Hadoop测试程序编写MapReduce测试Hadoop环境
Posted ssslinppp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop测试程序编写MapReduce测试Hadoop环境相关的知识,希望对你有一定的参考价值。

- 我们使用之前搭建好的Hadoop环境,可参见:
《【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式》http://www.cnblogs.com/ssslinppp/p/5923793.html
- 示例程序为《Hadoop权威指南3》中的获取最高温度的示例程序;
数据准备
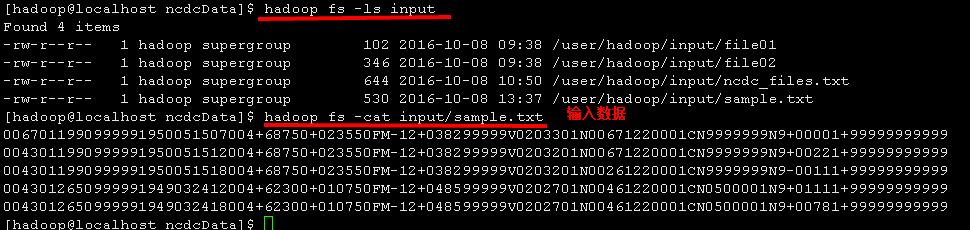
输入数据为:sample.txt

0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+999999999990043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+999999999990043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+999999999990043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+999999999990043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999
将samle.txt上传至HDFS

hadoop fs -put /home/hadoop/ncdcData/sample.txt input
项目结构
MaxTemperatureMapper类

package com.ll.maxTemperature;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class MaxTemperatureMapper extendsMapper<LongWritable, Text, Text, IntWritable> {private static final int MISSING = 9999;@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String year = line.substring(15, 19);int airTemperature;if (line.charAt(87) == \'+\') { // parseInt doesn\'t like leading plus// signsairTemperature = Integer.parseInt(line.substring(88, 92));} else {airTemperature = Integer.parseInt(line.substring(87, 92));}String quality = line.substring(92, 93);if (airTemperature != MISSING && quality.matches("[01459]")) {context.write(new Text(year), new IntWritable(airTemperature));}}}// ^^ MaxTemperatureMapper
MaxTemperatureReducer类

