词法分析实验报告
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析实验报告相关的知识,希望对你有一定的参考价值。
|
实验一、词法分析实验
专业:商业软件工程 姓名:陈蔓嘉 学号:201506110245
一、 实验目的
编制一个词法分析程序。
二、 实验内容和要求
输入:源程序字符串
输出:二元组(种别,单词本身)
内容及要求:
1.对字符串表示的源程序
2.从左到右进行扫描和分解
3.根据词法规则
4.识别出一个一个具有独立意义的单词符号
5.以供语法分析之用
三、 实验方法、步骤及结果测试
实验方法:
- 1. 源程序名:压缩包文件(rar或zip)
- 2. 源程序名:词法分析程序.c
- 3. 可执行程序名:词法分析程序.exe
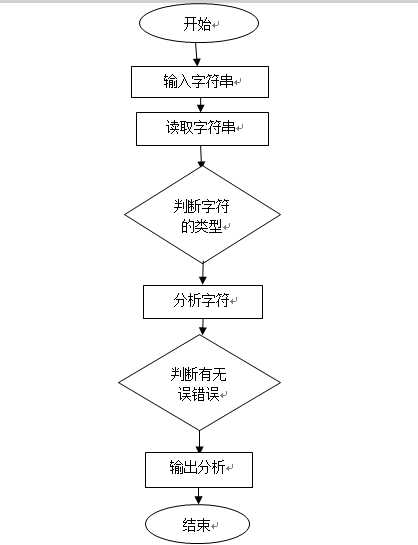
- 4. 原理分析及流程图
主要总体设计问题。(包括存储结构,主要算法,关键函数的实现等)
主函数主要算法:
do{
scanf("%c",&ch);
A[p]=ch;
p++;
}while(ch!=‘@‘);/*将输入的语句分别存入数组A[]中,@出现时结束语句*/
do
{
scaner();//进入函数进行判定
switch(syn)
{
case 11: printf("(%d,%d)\\n",syn,sum); break;//如果是11,那么就是数字
case -2: row=row++;break;
default: printf("(%d,%s)\\n",syn,TOken);break;//否则,就是变量名、关键词
}
}while (syn!=0);
流程图:
关键函数:
void scaner()/*分别对标示符、数字、符号进行分析*/
{
for(n=0;n<5;n++)
TOken[n]=0;/*每次循环完就清零*/
ch=A[i];
while(ch==‘ ‘||ch==‘\\n‘)/*如果字符是空格或者回车,跳过*/
{
i++;
ch=A[i];
}
if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘)) /*如果是标示符或者变量名,循环寻找*/
{
m=0;
while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))/*找到一个变量名或者关键字,直到遇到空格为止*/
{
TOken[m]=ch;m++;
i++;ch=A[i];
}
TOken[m]=‘\\0‘;/*将识别出来的字符和已定义的标示符作比较,输出其种别码*/
if(strcmp(TOken,r1)==0){syn=1;}
else if(strcmp(TOken,r2)==0){syn=2;}
else if(strcmp(TOken,r3)==0){syn=3;}
else if(strcmp(TOken,r4)==0){syn=4;}
else if(strcmp(TOken,r5)==0){syn=5;}
else if(strcmp(TOken,r6)==0){syn=6;}
else if(strcmp(TOken,r7)==0){syn=7;}
else if(strcmp(TOken,r8)==0){syn=8;}
else if(strcmp(TOken,r9)==0){syn=9;}
else{syn=10;}//从for开始到这里结束,是对标示符或者变量名的识别。
}
else if((ch>=‘0‘&&ch<=‘9‘)) //数字
{
sum=0;
while((ch>=‘0‘&&ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;//显示其对应数字sum
i++;
ch=A[i];
}
syn=11;
}//这一段是对数字三识别。
else switch(ch) //有两个的字符
{
case‘<‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=22;//<=
TOken[m]=ch;m++;i++;
}
else{syn=20;}break;//<
case‘>‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘){
syn=24;//>=
TOken[m]=ch;m++;i++;
}
else{syn=23;}break;//>
case‘:‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=32;//:=
TOken[m]=ch;m++;i++;
}
else
{syn=17;}break;//:
case‘@‘:syn=0;TOken[0]=ch;i++;break;
case‘=‘:syn=12;TOken[0]=ch;i++;break;
case‘+‘:syn=13;TOken[0]=ch;i++;break;
case‘-‘:syn=14;TOken[0]=ch;i++;break;
case‘*‘:syn=15;TOken[0]=ch;i++;break;
case‘/‘:syn=16;TOken[0]=ch;i++;break;
case‘{‘:syn=18;TOken[0]=ch;i++;break;
case‘}‘:syn=19;TOken[0]=ch;i++;break;
case‘(‘:syn=26;TOken[0]=ch;i++;break;
