决策树到集成学习
Posted 2BiTT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树到集成学习相关的知识,希望对你有一定的参考价值。
还是用上一篇文章的例子来阐述从单纯的决策树到集成学习的过程
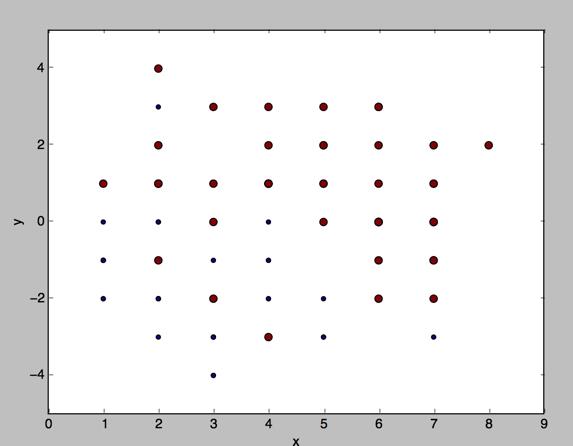
数据集还是100个数据点,分布如下(x,y坐标只保留一位小数)

决策树
简单的决策树的结果可能是这样的,这是一棵很可能极度过拟合的决策树。
决策树生成的逻辑大概是这样的:遍历每个特征的每个特征值,计算最优的特征以及特征值来分割训练集,
显然,我们的特征只有x,y坐标两个特征,但是每个特征的特征值太多了,导致这个决策树太“庞大”了;
还有另外一个问题,新来的数据可能没有出现在这个决策树的任何一个分支里,导致对于后来的数据根本没有办法做预测,更不要说预测对错的问题
这个决策树的错误率是0.01(也就是正确率99%),这是可以想象得到的,因为这棵决策树完全拟合了训练集,除了有一些坐标一样属于不同类别的点被“多数表决”(下面会说到)导致预测错误之外
剩下的点都是预测对的
