第一节 深度学习前言
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一节 深度学习前言相关的知识,希望对你有一定的参考价值。
毫无疑问,神经网络在深度学习中扮演着极其重要的作用。可以毫不犹豫的说,深度学习就是各种各样的神经网络。俗话说工欲善其事必先利其器,如果想要掌握深度学习算法,神经网络的实现就必须要了解。所以,今天我们来了解并用Python实现出一个神经网络。
首先我们需要导入一个数据库,其代码如下:
- import numpy as np
- import sklearn
- import sklearn.datasets
- import matplotlib.pyplot as plt
- import sklearn.linear_model
- X,y = sklearn.datasets.make_moons(200,noise=0.2)
- plt.scatter(X[:,0],X[:,1],s=40,c=y,cmap=plt.cm.Spectral)
- plt.show()
运行代码可以看到数据库中数据的分布:
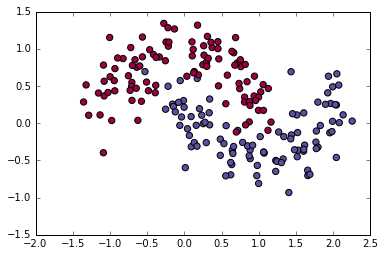
第一行:代码中的numpy是matlab的矩阵运算工具箱。Python在通过import命令加载numpy工具箱后就可以像matlab一样工作了。
第二行:sklearn是python下的一款超级强大的机器学习工具箱,从数据生成到预处理,再到特征提取和特征筛选,最后到机器学习算法,全方位无死角的为你的机器学习提供便利。里面的算法之全,种类之多令我这个在matlab界浪荡了5年的老梆子都赞叹不已。
第三行:导入sklearn中的数据集
第四行:导入python的绘图工具箱matplotlib。虽然sklearn比matlab的算法全多了,但是matplotlib和matlab相比,前者的渣画质我已无力吐槽。
第五行:导入sklearn的线性模型
第六行:通过make_moons函数生成数据集X,y,其中X是数据样本,y是数据样本对应的标签
make_moons的第一个参数200指定了生成数据点的个数;第二个参数指定了数据点所服从的高斯噪声的标准差,直观一点就是如下图
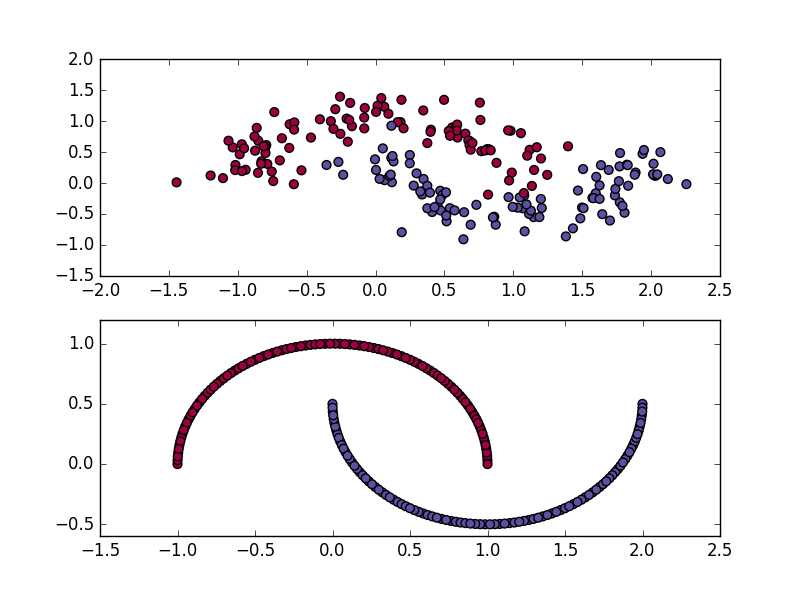
subplot(2,1,1)是噪声为0.2的数据(上部),subplot(2,1,2)是噪声为0的数据(下部)
第七行:scatter中的s是数据点的大小尺寸,c指明颜色,cmap是一个colormap示例
然后添加如下代码用于绘制Logistic Regression的分类器决策边界:
- def plot_decision_boundary(pred_func):
- x_min,x_max = X[:,0].min() - .5, X[:,0].max() + .5
- y_min,y_max = X[:,1].min() - .5, X[:,1].max() + .5
- h = 0.01
- xx,yy = np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
- Z = pred_func(np.c_[xx.ravel(),yy.ravel()])
- Z = Z.reshape(xx.shape)
- plt.contourf(xx,yy,Z,cmap = plt.cm.Spectral)
- plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.Spectral)
- clf = sklearn.linear_model.LogisticRegressionCV()
- clf.fit(X,y)
- plot_decision_boundary(lambda x: clf.predict(x))
- plt.title("Logistic Regression")
- plt.show()
第14行:生成一个LogisticRegressionCV对象
第15行:调用fit方法训练logisticRegression
第17行(超难句):这里面有两个难点:
lambda x: clf.predict(x)是什么?
lambda实际上是一种函数,当你想运行一个函数而又毫不关心他的函数名时,就可以叫他lambda。这个函数实际上可以写为
def call_clf_predict(x): return clf.predict(x)
plot_decision_boundary(call_clf_predict) lambda函数实际上和lambda演算相关,lambda演算就是尝试把函数当做数去使用。
第8行到底接受到了什么?