package com.ll.maxTemperature;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class MaxTemperatureReducer extendsReducer<Text, IntWritable, Text, IntWritable> {@Overridepublic void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int maxValue = Integer.MIN_VALUE;for (IntWritable value : values) {maxValue = Math.max(maxValue, value.get());}context.write(key, new IntWritable(maxValue));}}// ^^ MaxTemperatureReducer
MaxTemperature类(主函数)
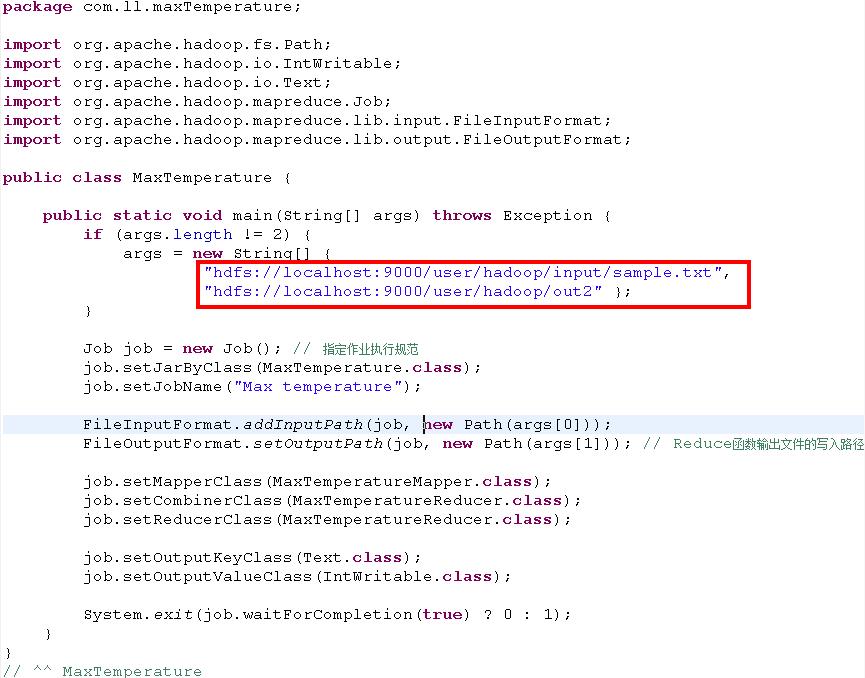
package com.ll.maxTemperature;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MaxTemperature {public static void main(String[] args) throws Exception {if (args.length != 2) {args = new String[] {"hdfs://localhost:9000/user/hadoop/input/sample.txt","hdfs://localhost:9000/user/hadoop/out2" };}Job job = new Job(); // 指定作业执行规范job.setJarByClass(MaxTemperature.class);job.setJobName("Max temperature");FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1])); // Reduce函数输出文件的写入路径job.setMapperClass(MaxTemperatureMapper.class);job.setCombinerClass(MaxTemperatureReducer.class);job.setReducerClass(MaxTemperatureReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);System.exit(job.waitForCompletion(true) ? 0 : 1);}}// ^^ MaxTemperature
解释说明:
输入路径为:hdfs://localhost:9000/user/hadoop/input/sample.txt
这部分由两部分组成:
- hdfs://localhost:9000/;
- /user/hadoop/input/sample.txt
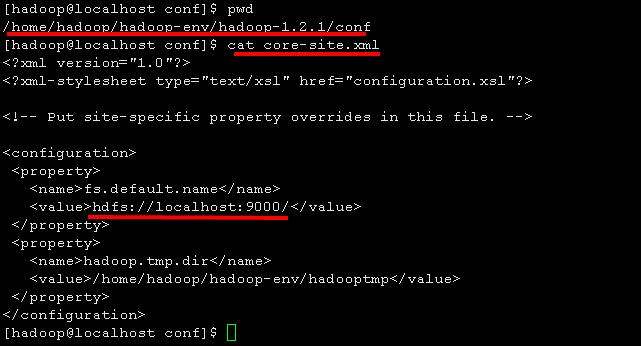
其中hdfs://localhost:9000/由文件core-size.xml进行设置:
其中/user/hadoop/input/sample.txt就是上面准备数据时sample.txt存放的路径:
输出路径为:hdfs://localhost:9000/user/hadoop/out2
需要注意的是,在执行MapReduce时,这个输出路径一定不要存在,否则会出错。
pom.xml

<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.ll</groupId><artifactId>MapReduceTest</artifactId><version>0.0.1-SNAPSHOT</version><packaging>jar</packaging><name>MapReduceTest</name><url>http://maven.apache.org</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hadoopVersion>1.2.1</hadoopVersion><junit.version>3.8.1</junit.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>${junit.version}</version><scope>test</scope></dependency><!-- Hadoop --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-core</artifactId><version>${hadoopVersion}</version><!-- Hadoop --></dependency></dependencies></project>
程序测试
Hadoop环境准备
我们使用之前搭建好的Hadoop环境,可参见:
《【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式》http://www.cnblogs.com/ssslinppp/p/5923793.html
生成jar包
下面是生成jar包过程