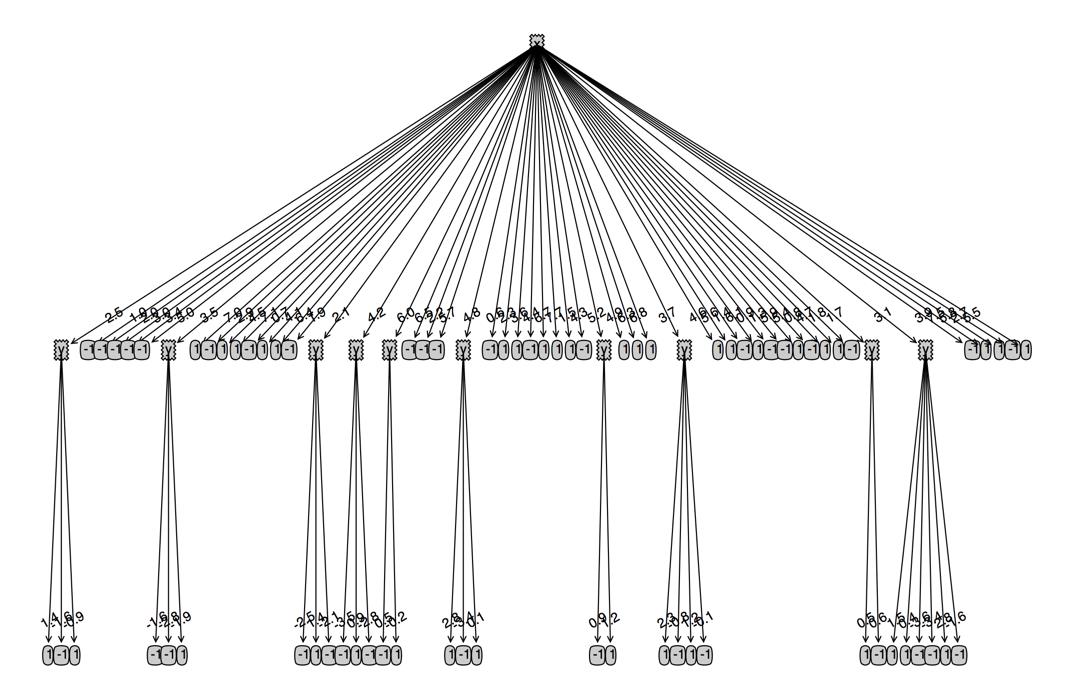
尝试把特征值减少一点,x,y坐标都取整数,看下效果如何:
这个看起来更清爽了,而且也是更加符合我们的预期的,因为y坐标出现在了根节点:正负样本的整体分布是沿y轴分布的
并且由于转换成了整数,虽然可能丢失了精度,但是提高了决策树的使用范围,除非新的数据点偏离训练集很远,否则都是能得出一个预测结果的。
下面这棵决策树的错误率是0.11,因为丢失了精度,更大的点出现了坐标一样,类别不一样的情况,导致更多的点因为多数表决的原因被预测错误。
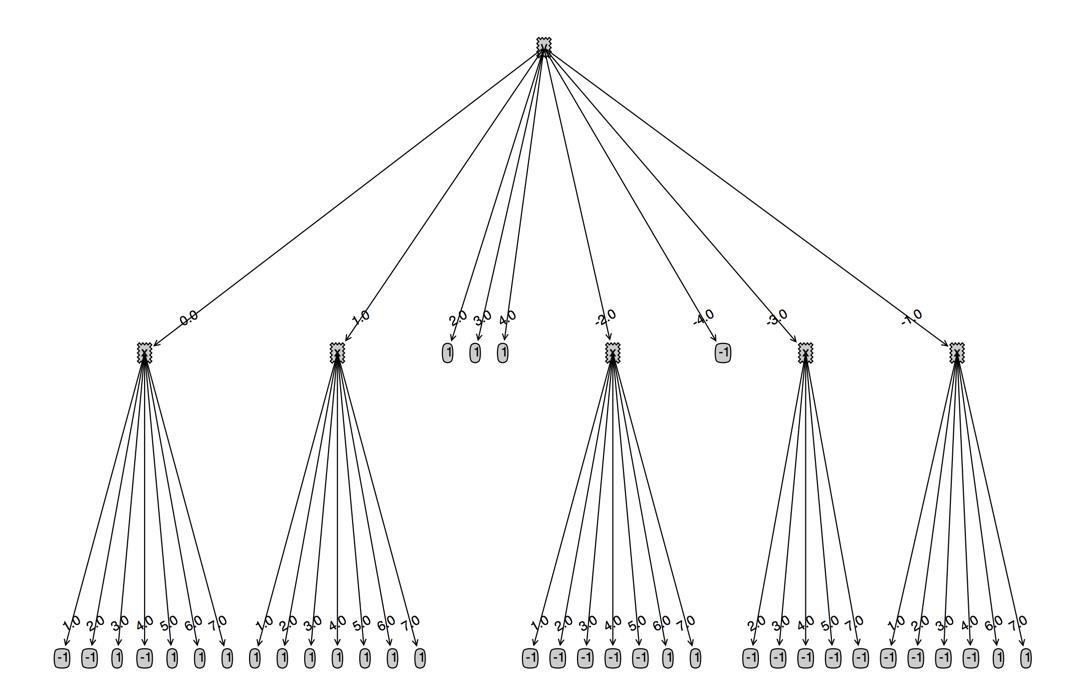
试图在样本集增加一行
3.0 3.0 -1
看下决策树的表现:可以发现,决策树在y=3的分支有了二级分支,但是所有的值都为1,可以知道,决策树的生成有个“多数表决”的过程
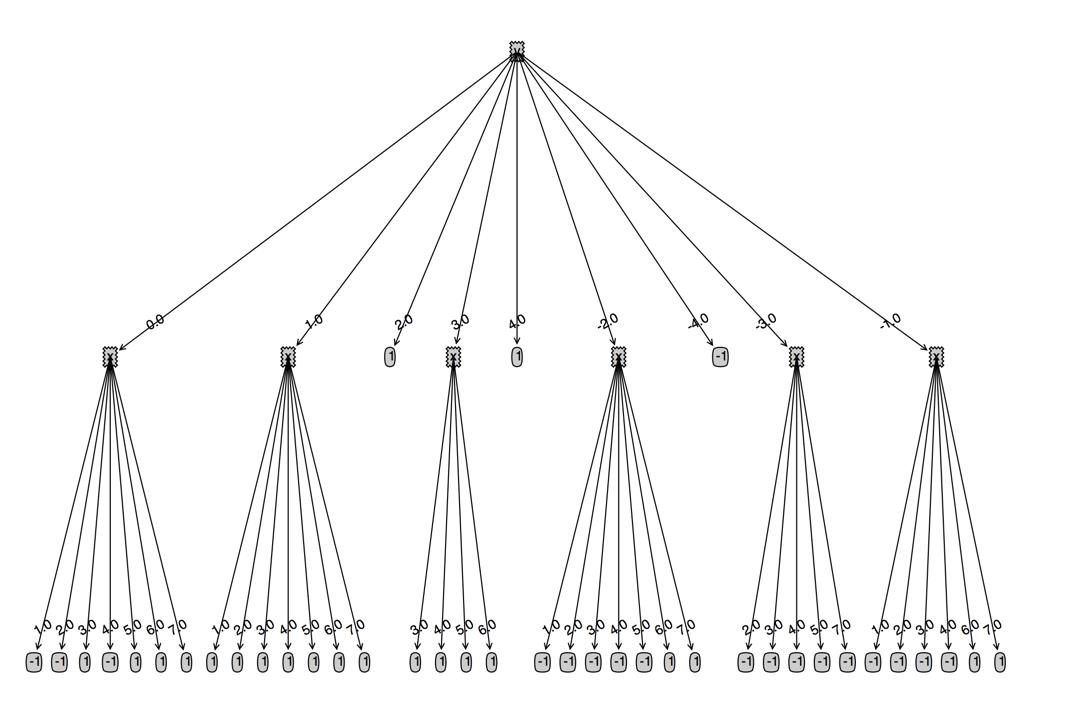
把新增的数据点的x坐标改为2.0,可以看多决策树增加了一个叶子节点为-1的分支。

总结:单纯的决策树一般只有一棵,而且树的深度和特征数一样;树的每一层的最大宽度和每个特征的特征值个数有关;比较适用于样本特征稳定而已特征值离散的情况;
