python课程第四周重点记录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python课程第四周重点记录相关的知识,希望对你有一定的参考价值。
1.迭代器
names = iter(["alex","jack","rain"]) #声明列表的一个迭代器 names.__next__() #迭代
2.生成器,使用yield后,函数变成一个generator,调用函数返回一个iterable对象
def cash_monkey(amount): while(amount>0): amount -= 100 print("取钱啦") yield amount atm = cash_monkey(500) print("还剩%s"%atm.__next__())#__next__()方法相当于执行一次函数,停在yield语句处返回yield相当于return print("还剩%s"%atm.__next__()) for i in cash_monkey(500): #for循环中自动调用__next__()方法 print(i) #在读取文件中使用 def read_file(fpath): BLOCK_SIZE =1024 with open(fpath, ‘rb‘) as f: while True: block =f.read(BLOCK_SIZE) if block: yield block else: return def h(): print(‘Wen Chuan‘) m = yield 5 # 接收了send传过来的Fighting! print(m) d = yield 12 print(‘We are together!‘) c = h() m = c.__next__() #m 获取了yield 5 的参数值 5 d = c.send(‘Fighting!‘) #d 获取了yield 12 的参数值12 print(‘We will never forget the date‘, m, ‘.‘, d)
3.二维数组
‘‘‘ [0,1,2,3] [0,1,2,3] [0,1,2,3] [0,1,2,3] ---------- [0,0,0,0] [1,1,1,1] [2,2,2,2] [3,3,3,3] ‘‘‘ data = [[col for col in range(4)] for row in range(4)] for i in range(len(data)): a = [data[i][i] for row in range(4)] print(a)
4.正则表达式
import re match = re.match(r‘dog‘, ‘dog cat dog‘) #匹配开始 match.group() #取得匹配上的元素 match = re.search(‘dog‘, ‘dog cat dog‘) #匹配任意位置,只匹配一次 match.group() match.start() #匹配上的元素的开始位置 match.end() #匹配上的元素的结束位置 match = re.findall(r‘dog‘, ‘dog cat dog‘) #所有匹配对象,得到的是一个列表 contactInfo = ‘Doe, John: 555-1212‘ match = re.search(r‘(\w+), (\w+): (\S+)‘, contactInfo) #分成3个子串 match.group(1) #Doe match.group(2) #John match.group(3) #555-1212 match.group(0) #匹配所有Doe, John: 555-1212
语法:
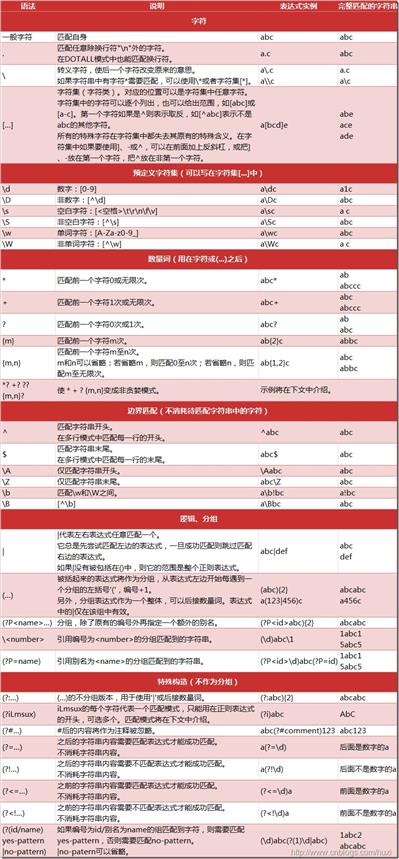
以上是关于python课程第四周重点记录的主要内容,如果未能解决你的问题,请参考以下文章