kafka-0.10.0官网翻译入门指南
Posted 找工作中,欢迎各行业大佬捞我简历 ---著有:《深入理解Fl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka-0.10.0官网翻译入门指南相关的知识,希望对你有一定的参考价值。
1.1 Introduction
Kafka is a distributed streaming platform. What exactly does that mean?
kafka是一个分布式的流式平台,它到底是什么意思?
We think of a streaming platform as having three key capabilities:
我们认为流式平台有以下三个主要的功能:
It
let‘s you publish and subscribe to streams of records. In this respect
it is similar to a message queue or enterprise messaging system.
它能让你推送和订阅流记录。在这个方面它类似于一个消息队列或者企业级的消息系统。
It let‘s you store streams of records in a fault-tolerant way.
它能让你存储流记录以一种容错的方式。
It let‘s you process streams of records as they occur.
它让你处理流记录当流数据来到时。
What is Kafka good for?
kafka有什么好处?
It gets used for two broad classes of application:
它被用于两大类别的应用程序:
Building real-time streaming data pipelines that reliably get data between systems or applications
建立实时的流式数据通道,这个通道能可靠的获取到在系统或应用间的数据
Building real-time streaming applications that transform or react to the streams of data
建立实时流媒体应用来转换流数据或对流数据做出反应。
To understand how Kafka does these things, let‘s dive in and explore Kafka‘s capabilities from the bottom up.
为了明白kafka能怎么做这些事情,让我们从下面开始深入探索kafka的功能:
First a few concepts:
首先看这几个概念:
Kafka is run as a cluster on one or more servers.
kafka作为集群运行在一个或多个服务器。
The Kafka cluster stores streams of records in categories called topics.
kafka集群存储的流记录以类别划分称为主题。
Each record consists of a key, a value, and a timestamp.
每条记录包含一个键,一个值和一个时间戳。
Kafka has four core APIs:
kafka有四个核心的apis:
The Producer API allows an application to publish a stream records to one or more Kafka topics.
生成者api允许一个应用去推送一个流记录到一个或多个kafka主题上。
The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
消费者api允许一个应用去订阅一个或多个主题,对他们产生过程的记录。
The
Streams API allows an application to act as a stream processor,
consuming an input stream from one or more topics and producing an
output stream to one or more output topics, effectively transforming the
input streams to output streams.
这个Streams API允许应用去作为一个流处理器,消费一个来至于一个或多个主题的输入流,生产一个输出流到一个或多个输出流主题,有效地将输入流转换为输出流。
The