多个类别采用多数表决的方法来决定分支的叶子节点的类别值;很难处理特征值连续的情况,当然连续的特征值离散化(就像坐标取整数一样)。
决策树就像一个很厉害的老师一样,或者就像“诸葛亮”一样,一棵决策树就能总览整个数据集,但是决策树的弊端也很明显,像一开始的连续的坐标,决策树的表现就不是很令人满意,
没有出现在训练集的数据,决策树甚至都不能给出预测值。
集成学习思想
跟决策树这种“依靠个人能力”的“单干”主义不一样,集成学习提出了一种“依靠普通人民智慧”的思想,集成学习核心思想:每个人都发表下意见,然后综合大家的看法给出最后的结果;又或者,每个人都只精通一个领域,每个人只对自己擅长的领域负责,然后各取所长,组合成最优的结果;
这些比单棵决策树弱的分类器我们一般称为弱分类器。
集成学习思想有很多种,下面说一个比较经典的adaboost,adaboost有几个特点:
- 用一系列弱分类器组合成一个强大的分类器
- 后面的分类器学习前面的分类器的结果
- 区分错误的样本的权重会被提高
对于我们的这个例子,我们只有两个特征x,y坐标,我们采用的弱分类器是一个决策树墩(深度为1的二叉树),对于我们这个例子通俗来说,
