正则表达式
Posted 青儿哥哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
声明:本文转载自:
http://deerchao.net/tutorials/regex/regex.htm
谢谢分享。
正则表达式30分钟入门教程
版本:v2.33 (2013-1-10) 作者:deerchao 转载请注明来源
目录
- 本文目标
- 如何使用本教程
- 正则表达式到底是什么东西?
- 入门
- 测试正则表达式
- 元字符
- 字符转义
- 重复
- 字符类
- 分枝条件
- 反义
- 分组
- 后向引用
- 零宽断言
- 负向零宽断言
- 注释
- 贪婪与懒惰
- 处理选项
- 平衡组/递归匹配
- 还有些什么东西没提到
- 联系作者
- 网上的资源及本文参考文献
- 更新纪录
本文目标
30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以在自己的程序或网页里使用它。
如何使用本教程
最重要的是——请给我30分钟,如果你没有使用正则表达式的经验,请不要试图在30秒内入门——除非你是超人 :)
别被下面那些复杂的表达式吓倒,只要跟着我一步一步来,你会发现正则表达式其实并没有想像中的那么困难。当然,如果你看完了这篇教程之后,发现自己明白了很多,却又几乎什么都记不得,那也是很正常的——我认为,没接触过正则表达式的人在看完这篇教程后,能把提到过的语法记住80%以上的可能性为零。这里只是让你明白基本的原理,以后你还需要多练习,多使用,才能熟练掌握正则表达式。
除了作为入门教程之外,本文还试图成为可以在日常工作中使用的正则表达式语法参考手册。就作者本人的经历来说,这个目标还是完成得不错的——你看,我自己也没能把所有的东西记下来,不是吗?
清除格式 文本格式约定:专业术语 元字符/语法格式 正则表达式 正则表达式中的一部分(用于分析) 对其进行匹配的源字符串 对正则表达式或其中一部分的说明
隐藏边注 本文右边有一些注释,主要是用来提供一些相关信息,或者给没有程序员背景的读者解释一些基本概念,通常可以忽略。
正则表达式到底是什么东西?
字符是计算机软件处理文字时最基本的单位,可能是字母,数字,标点符号,空格,换行符,汉字等等。字符串是0个或更多个字符的序列。文本也就是文字,字符串。说某个字符串匹配某个正则表达式,通常是指这个字符串里有一部分(或几部分分别)能满足表达式给出的条件。
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过Windows/Dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某个目录下的所有的Word文档的话,你会搜索*.doc。在这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
入门
学习正则表达式的最好方法是从例子开始,理解例子之后再自己对例子进行修改,实验。下面给出了不少简单的例子,并对它们作了详细的说明。
假设你在一篇英文小说里查找hi,你可以使用正则表达式hi。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是h,后一个是i。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配hi,HI,Hi,hI这四种情况中的任意一种。
不幸的是,很多单词里包含hi这两个连续的字符,比如him,history,high等等。用hi来查找的话,这里边的hi也会被找出来。如果要精确地查找hi这个单词的话,我们应该使用\bhi\b。
\b是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,\b匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w。
假如你要找的是hi后面不远处跟着一个Lucy,你应该用\bhi\b.*\bLucy\b。
这里,.是另一个元字符,匹配除了换行符以外的任意字符。*同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,.*连在一起就意味着任意数量的不包含换行的字符。现在\bhi\b.*\bLucy\b的意思就很明显了:先是一个单词hi,然后是任意个任意字符(但不能是换行),最后是Lucy这个单词。
换行符就是‘\n‘,ASCII编码为10(十六进制0x0A)的字符。