Connector API allows building and running reusable producers or
consumers that connect Kafka topics to existing applications or data
systems. For example, a connector to a relational database might capture
every change to
Connector API允许建立和允许可重用的生产者或消费者去连接kafka主题到存在的应用或数据系统。例如,关系数据库的连接器可能捕获每一个变化。
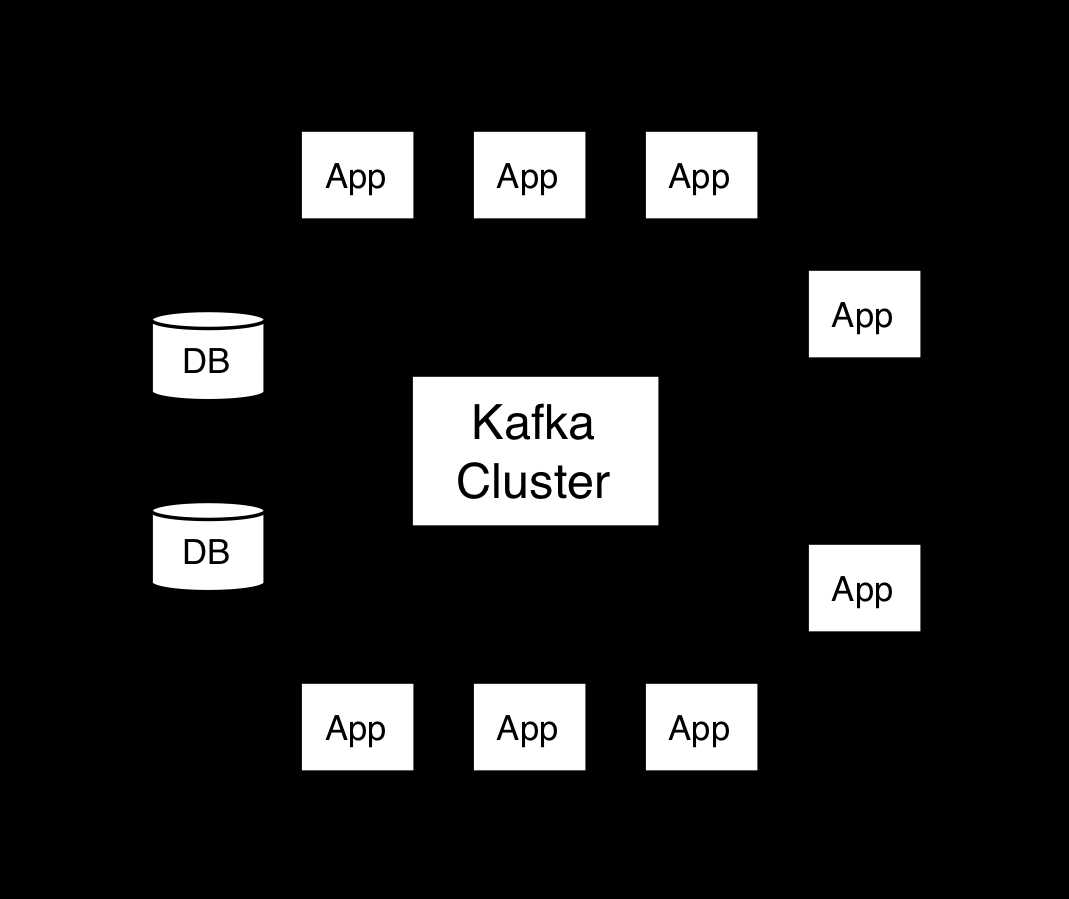
In
Kafka the communication between the clients and the servers is done
with a simple, high-performance, language agnostic TCP protocol. This
protocol is versioned and maintains backwards compatibility with older
version. We provide a Java client for Kafka, but clients are available
in many languages.
在kafka的客户和服务器之间的通信是用一个简单的,高性能的,语言无关的TCP协议完成的。这个协议的版本能向后维护来兼容旧版本。我们为kafka提供一个java版本的客户端,其实这个客户端有很多语言版本供选择。
Topics and Logs 主题和日志
Let‘s first dive into the core abstraction Kafka provides for a stream of records—the topic.
我们首先深入kafka核心概念,kafka提供了一连串的记录称为主题。
A
topic is a category or feed name to which records are published. Topics
in Kafka are always multi-subscriber; that is, a topic can have zero,
one, or many consumers that subscribe to the data written to it.
主题就是一个类别或者命名哪些记录会被推送走。kafka中的主题总是有多个订阅者。所以,一个主题可以有零个,一个或多个消费者去订阅写到这个主题里面的数据。
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
针对每一个主题,这个kafka集群维护一个像下面这样的分区日志: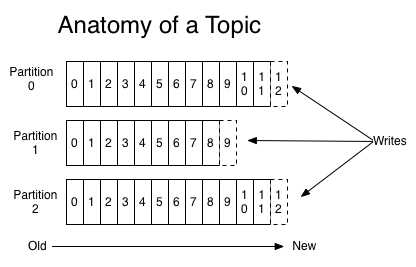
Each
partition is an ordered, immutable sequence of records that is
continually appended to—a structured commit log. The records in the
partitions are each assigned a sequential id number called the offset
that uniquely identifies each record within the partition.
每个分区是一个有序,不变的序列的记录,它被不断追加—这种结构化的操作日志。分区的记录都分配了一个连续的id号叫做偏移量。偏移量唯一的标识在分区的每一条记录。
The
Kafka cluster retains all published records—whether or not they have
been consumed—using a configurable retention period. For example if the
retention policy is set to two days, then for the two days after a
record is published, it is available for consumption, after which it
will be discarded to free up space. Kafka‘s performance is effectively
constant with respect to data size so storing data for a long time is
not a problem.
