词法分析实验报告
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析实验报告相关的知识,希望对你有一定的参考价值。
实验一、词法分析器实验
专业:商软工程3班 姓名:林美全 学号:201506110220
一、 实验目的
设计,编制一个简单词法分析程序对输入字符串进行识别并做简单有效输出
从而加深对词法的理解。
二、 实验内容和要求
识别输入字符串中的关键词,标识符,数字,字母,分界符,并将其与其对应种别码进行输出。
三、 实验方法、步骤及结果测试
1.实验流程
(1) 输入字符串
(2) 调用void scaner(void) 识别字符
(3) 输出原字符及其对应的种别码
2.实验步骤及分析
(1)将 关键字表为一个字符串数组
Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};
(2)程序中数字,字母,字符对应种别码(空格及无效识别符号其种别码以-1表示)
void scaner(void)
{
sum=0;
for(m=0;m<8;m++)
token[m++]= NULL;
ch=prog[p++];
m=0;
while((ch==‘ ‘)||(ch==‘\\n‘))
ch=prog[p++];
if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘)))
{
while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘)))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>=‘0‘)&&(ch<=‘9‘))
{
while((ch>=‘0‘)&&(ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;
ch=prog[p++];
}
p--;
syn=11;
}
else
{
switch(ch)
{
case ‘<‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case ‘>‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case ‘+‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘+‘)
{
syn=17;
token[m++]=ch;
}
else
{
syn=13;
p--;
}
break;
case ‘-‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘-‘)
{
syn=29;
token[m++]=ch;
}
else
{
syn=14;
p--;
}
break;
case ‘!‘:
ch=prog[p++];
if(ch==‘=‘)
{
syn=21;
token[m++]=ch;
}
else
{
syn=31;
p--;
}
break;
case ‘=‘:
token[m++]=ch;
ch=prog[p++];
if(ch==‘=‘)
{
syn=25;
token[m++]=ch;
}
else
{
syn=18;
p--;
}
break;
case ‘*‘:
syn=15;
token[m++]=ch;
break;
case ‘/‘:
syn=16;
token[m++]=ch;
break;
case ‘(‘:
syn=27;
token[m++]=ch;
break;
case ‘)‘:
syn=28;
token[m++]=ch;
break;
case ‘{‘:
syn=5;
token[m++]=ch;
break;
case ‘}‘:
syn=6;
token[m++]=ch;
break;
case ‘;‘:
syn=26;
token[m++]=ch;
break;
case ‘\\"‘:
syn=30;
token[m++]=ch;
break;
case ‘#‘:
syn=0;
token[m++]=ch;
break;
case ‘:‘:
syn=17;
token[m++]=ch;
break;
default:
syn=-1;
break;
}
}
token[m++]=‘\\0‘;
}
3.结果测试
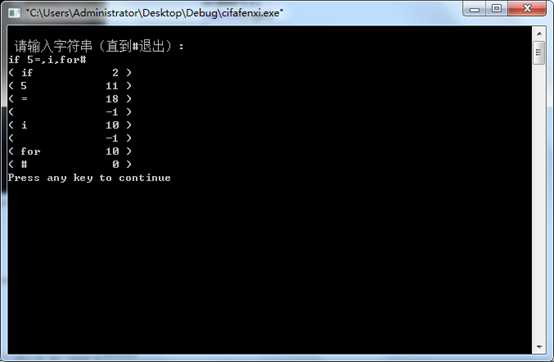
四、 实验总结
通过编译原理的这次程序实验,更加进一步地了解词法分析的过程。在实验中一些问题的解决上懂得对别人程序的借鉴总结和思考来处理问题。
以上是关于词法分析实验报告的主要内容,如果未能解决你的问题,请参考以下文章