答案是第8行实际上接收到了一个方法(函数),这个方法被用pred_func进行了替换。那么这个方法又是谁呢?答案是lambda函数
lambda函数又是谁呢?答案是clf.predict(x)。所以pred_func实际上就是clf.predict(x)。
因此在调用环节,plot_decision_boundary(lambda x: clf.predict(x)) 等价于 plot_decision_boundary(clf.predict)
第1行:定义边界绘制函数plot_decision_boundary
第2~3行:扩展画幅
第4行:设定步长
第6行:通过meshgrid生成网格点
第8行:这是一个难句,我们先解释一下里面的一些陌生函数:
np.c_函数使矩阵按列组合例如
>>> a = array([1,2,3]);b=array([4 5 6])
>>> nc.c_(a,b)
array([1,4],
[2,5],
[3,6])
>>> nc.r_(a,b)
array([1 2 3 4 5 6])
reval()把矩阵按行拉成行向量,例如
>>> c = array([[1,2],[3,4]])
>>> c.ravel()
array([1,2,3,4])
pred_func实际上就是clf.predict,因此Z = pred_func(np.c_[xx.ravel(),yy.ravel()])可以等价于Z = clf.predict (np.c_[xx.ravel(),yy.ravel()])
第9行,把预测出来的Z重新按照xx和yy的形式排列成矩阵
第11行,contourf是等值线图
# Generate a dataset and plot it(x-algo.cn)
import numpy as np
import sklearn
import sklearn.datasets
import matplotlib.pyplot as plt
import sklearn.linear_model
# Helper function to plot a decision boundary.
# If you don‘t fully understand this function don‘t worry, it just generates the contour plot below.
def plot_decision_boundary(pred_func):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
# Helper function to evaluate the total loss on the dataset
def calculate_loss(model):
W1, b1, W2, b2 = model[‘W1‘], model[‘b1‘], model[‘W2‘], model[‘b2‘]
# Forward propagation to calculate our predictions
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Calculating the loss
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# Add regulatization term to loss (optional)
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss
# Helper function to predict an output (0 or 1)
def predict(model, x):
W1, b1, W2, b2 = model[‘W1‘], model[‘b1‘], model[‘W2‘], model[‘b2‘]
# Forward propagation
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
# This function learns parameters for the neural network and returns the model.
# - nn_hdim: Number of nodes in the hidden layer
# - num_passes: Number of passes through the training data for gradient descent
# - print_loss: If True, print the loss every 1000 iterations
def build_model(nn_hdim, num_passes=20000, print_loss=False):
# Initialize the parameters to random values. We need to learn these.
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# This is what we return at the end
model = {}
# Gradient descent. For each batch...
for i in xrange(0, num_passes):
# Forward propagation
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don‘t have regularization terms)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# Gradient descent parameter update
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# Assign new parameters to the model
model = { ‘W1‘: W1, ‘b1‘: b1, ‘W2‘: W2, ‘b2‘: b2}
# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don‘t want to do it too often.