kafka集群使用一个可配置的保存期来保存所以已经推送出去的记录,不论他们是否已经被消费掉。例如,如果保存的策略设置为两天,然后记录被推送出去两天后,这个记录可以消费,之后,它将被丢弃来腾出空间。kafka的性能是有效常数对数据大小所以存储数据很长一段时间不是一个问题。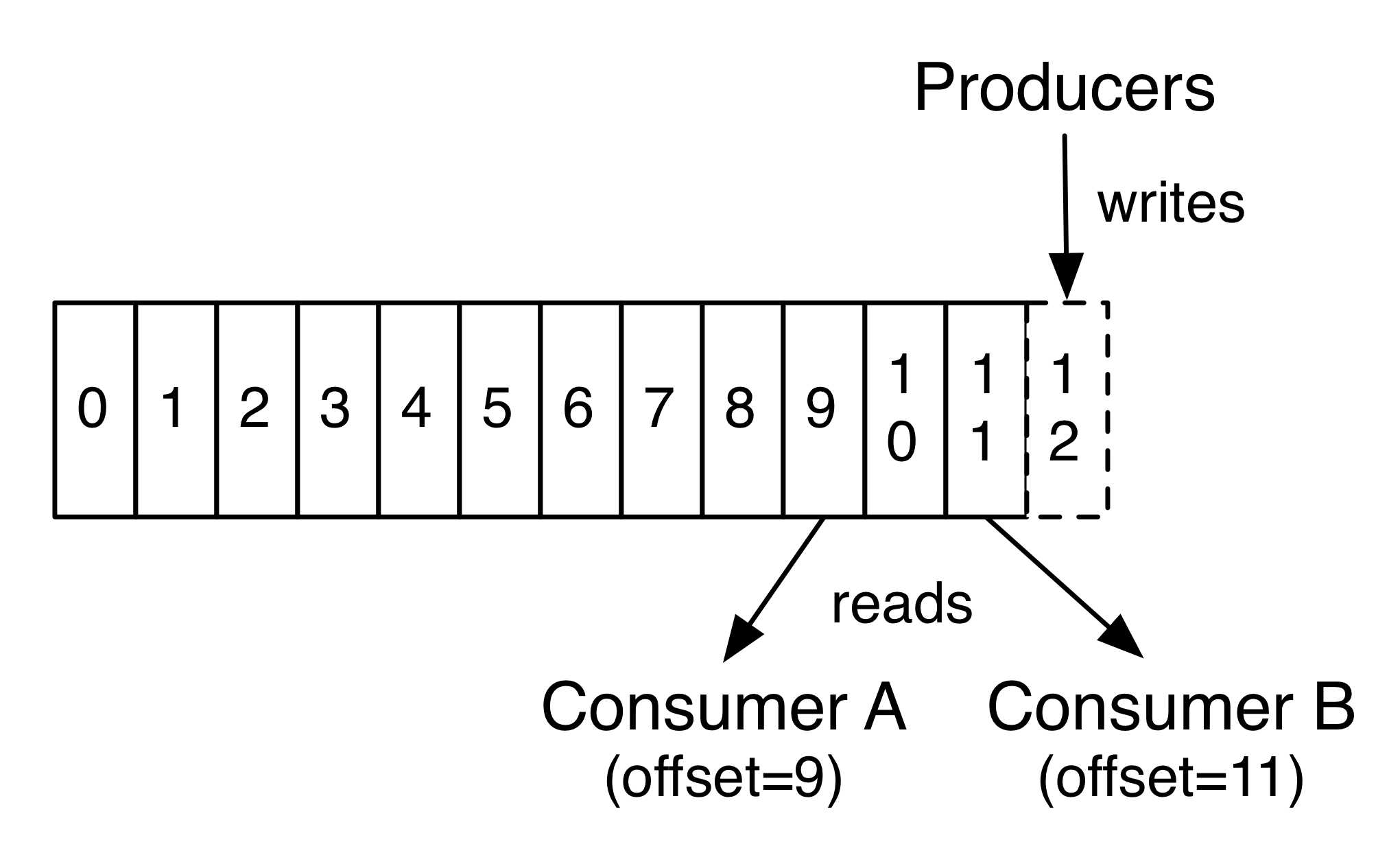
In
fact, the only metadata retained on a per-consumer basis is the offset
or position of that consumer in the log. This offset is controlled by
the consumer: normally a consumer will advance its offset linearly as it
reads records, but, in fact, since the position is controlled by the
consumer it can consume records in any order it likes. For example a
consumer can reset to an older offset to reprocess data from the past or
skip ahead to the most recent record and start consuming from "now".
事实上,唯一的元数据保留在每个消费者的基础上
偏移量是通过消费者进行控制:通常当消费者读取一个记录后会线性的增加他的偏移量。但是,事实上,自从记录的位移由消费者控制后,消费者可以在任何顺序消费记录。例如,一个消费者可以重新设置偏移量为之前使用的偏移量来重新处理数据或者跳到最近的记录开始消费。
This
combination of features means that Kafka consumers are very cheap—they
can come and go without much impact on the cluster or on other
consumers. For example, you can use our command line tools to "tail" the
contents of any topic without changing what is consumed by any existing
consumers.
kafka的组合特性意味着kafka消费者们是很方便的,他们能够加入或者离开不会影响集群或者其他的消费者。例如,你能够使用我们的命令行工具去追踪任何主题的内容不改变消费被任何存在的消费者。
The
partitions in the log serve several purposes. First, they allow the log
to scale beyond a size that will fit on a single server. Each
individual partition must fit on the servers that host it, but a topic
may have many partitions so it can handle an arbitrary amount of data.
Second they act as the unit of parallelism—more on that in a bit.
