是一个内部的东西向的负载均衡器,可用于设置VIP,多个实例使用同一个VIP来进行负载均衡。
当服务创建好了之后,通过curl http://nginxdocker.marathon.l4lb.thisdcos.directory:80就可以访问这个服务,但是我们如果ping这个域名却是不通的,而且对于的IP地址也是很奇怪的IP地址,这个IP就是VIP.
minuteman的load balancer是基于Netfilter的,在dcos的slave节点上,我们能看到多出来了四个iptables规则。其中前两个规则是在raw表里面的,后两个规则是在filter表里面的。
- -A PREROUTING -p tcp -m set --match-set minuteman dst,dst -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j NFQUEUE --queue-balance 50:58
- -A OUTPUT -p tcp -m set --match-set minuteman dst,dst -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j NFQUEUE --queue-balance 50:58
- -A FORWARD -p tcp -m set --match-set minuteman dst,dst -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j REJECT --reject-with icmp-port-unreachable
- -A OUTPUT -p tcp -m set --match-set minuteman dst,dst -m tcp --tcp-flags FIN,SYN,RST,ACK SYN -j REJECT --reject-with icmp-port-unreachable
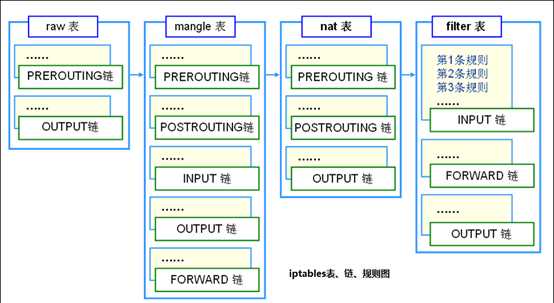
根据iptbles的规则raw表中的规则会被先执行,一旦到达了filter表的minuteman的包就都过滤掉了。
NFQUEUE的规则表示将对于包的处理权交给用户态的一个进程。--queue-balance表示会将包发给几个queue,然后用户态进程会使用libnetfilter_queue连接到这些queue中,将包读出来,根据包的内容做决策后放回内核进行发送。
在每一个Mesos-Agent节点上都运行这一个minuteman的进程,监听这些queue,我们可以通过访问API查看VIP的映射关系,curl http://localhost:61421/vips。
以上是关于深入解读DC/OS核心功能的主要内容,如果未能解决你的问题,请参考以下文章
深入解析DC/OS 1.8 – 高可靠的微服务及大数据管理平台