case‘)‘:syn=27;TOken[0]=ch;i++;break;
case‘;‘:syn=33;TOken[0]=ch;i++;break;
case‘.‘:syn=34;TOken[0]=ch;i++;break;
case‘\\n‘:syn=-2;break;
default: syn=-1;break;
}//这一部分是对符号的识别。
}
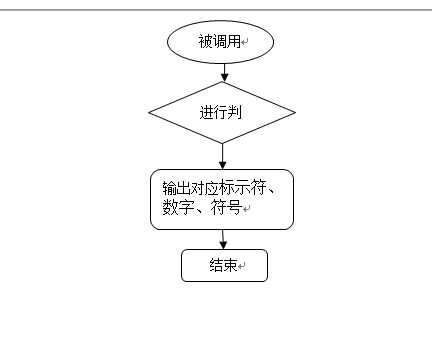
关键函数流程图:
- 5. 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
void scaner()/*分别对标示符、数字、符号进行分析*/
{
for(n=0;n<7;n++)
TOken[n]=0;/*每次循环完就清零*/
ch=A[i];
while(ch==‘ ‘||ch==‘\\n‘)/*如果字符是空格或者回车,跳过*/
{
i++;
ch=A[i];
}
if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘)) /*如果是标示符或者变量名,循环寻找*/
{
m=0;
while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))/*找到一个变量名或者关键字,直到遇到空格为止*/
{
TOken[m]=ch;m++;
i++;ch=A[i];
}
TOken[m]=‘\\0‘;/*将识别出来的字符和已定义的标示符作比较,输出其种别码*/
if(strcmp(TOken,r1)==0){syn=1;}
else if(strcmp(TOken,r2)==0){syn=2;}
else if(strcmp(TOken,r3)==0){syn=3;}
else if(strcmp(TOken,r4)==0){syn=4;}
else if(strcmp(TOken,r5)==0){syn=5;}
else if(strcmp(TOken,r6)==0){syn=6;}
else if(strcmp(TOken,r7)==0){syn=7;}
else if(strcmp(TOken,r8)==0){syn=8;}
else if(strcmp(TOken,r9)==0){syn=9;}
else{syn=10;}
}
else if((ch>=‘0‘&&ch<=‘9‘)) //数字
{
sum=0;
while((ch>=‘0‘&&ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;//显示其对应数字sum
i++;
ch=A[i];
}
syn=11;
}
else switch(ch) //有两个的字符
{
case‘<‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=22;//<=
TOken[m]=ch;m++;i++;
}
else{syn=20;}break;//<
case‘>‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘){
syn=24;//>=
TOken[m]=ch;m++;i++;
}
else{syn=23;}break;//>
case‘:‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=32;//:=
TOken[m]=ch;m++;i++;
}
else
{syn=17;}break;//:
case‘@‘:syn=0;TOken[0]=ch;i++;break;
case‘=‘:syn=12;TOken[0]=ch;i++;break;
case‘+‘:syn=13;TOken[0]=ch;i++;break;
case‘-‘:syn=14;TOken[0]=ch;i++;break;
case‘*‘:syn=15;TOken[0]=ch;i++;break;
case‘/‘:syn=16;TOken[0]=ch;i++;break;
case‘{‘:syn=18;TOken[0]=ch;i++;break;
case‘}‘:syn=19;TOken[0]=ch;i++;break;
case‘(‘:syn=26;TOken[0]=ch;i++;break;
case‘)‘:syn=27;TOken[0]=ch;i++;break;
case‘;‘:syn=33;TOken[0]=ch;i++;break;
case‘.‘:syn=34;TOken[0]=ch;i++;break;
case‘\\n‘:syn=-2;break;
default: syn=-1;break;
}
}
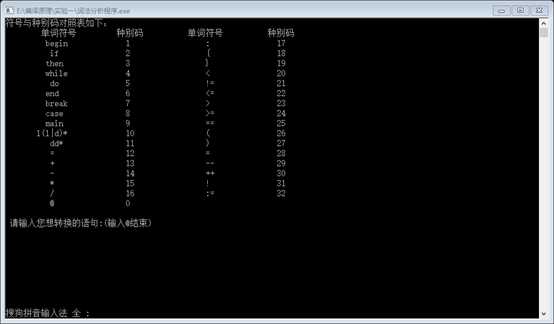
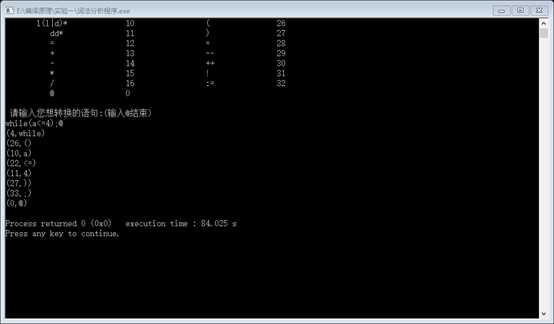
- 6. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)
四、 实验总结
心得体会,实验过程的难点问题及其解决的方法。
在写词法分析的过程中,难点问题主要是关键字和变量名的分辨,在循环程序中卡主了,其他问题还好。在分辨期间,我首先让这个词循环,查找,循环完就清零。如果是标示符或者变量名,找到一个变量名或者关键字,直到遇到空格为止,将识别出来的字符和已定义的标示符作比较,输出其种别码。这是我这一实验学到的最大的东西。
以上是关于词法分析实验报告的主要内容,如果未能解决你的问题,请参考以下文章