if print_loss and i % 1000 == 0:
print "Loss after iteration %i: %f" %(i, calculate_loss(model))
return model
np.random.seed(0)
X, y = sklearn.datasets.make_moons(200, noise=0.20)
plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral)
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)
num_examples = len(X) # training set size
nn_input_dim = 2 # input layer dimensionality
nn_output_dim = 2 # output layer dimensionality
# Gradient descent parameters (I picked these by hand)
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strength
# Build a model with a 3-dimensional hidden layer
model = build_model(3, print_loss=True)
# Plot the decision boundary
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
plt.show()
解释:
第56行:build model函数用于建立模型
第59~63行:通过随机数初始化W1,W2,b1,b2
第66行:初始化model
第69行:采用批量梯度下降法进行训练
第72~76行:前馈阶段,该阶段以得到基于当前W1,W2,b1,b2 的预测结果为主
假定一个网络有一个inputsize为2的输入层;一个Hiddensize为5的隐藏层;一个outputsize为2的输出层,如下所示:
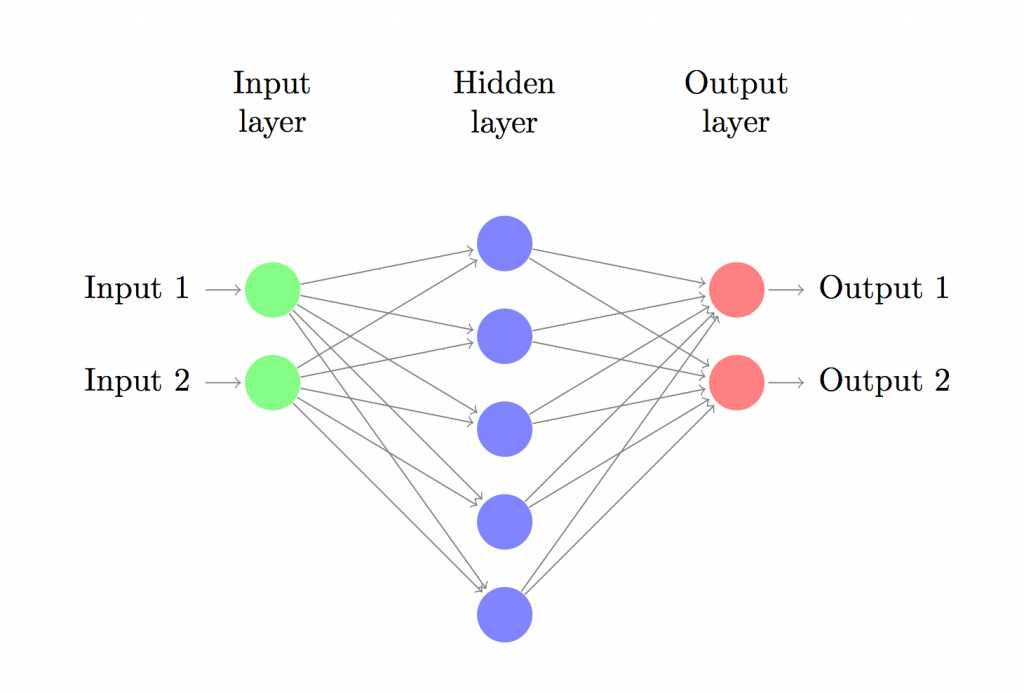
则可以肯定W1的大小为(2,5)【输入层size,隐层size】,b1大小为(1,5)【1,隐层size】
W2的大小为(5,2)【隐层size,输出层size】,b2大小为(1,2)【1,输出层size】
又假定样本集X大小为(200,2).
z1 = X(200,2)*W1(2,5)+b1(1,5) = (200,5) 注意最后一个加号是一行一行加的
a1 = tanh(z1) (200,5) 对每一个元素求tanh
z2 = a1(200,5)*W2(5,2)+b2(1,2) = (200,2) 注意最后一个加号是一行一行加的
exp_score = e^z2 (e是激活函数,exp_score仍然是(200,2))
probs是同一行的两个数的占比书,这里用了一个比较巧的办法:
比如你想比较6和4,这里采用的办法就是[6,4]/(6+4) =[0.6,0.4]
第79~85行:
先来看一段理论。一般而言,在机器学习中,首先要解决的就是模型的cost Function。在这个神经网络中,cost Function如下所示:
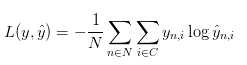
这个公式看起来比较复杂,他其实最终的意思就是统计一下有多少个预测标签ybar和y不太一样。其次要解决的就是梯度下降算法所应用的目标。在这里,分别需要用L对W1,W2,b1,b2求偏导数,结果如下所示:
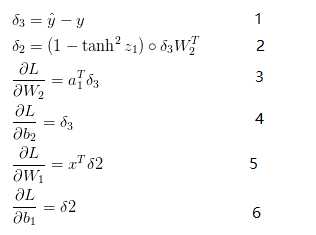
上方的最后四个式子就是L函数在W1,W2,b1,b2四个方向的梯度。
第79~80对应式(1),这里用了比较巧的一个编程方法,举个例子,假如有如下四个样本和标签
样本 标签
0,1 0
1,0 0
0,0 0
1,1 1
该程序实际上把标签集当作
样本 标签
0,1 0,1
1,0 0,1
0,0 0,1
1,1 1,0
如果直接将y写成上方标签的形式去计算实际上是在增加计算量,因为y要么是(1,0),要么是(0,1),ybar中的某个样本的一维减去0并不会发生变化,还不如直接把ybar中和y中对应为1的部分单独抽出相减,所以写为delta3[range(num_examples), y] -= 1
第81~82行实际上就是3式和4式。这里不再解释
82~85行同79~82行相同,请参见公式5~6自行解释
87~89行:是规约项,目的是使dW1和dW2尽量稀疏化。
91~95行:正经的梯度下降迭代公式,不懂请参见python机器学习实战
函数calculate_loss和predict的原理与上述的build_model原理相同,所以不再讲解。
以上是关于第一节 深度学习前言的主要内容,如果未能解决你的问题,请参考以下文章