每一个弱分类器只会做类似这样的判断,(x/y)(>/<)t为正,否则为负,在图上画出来就是一条平行坐标轴的直线,下面我们直接来看下分类的效果吧:
图例是一个三元组(第n个弱分类器:lt(小于)|gt(大于)-阀值(为负样本):用了前n+1个弱分类器的错误率,
从图中可以看到用了3个弱分类器(直线)可以把错误率降低到15%
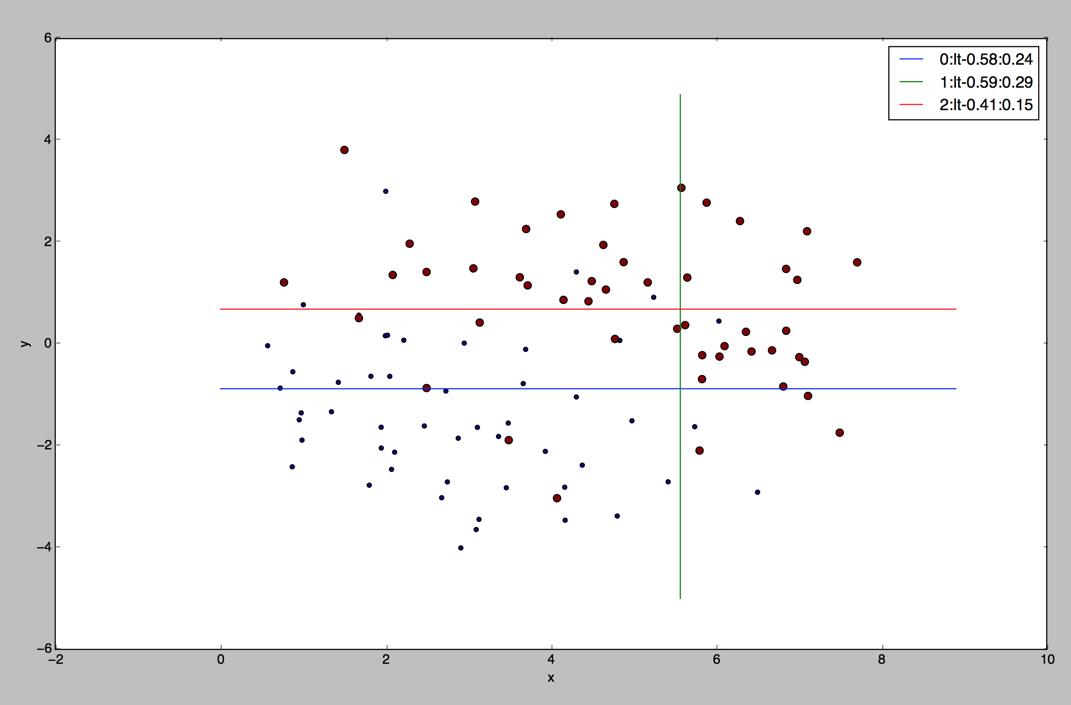
我们看下用10个弱分类器的效果怎么样,我们可以看到,使用更多的分类器,分类效果并没有提高
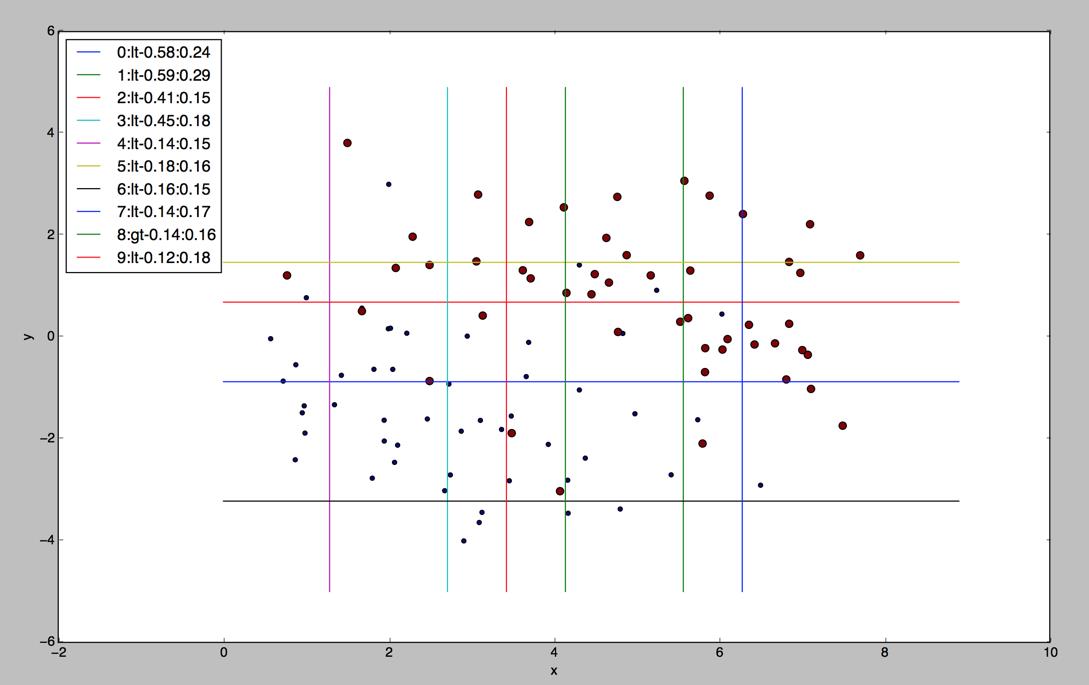
在这个例子中,adaboost使用的是简单的决策树墩,总体来说,效果还是不错的。
当然,继承学习还有更高级的算法可以学习,通常来说,我们可以通过下面几个方面来提高集成学习的成绩:
1:用更强的弱分类器,比如用分类回归树
2:改变弱分类器之间的关系,例如bagging的随机森林每个弱分类器之间是独立训练的,而boosting的GBDT则是跟adaboost一样,后面的决策树学习前面的决策树的结果。
以上是关于决策树到集成学习的主要内容,如果未能解决你的问题,请参考以下文章