并查集的简介
Posted Excaliburer`s Zone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并查集的简介相关的知识,希望对你有一定的参考价值。
最近做题用到了并查集索性就把自己所掌握的相关知识总结一下。
并查集(union-find sets),CLRS上称为disjoint-set,是一组不相交的动态集合S1,S2,....Sk。它能够实现较快的合并和判断元素所在集合的操作,应用比较广泛,如其求无向图的连通分量个数,利用Kruskar算法求最小生成树等。它的主要操作为分为三部分:
1.初始化集合,Make_set()。即将数组中每个元素单独划分成一个个集合,也就是每个元素的祖先节点(和父亲节点)是它本身。假设数组P用来存所有节点,则可表示如下:
for(int i = 0; i < size; i++)
p[i] = i; //其中p[i] = m 表示元素i的父亲节点为m
2.对不同集合进行合并,Union(x,y)。将包含元素x和元素y的两个集合合并成一个集合实,质是对于x和y的祖先节点不是同一节点,把y的祖先点变成x的祖先节点,这样x,y的祖先节点就相同了;(含y的树就变成含x的树的一颗子树了)x,y就属于同一集合了。可表示如下:
void Union(int x,int y)
{
int px = Find(x),py = Find(y);
if(px != py)
{
p[py]=px; //吧
}
}
3.查找元素所在的集合,Find(x)。返回元素x所在的集合,实质是找到x的祖先节点。可表示如下:
int Find (int x)//实质是找到x的祖先节点
{
int r = x;
while(p[r] != r) //通过不停迭代来找到x的祖先节点
r = p[r];
return r;
}
以上是并查集最基本的应用,然而实际问题中,需要对并查集的几种操作进行优化。
1.对Find(x)的优化。
由于Find(x)是找到x的祖先节点,寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find(x)都是O(n)的复杂度,此时Find函数的性能比较差。
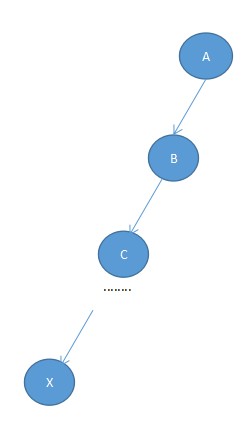
此时,可考虑"路径压缩"的方法,来减少查找次数。即经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Findt(x)时复杂度就变成O(1)了,所以树的结构变成如下的形式:
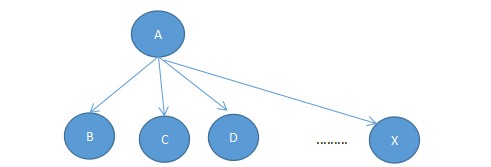
其具体操作如下:
int Find(int x)//返回x的祖先节点
{
if (x != p[x])
{
p[x] = Find(p[x]); //回溯进行路径压缩,此处用的递归实现,递归便于理解;当然也可以用迭代实现;
}
return p[x];
}
2.对Union(x,y)的优化。
在上面对Union(x,y)的实现中,每当px!=py时,就让y的祖先节点指向x的祖先节点,如果含y的树的高度大于含x树的高度的话,整棵树就变成了一颗高度更大的树了。树的高度增加,必然带来性能的下降,find函数效率下降。所以我们应该考虑树的大小,然后再来决定到底是调用:
p[py] = px 或者是 p[px] = py.
于是现在的问题就变成了:树的大小该如何确定?(此时树的大小称为秩)
可以通过设定一个数组s来存树的大小,在初始情况下,每个组的大小都是1,因为只含有一个节点,对该数组的初始化也很直观:
for (int i = 0; i < size; i++)
s[i] = 1; // 初始情况下,每个组的大小都是1
所以初始化函数Make_set()应变为:
void Make_Set()
{
for (int i = 0; i < size; i++)
{
p[i] = i; //初始化集合
s[i] = 1; //初始化树的代销
}
}
而在进行合并的时候,会首先判断待合并的两棵树的大小,然后按照上面的思想进行合并,此时Union(x,y)又称为按秩合并,其实现代码如下:
void Union(int x, int y)
{
int px = Find(x);
int py = Find(y);
if (px == py)
return;
if (sz[px] < sz[py]) // 将小树作为大树的子树
{ p[px] = py;
s[py] += s[px];
}
else {
p[py] = px;
s[px] += s[py];
}
}
至此,并查集的相关内容介绍完毕。此外,分享一个有趣的相关介绍:http://blog.csdn.net/dellaserss/article/details/7724401/
参考:1.http://www.ahathinking.com/archives/10.html
2.http://blog.csdn.net/dm_vincent/article/details/7655764
以上是关于并查集的简介的主要内容,如果未能解决你的问题,请参考以下文章