日志划分分区有多个目的。第一:他们允许日志的大小可以超过他们部署在一台单机的限制。每个分区的服务器主机上必须适合它。
Distribution
分布
The
partitions of the log are distributed over the servers in the Kafka
cluster with each server handling data and requests for a share of the
partitions. Each partition is replicated across a configurable number of
servers for fault tolerance.
日志的分区被分布在kafka集群的服务器上,每个服务器处理数据和请求一个共享的分区。每个分区复制在一个可配置的容错服务器数量。
Each
partition has one server which acts as the "leader" and zero or more
servers which act as "followers". The leader handles all read and write
requests for the partition while the followers passively replicate the
leader. If the leader fails, one of the followers will automatically
become the new leader. Each server acts as a leader for some of its
partitions and a follower for others so load is well balanced within the
cluster.
每个分区都有一个服务器充当“领导者”和零个或多个服务器充当“追随者”。leader处理所有对分区读写请求时followers就会被动复制这个leader的分区。如果这个leader发送故障,这些followers中的一个将自动的成为一个新的leader。Each
server acts as a leader for some of its partitions and a follower for
others so load is well balanced within the cluster.
Producers
生产者
Producers
publish data to the topics of their choice. The producer is responsible
for choosing which record to assign to which partition within the
topic. This can be done in a round-robin fashion simply to balance load
or it can be done according to some semantic partition function (say
based on some key in the record). More on the use of partitioning in a
second!
生产者推送数据到他们选择的主题。生产者负责选择哪个记录分配到指定主题的哪个分区中。通过循环的方式可以简单地来平衡负载记录到分区上或可以根据一些语义分区函数来确定记录到哪个分区上(根据记录的key进行划分)。马上你会看到关于更多的划分使用。
Consumers
消费者
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
消费者们标识他们自己通过消费组名称,每一条被推送到主题的记录只被交付给订阅该主题的每一个消费组。消费者可以在单独的实例流程或在不同的机器上。
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
如果所有的消费者实例都在同一个消费组中,那么一条消息将会有效地负载平衡给这些消费者实例。
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
如果所有的消费者实例在不同的消费组中,那么每一条消息将会被广播给所有的消费者处理。
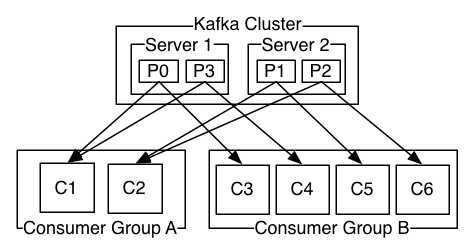
A
two server Kafka cluster hosting four partitions (P0-P3) with two
consumer groups. Consumer group A has two consumer instances and group B
has four.
两个服务器的kafka集群管理四个分区(P0-P3)作用于两个消费者组。消费组A有两个消费者实例,消费组B有四个消费者实例。
More
commonly, however, we have found that topics have a small number of
consumer groups, one for each "logical subscriber". Each group is
composed of many consumer instances for scalability and fault tolerance.
This is nothing more than publish-subscribe semantics where the
subscriber is a cluster of consumers instead of a single process.
更常见的,我们发现主题有一个小数量的消费群体one for each "logical subscriber"。
The
way consumption is implemented in Kafka is by dividing up the
partitions in the log over the consumer instances so that each instance
is the exclusive consumer of a "fair share" of partitions at any point
in time. This process of maintaining membership in the group is handled
by the Kafka protocol dynamically. If new instances join the group they
will take over some partitions from other members of the group; if an
instance dies, its partitions will be distributed to the remaining
instances.
Kafka only provides a total order over records
within a partition, not between different partitions in a topic.
Per-partition ordering combined with the ability to partition data by
key is sufficient for most applications. However, if you require a total
order over records this can be achieved with a topic that has only one
partition, though this will mean only one consumer process per consumer
group.
Guarantees
保证
At a high-level Kafka gives the following guarantees:
kafka的高级api可以赋予以下保证:
Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a record M1 is sent by the same producer as a record M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
消息被生产者发送到一个特定的主题分区,消息将以发送的顺序追加到这个分区上面。比如,如果M1和M2消息都被同一个消费者发送,M1先发送,M1的偏移量将比M2的小且更早出现在日志上面。
A consumer instance sees records in the order they are stored in the log.
一个消费者实例按照记录存储在日志上的顺序读取。
For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any records committed to the log.
一个主题的副本数是N,我们可以容忍N-1个服务器发生故障没而不会丢失任何提交到日志中的记录。
More details on these guarantees are given in the design section of the documentation.
关于担保的更多的细节将在文档的设计章节被给出来。
以上是关于kafka-0.10.0官网翻译入门指南的主要内容,如果未能解决你的问题,请参考以下文章