Deep Residual Learning for Image Recognition(MSRA-深度残差学习)
Posted 静悟生慧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Residual Learning for Image Recognition(MSRA-深度残差学习)相关的知识,希望对你有一定的参考价值。
网络深度非常重要,但也存在一些问题:是否能够简单的通过增加更多的网络层次学习到更好的网络?解决这个问题的障碍之一是臭名昭著的所谓梯度消失(爆炸)问题[1, 9],这从根本上妨碍了网络收敛,虽然这个问题已被广泛讨论,并试图通过一些办法加以解决,包括通过规范初始化[23, 9, 37, 13]和引入中值规范化层[16]的方式使得多达几十层的利用随机梯度下降(SGD)方法使得反馈网络[22]的求解得以收敛。虽然这些较深的网络得以收敛,一个所谓的退化(degradation)问题也暴露了出来,即随着网络深度的增加,准确率(accuracy)增长的速率会很快达到饱和(这可能也并不奇怪)然后就很快的下降了。令人意外的是,此类退化问题并不是由于过拟合造成的,而且,对一个合适的深度网络模型增加更多的层次会使得训练误差更高,这曾被报告于[11, 42]并且也被我们的实验充分验证了,图1展示了一个典型的案例。
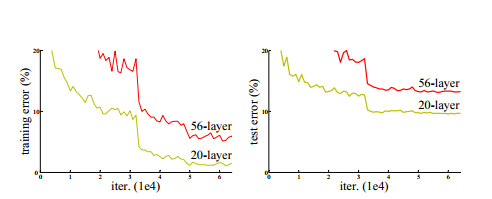
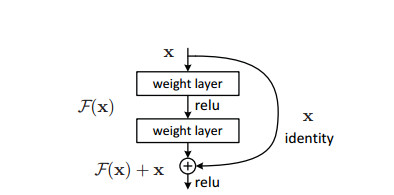
我们基于ImageNet数据集[36]进行详尽实验,演示了退化问题,并对我们提出的方法进行了评估。结果表明:1)我们提出的超深度残差网络更便于优化,而其所对应的平凡网络(即简单通过层次堆叠而成的网络)的训练误差却随着网络层次的加深而变大;2)我们所提出的深度残差网络更容易在增加深度时获得精度的提高,明显优于之前的网络结构所得到的结果。
类似的现象也可以通过对于CIFAR-10数据集[20]的实验看到,实验结果表明对网络寻优的难度和我们所提出的方法的效果并不局限于特定的数据集。我们对该数据集展示了对深度为100层网络的训练,尝试了深达1000层的网络。
对于ImageNet分类数据集[36],我们通过超深的残差网络获得了很好的结果。我们的152层残差网络是目前已知最深的应用于ImageNet数据集的网络,然而其复杂度却低于VGG网络[41]。我们的方法最终对ImageNet测试数据集的误差为3.57%,位列前五,并且获得了2015年ILSVRC分类比赛的第一名。超深度的表示对于其他的识别任务也有很好的泛化能力,这使得我们在2015年ILSVRC&COCO比赛中赢得了ImageNet物品检测、ImageNet地理定位、COCO物品检测和COCO图像分割的第一名。事实表明,残差学习方法是具有一般性的,我们也希望它能够被进一步应用于其他视觉和非视觉类问题的解决。
Related work:
在低级视觉和计算机图形学中,对偏微分方程(Partial Differential Equation, PDE)的求解,通常是用多重网格(Multigrid)法[3]对系统中多尺度的子问题重新建模,每个子问题负责求解出较粗粒度或较细粒度的残差。除多重网格法外,级联基预处理[45, 46]也被用于求解上述的偏微分方程,它是基于表示了两个尺度间残差的量来进行的。通过文献[3, 45, 46]可知这些求解方法比不考虑残差的求解方法能够更加快速的收敛。对这些方法的研究表明一个好的模型重构或预处理将有利于模型的优化。
捷径连接。捷径连接的相关工作所基于的实践和理论上[2, 34, 49]已经被研究了相当长时间。早期的关于训练多层感知器网络(MLP, multi-layer perceptrons)的实践包括通过在网络的输入层和输出层之间增加一个线性层[34,