机器学习技法(10)--Random Forest
Posted cyoutetsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习技法(10)--Random Forest相关的知识,希望对你有一定的参考价值。
随机森林是将bagging和decision tree结合在一起的算法。
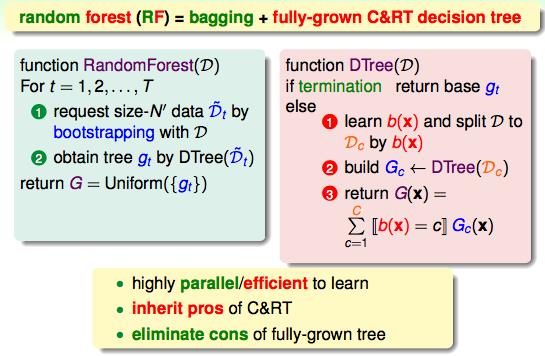
random forest同样也继承了两个算法的优点,但是同时也解决了过拟合的缺点。

通过降维的方式来提高运算的速度。

每一个低维度的空间都可以看成是原feature的一个线性组合,由高维度向低维度的转换的过程是随机的,这样又增加了一层随机性。
但是在bagging产生g的时候,总有一些feature的组合没有被选过(out-of-bag),而另一些组合被选择了多次。

假设N\'轮之后还有一些数据没有被选到过,这些数据的概率是1/3:


蓝色的数据已经用来产生g,而红色的OOB的特征很像用来做validation的数据。但是并不常用。因为g的验证并没有什么意义,我们要的的ensemble的hypothesis。
某一个红色的OOB可以被当做某个G\'的validation的数据,G\'由所有的没有用到该红色OOB的g ensemble而成。进而,把所有的G\'平均起来。
下面介绍Random Forest的feature selection:

我们需要把重复和无关的feature移除掉。

虽然特征选择很好,但是如何进行特征选择很麻烦。在随机森林中,通过验证重要的数据和不重要的数据的表现来确定哪些是重要的数据。

permutation test:假设有N个样本,d个维度的数据,我们想要看一下第i个维度的feature的重要性,可以把这些所有的样本的第i个维度的feature都打乱,再看一下打乱前后performance的差异。

为了避免多次的重新训练和validation的过程,在validation的时候进行打乱的动作。
总结:

以上是关于机器学习技法(10)--Random Forest的主要内容,如果未能解决你的问题,请参考以下文章