在字符编码格式选项里UTF-8(无BOM)是啥意思呀?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在字符编码格式选项里UTF-8(无BOM)是啥意思呀?相关的知识,希望对你有一定的参考价值。
我在使用编辑器打代码时,在字符编码格式选项里有一个UTF-8(无BOM)和UTF-8这两个选项,有什么区别吗?
UFT-8(无BOM),它所指的BOM是什么呀?
BOM——Byte Order Mark,就是字节序标记
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE“的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。
UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE“。
如果接收者收到FEFF,就表明这个字节流是大字节序的;如果收到FFFE,就表明这个字节流是小字节序的。因此字符”ZERO WIDTH NO-BREAK SPACE“又被称作BOM。

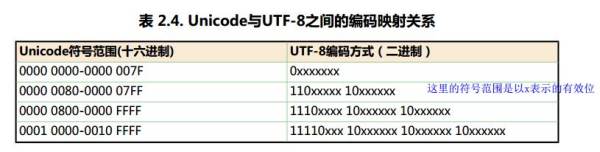
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE“的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
在utf-8编码文件中BOM在文件头部,占用三个字节,用来标识该文件属于utf-8编码,现在已经有很多软件识别BOM头,但还是有些不能识别BOM头,比如php就不能识别BOM头,这也就是用记事本编辑utf-8编码的PHP文件后,就会报错的原因。
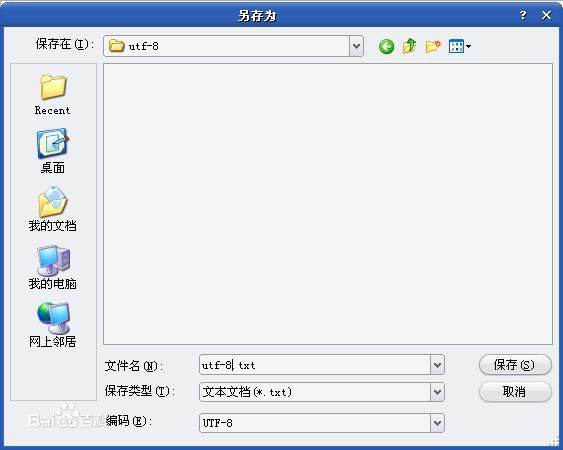
在windows环境下,用记事本打开任何一个文本文件,另存为utf-8格式后,这样文件就自动被加上了BOM头信息。可以很明显的看出,含BOM头的文件多出三个字节 efbbbf。notepad++会自动添加为带Bom的utf8。
拓展资料:
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
优缺点:
优点
UTF-8编码可以通过屏蔽位和移位操作快速读写。字符串比较时strcmp()和wcscmp()的返回结果相同,因此使排序变得更加容易。字节FF和FE在UTF-8编码中永远不会出现,因此他们可以用来表明UTF-16或UTF-32文本(见BOM) UTF-8 是字节顺序无关的。它的字节顺序在所有系统中都是一样的,因此它实际上并不需要BOM。
缺点
你无法从UNICODE字符数判断出UTF-8文本的字节数,因为UTF-8是一种变长编码它需要用2个字节编码那些用扩展ASCII字符集只需1个字节的字符 ISO Latin-1 是UNICODE的子集,但不是UTF-8的子集 8位字符的UTF-8编码会被email网关过滤,因为internet信息最初设计为7位ASCII码。因此产生了UTF-7编码。 UTF-8 在它的表示中使用值100xxxxx的几率超过50%, 而现存的实现如ISO 2022, 4873, 6429, 和8859系统,会把它错认为是C1 控制码。因此产生了UTF-7.5编码。
参考资料:
UFT-8-百度百科
参考技术ABOM: Byte Order Mark
UTF-8 BOM又叫UTF-8 签名,其实UTF-8 的BOM对UFT-8没有作用,是为了支援UTF-16,UTF-32才加上的BOM,BOM签名的意思就是告诉编辑器当前文件采用何种编码,方便编辑器识别,但是BOM虽然在编辑器中不显示,但是会产生输出,就像多了一个空行。
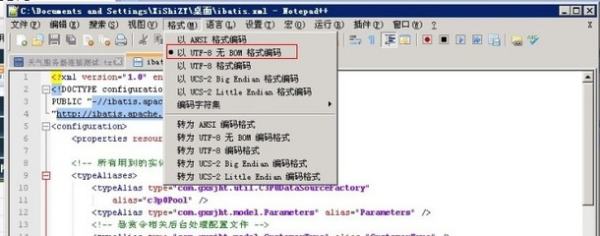
utf-8与utf-8(无BOM)的区别 :
BOM——Byte Order Mark,就是字节序标记
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little- Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
UTF- 8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开 头的FFFE了。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可 是,还是有很多软件不能识别BOM。
在Firefox早期的版本里,扩展是不能有BOM的,不过Firefox 1.5以后的版本已经开始支持BOM了。现在又发现,PHP也不支持BOM。PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。
由 于必须在在Bo-Blog的wiki看到,同样使用PHP的Bo-Blog也一样受到BOM的困扰。其中有提到另一个麻烦:“受COOKIE送出机制的限 制,在这些文件开头已经有BOM的文件中,COOKIE无法送出(因为在COOKIE送出前PHP已经送出了文件头),所以登入和登出功能失效。一切依赖 COOKIE、SESSION实现的功能全部无效。”这个应该就是Wordpress后台出现空白页面的原因了,因为任何一个被执行的文件包含了BOM, 这三个字符都将被送出,导致依赖cookies和session的功能失效。
解决的办法嘛,如果只包含英 文字符(或者说ASCII编码内的字符),就把文件存成ASCII码方式吧。用UE等编辑器的话,点文件->转换->UTF-8转 ASCII,或者在另存为里选择ASCII编码。如果是DOS格式的行尾符,可以用记事本打开,点另存为,选ASCII编码。如果包含中文字符的话,可以 用UE的另存为功能,选择“UTF-8 无 BOM”即可。
utf-8本来就不应该加bom,除了 让编辑器知道它是个utf-8之外什么用处都没有。实际上编辑器完全有能力在不太多的几个编码格式之间根据特征来判断一个文件是什么编码,就算不能自动识 别,编辑器也应该有设置编码的地方。所以我觉得BOM对于utf-8来说是多余的东西。
utf-16才需要加bom。因为它是按unicode顺序编码,在BMP范围内是二字节,需要识别是大或小字节序。