如果同时使用其它元字符,我们就能构造出功能更强大的正则表达式。比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d匹配这样的字符串:以0开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字(也就是中国的电话号码。当然,这个例子只能匹配区号为3位的情形)。
这里的\d是个新的元字符,匹配一位数字(0,或1,或2,或……)。-不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,我们也可以这样写这个表达式:0\d{2}-\d{8}。这里\d后面的{2}({8})的意思是前面\d必须连续重复匹配2次(8次)。
测试正则表达式
其它可用的测试工具:
如果你不觉得正则表达式很难读写的话,要么你是一个天才,要么,你不是地球人。正则表达式的语法很令人头疼,即使对经常使用它的人来说也是如此。由于难于读写,容易出错,所以找一种工具对正则表达式进行测试是很有必要的。
不同的环境下正则表达式的一些细节是不相同的,本教程介绍的是微软 .Net Framework 4.0 下正则表达式的行为,所以,我向你推荐我编写的.Net下的工具 正则表达式测试器。请参考该页面的说明来安装和运行该软件。
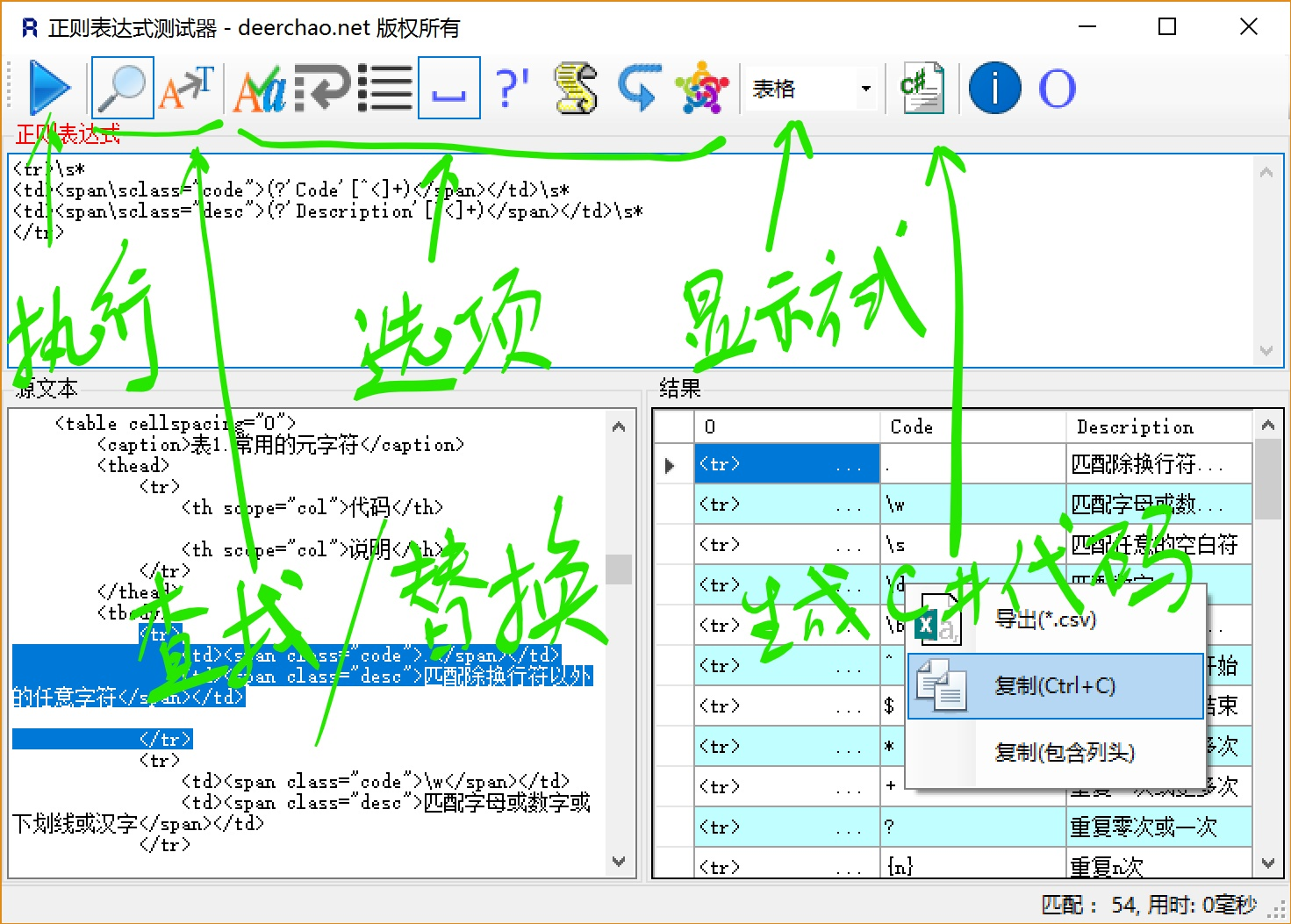
下面是Regex Tester运行时的截图:
元字符
现在你已经知道几个很有用的元字符了,如\b,.,*,还有\d.正则表达式里还有更多的元字符,比如\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。\w匹配字母或数字或下划线或汉字等。
对中文/汉字的特殊处理是由.Net提供的正则表达式引擎支持的,其它环境下的具体情况请查看相关文档。
下面来看看更多的例子:
\ba\w*\b匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
好吧,现在我们说说正则表达式里的单词是什么意思吧:就是不少于一个的连续的\w。不错,这与学习英文时要背的成千上万个同名的东西的确关系不大 :)
\d+匹配1个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。
\b\w{6}\b 匹配刚好6个字符的单词。
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
正则表达式引擎通常会提供一个“测试指定的字符串是否匹配一个正则表达式”的方法,如javascript里的RegExp.test()方法或.NET里的Regex.IsMatch()方法。这里的匹配是指是字符串里有没有符合表达式规则的部分。如果不使用^和$的话,对于\d{5,12}而言,使用这样的方法就只能保证字符串里包含5到12连续位数字,而不是整个字符串就是5到12位数字。
元字符^(和数字6在同一个键位上的符号)和$都匹配一个位置,这和\b有点类似。^匹配你要用来查找的字符串的开头,$匹配结尾。这两个代码在验证输入的内容时非常有用,比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:^\d{5,12}$。
这里的{5,12}和前面介绍过的{2}是类似的,只不过{2}匹配只能不多不少重复2次,{5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
因为使用了^和$,所以输入的整个字符串都要用来和\d{5,12}来匹配,也就是说整个输入必须是5到12个数字,因此如果输入的QQ号能匹配这个正则表达式的话,那就符合要求了。
和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,^和$的意义就变成了匹配行的开始处和结束处。
字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用\\.
例如:deerchao\.net匹配deerchao.net,C:\\Windows匹配C:\Windows。
重复
你已经看过了前面的*,+,{2},{5,12}这几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码,例如*,{5,12}等):
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
下面是一些使用重复的例子:
Windows\d+匹配Windows后面跟1个或更多数字
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
字符类
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章