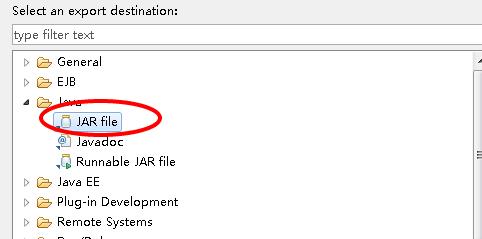
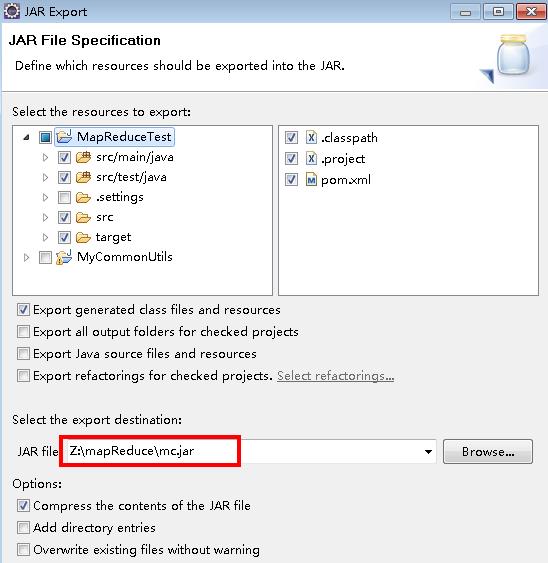
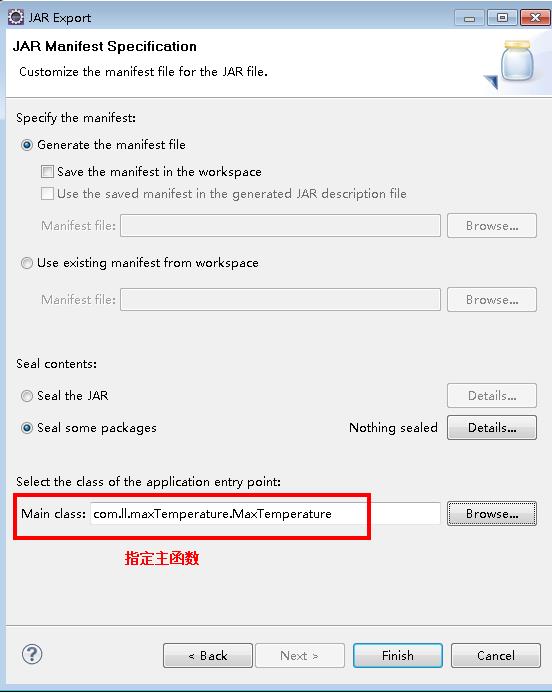
上传服务器并运行测试
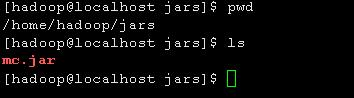
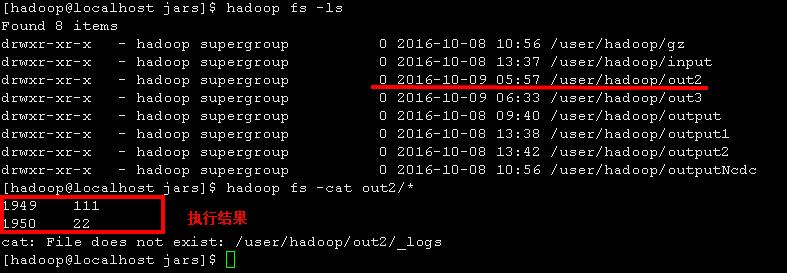
使用默认的输入输出路径:
hadoop jar mc.jar
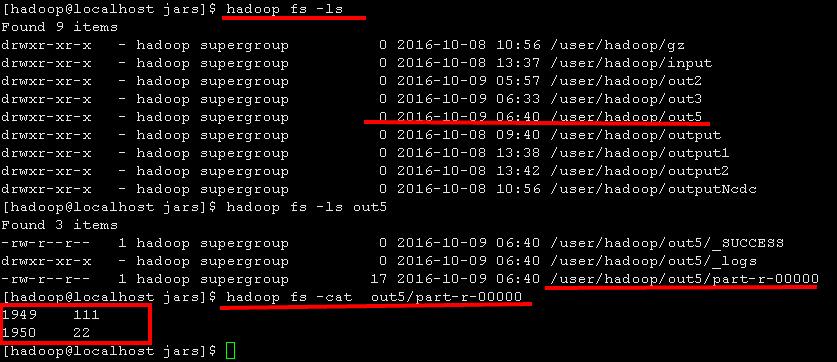
指定输入输出路径:

hadoop jar /home/hadoop/jars/mc.jar hdfs://localhost:9000/user/hadoop/input/sample.txt hdfs://localhost:9000/user/hadoop/out5
以上是关于Hadoop测试程序编写MapReduce测试Hadoop环境的主要内容,如果未能解决你的问题,请参考以下文章