大小字节序存在的意义,在于cpu的处理方式。如果cpu是大字 节序处理,那么对于小字节序,就必须做一层转换,这带来了效率上的下降。但是在实际应用里,谁会去关心大小字节序?对于utf-16,认为只要全世界都遵循一种字节序方式,那就没什么必要用BOM来标注了。
话说回来,PHP是不支持utf-16编码的文件的。因为例如$这个符号,在utf-8里也是两个字节,PHP解码器无法解析的。不知道PHP6内部处理引入unicode 的概念之后,对这个是否会有支持。
编 码问题是一个说起来简单,但是实际上很繁琐的东西。很多程序,都有分层编码的概念。像mysql,就分为 client->connection->storage和storage->connection->result这些概念。 storage又分为system,database,table,column。像MySQL,谁用利用 它这些特性阿?除非允许两个client在不同的编码环境下运作,否则它把client编码分离出来根本没有什么必要。大多数情况下,直接binary in/binary out就好了。
参考技术B您好!
BOM: Byte Order Mark
UTF-8 BOM又叫UTF-8 签名,其实UTF-8 的BOM对UFT-8没有作用,是为了支援UTF-16,UTF-32才加上的BOM,BOM签名的意思就是告诉编辑器当前文件采用何种编码,方便编辑器识别,但是BOM虽然在编辑器中不显示,但是会产生输出,就像多了一个空行。

UTF-8(无BOM)和UTF-8的区别
BOM——Byte Order Mark,就是字节序标记
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK
SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符"ZERO
WIDTH NO-BREAK
SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-
Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF
BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
UTF-
8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开
头的FFFE了。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可
是,还是有很多软件不能识别BOM。
在Firefox早期的版本里,扩展是不能有BOM的,不过Firefox
1.5以后的版本已经开始支持BOM了。现在又发现,PHP也不支持BOM。PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。
由 于必须在在Bo-Blog的wiki看到,同样使用PHP的Bo-Blog也一样受到BOM的困扰。其中有提到另一个麻烦:“受COOKIE送出机制的限
制,在这些文件开头已经有BOM的文件中,COOKIE无法送出(因为在COOKIE送出前PHP已经送出了文件头),所以登入和登出功能失效。一切依赖
COOKIE、SESSION实现的功能全部无效。”这个应该就是Wordpress后台出现空白页面的原因了,因为任何一个被执行的文件包含了BOM,
这三个字符都将被送出,导致依赖cookies和session的功能失效。
UTF-8 不需要 BOM,尽管 Unicode 标准允许在 UTF-8 中使用 BOM。
所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下:把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。
BOM(byte order mark)是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题。
「UTF-8」和「带 BOM 的 UTF-8」的区别就是有没有 BOM。即文件开头有没有 U+FEFF。
BOM是什么?
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。在UCS 编码中有一个叫做 "Zero Width No-Break Space",中文译名作“零宽无间断间隔”的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 "Zero Width No-Break Space"。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到FFFE,就表明这个字节流是 Little- Endian 的。因此字符 "Zero Width No-Break Space" (“零宽无间断间隔”)又被称作 BOM(即Byte Order Mark)。
拓展内容:
字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
在计算机技术发展的早期,如ASCII(1963年)和EBCDIC(1964年)这样的字符集逐渐成为标准。但这些字符集的局限很快就变得明显,于是人们开发了许多方法来扩展它们。对于支持包括东亚CJK字符家族在内的写作系统的要求能支持更大量的字符,并且需要一种系统而不是临时的方法实现这些字符的编码。
参考技术D BOM: Byte Order MarkUTF-8 BOM又叫UTF-8 签名,其实UTF-8 的BOM对UFT-8没有作用,是为了支援UTF-16,UTF-32才加上的BOM,BOM签名的意思就是告诉编辑器当前文件采用何种编码,方便编辑器识别,但是BOM虽然在编辑器中不显示,但是会产生输出,就像多了一个空行,本回答被提问者采纳
以上是关于在字符编码格式选项里UTF-8(无BOM)是啥意思呀?的主要内容,如果未能解决你的问题,请参考以下文章
字符集为AL32UTF8的Oracle数据库导入编码格式为UTF-8无BOM编码的sql文件,导入的中文全是乱码,如何解决?