字符编码详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符编码详解相关的知识,希望对你有一定的参考价值。
版本:v2.3.1
摘要
本文主要介绍了字符编码的基础知识,以及常见的字符编码类型,比如ASCII,Unicode,UTF-8,ISO 8859等,以及各种编码之间的关系,同时专门解释了中文字符相关的编码标准,包括GB2312,GBK,GB18030,也专门解释了Windows系统中的Code Page,以及相关的BOM等内容
2015-05-24
| 修订历史 | ||
|---|---|---|
| 修订 2.3.1 | 2015-05-24 | crl |
|
||
| 修订 1.0 | 2011-11-02 | crl |
|
||
版权 © 2013 Crifan, http://crifan.com
目录
- 缩略词
- 正文之前
- 1. 字符编码相关的背景知识
- 2. 字符编码标准
- 2.1. 只支持基本的拉丁字符的字符编码:ASCII
- 2.1.1. ASCII的由来
- 2.1.2. ASCII编码规则
- 2.1.2.1. ASCII字符集中的功能/控制字符
- 2.1.2.1.1. 什么是Function Code功能码或 Function Character功能字符
- 2.1.2.1.2. ASCII中的Function/Control Code功能字符的详细含义
- 2.1.2.1.2.1. 0 – NUL – NULl 字符/空字符
- 2.1.2.1.2.2. 1 – SOH – Start Of Heading 标题开始
- 2.1.2.1.2.3. 2 – STX,3 – ETX
- 2.1.2.1.2.4. 4 – EOT – End Of Transmission 传输结束
- 2.1.2.1.2.5. 5 – ENQ – ENQuiry 请求
- 2.1.2.1.2.6. 6 – ACK – ACKnowledgment 回应/响应
- 2.1.2.1.2.7. 7 – BEL – [audible] BELl
- 2.1.2.1.2.8. 8 – BS – BackSpace 退格键
- 2.1.2.1.2.9. 9 – HT – Horizontal Tab 水平制表符
- 2.1.2.1.2.10. 10 – LF – Line Feed 换行
- 2.1.2.1.2.11. 11 – VT – Vertical Tab 垂直制表符
- 2.1.2.1.2.12. 12 – FF – Form Feed 换页
- 2.1.2.1.2.13. 13 – CR – Carriage return 机器的滑动部分/底座 返回 -> 回车
- 2.1.2.1.2.14. 14 – SO,15 – SI
- 2.1.2.1.2.15. 16 – DLE – Data Link Escape 数据链路转义
- 2.1.2.1.2.16. 17 – DC1 – Device Control 1 / XON – Transmission on
- 2.1.2.1.2.17. 18 – DC2 – Device Control 2
- 2.1.2.1.2.18. 19 – DC3 – Device Control 3 / XOFF – Transmission off 传输中断
- 2.1.2.1.2.19. 20 – DC4 – Device Control 4
- 2.1.2.1.2.20. 21 – NAK – Negative AcKnowledgment 负面响应-> 无响应, 非正常响应
- 2.1.2.1.2.21. 22 – SYN – SYNchronous idle
- 2.1.2.1.2.22. 23 – ETB – End of Transmission Block 块传输中止
- 2.1.2.1.2.23. 24 – CAN – CANcel 取消
- 2.1.2.1.2.24. 25 – EM – End of Medium 已到介质末端,介质存储已满
- 2.1.2.1.2.25. 26 – SUB – SUBstitute character替补/替换
- 2.1.2.1.2.26. 27 – ESC – ESCape 逃离/取消
- 2.1.2.1.2.27. 28 – FS – File Separator 文件分隔符
- 2.1.2.1.2.28. 29 – GS – Group Separator分组符
- 2.1.2.1.2.29. 30 – RS – Record Separator记录分隔符
- 2.1.2.1.2.30. 31 – US – Unit Separator 单元分隔符
- 2.1.2.1.2.31. 32 – SP – White SPace 空格键
- 2.1.2.1.2.32. 127 – DEL – DELete 删除
- 2.1.2.1.3. 各种字符的标准的读法/叫法
- 2.1.3. ISO 646
- 2.2. 支持多种衍生拉丁字母的字符编码:EASCII和ISO 8859
- 2.3. 各种单字节编码标准的关系
- 2.4. 支持世界上几乎所有字符的字符编码:Unicode
- 2.5. 代码页Code Page
- 2.6. ANSI字符编码
- 2.7. BOM
- 2.8. 中文字符编码标准
- 2.9. 字符存储(交换)标准
- 2.10. 字形和你所看到的字符的关系
- 参考书目
- A. 编码相关的表格
插图清单
- 2.1. ISO/IEC 8859的15个字符集的部分比较
- 2.2. ISO/IEC 8859-1字符集表
- 2.3. Unicode中的各种平面划分
- 2.4. Notepad中的各种编码
- 2.5. 汉字“宋”的不同字体
表格清单
- 2.1. ASCII中的控制字符
- 2.2. 各种单字节编码标准之间的关系
- 2.3. ISO/IEC 10646与Unicode的版本对应关系
- 2.4. Unicode与UTF-8之间的编码映射关系
- 2.5. 中文字符相关编码标准
- 2.6. 字符(存储)交换标准
- A.1. ASCII编码表(0-127)
- A.2. ISO/IEC 8859编码标准中的15种字符集
- A.3. ANSI的SBCS Code Page
- A.4. OEM的Code Page
- A.5. ANSI和OEM共有的DBCS Code Page
- A.6. 一些常见的Code Page
- A.7. 微软的代码页标识符(Code Page Identifiers)
- A.8. 不同编码所用的BOM
- ASCII (ASCII)
-
American Standard Code for Information Interchange
美国信息交换标准代码
- BMP (BMP)
-
Basic Multilingual Plane
基本多文种平面
- EBCDIC (EBCDIC)
-
Extended Binary Coded Decimal Interchange Code
扩展二进制编码十进制交换码
- IANA (IANA)
-
Internet Assigned Numbers Authority
互联网号码分配局
- ISO/IEC (ISO/IEC)
-
International Organization for Standardization / International Electrotechnical Commission
国际标准化组织和国际电工委员会
- UCS (UCS)
-
Universal Character Set
通用字符集
- UTF (UTF)
-
Unicode Transformation Format
Unicode转换格式
个人对于字符编码的理解,最开始主要是看了阮一峰的这篇文章:
【转】字符编码笔记:ASCII,Unicode和UTF-8然后自己花了更多的时间,搜集整理了和字符编码的更详细的知识,整理出来,以供大家参考。
其中也摘录了该贴的部分内容。
在介绍计算机的字符编码知识前,先来说说这个拉丁字母,估计也会有人和我一样,对于拉丁字母和英文字母以及汉语拼音中的字母的关系,不是很清楚。
拉丁字母,也叫罗马字母,是当今世界上使用最广的字母系统。
拉丁字母,或者说基本的拉丁字母,就是你所常见的到的ABCD等26个英文字母。
原先是欧洲那边使用的,后来由于欧洲殖民主义,导致后来的美洲等地,也是用的这套字母体系。
而其他有些地方,比如越南等,本来有自己的文字语言的,结果受西方文化的影响和由于基督教的传播,也用拉丁字母了。
所以总的说,现在欧洲多数国家,美洲,澳洲,非洲的多数国家,都是用的拉丁字母,即你所常见的英文字母,也是拉丁字母。而中国的汉语拼音,也是用的这个拉丁字母。
其中,欧洲很多国家,是对已有的26个基本的拉丁字母,加上连字,变音字符,弄出个衍生拉丁字母,但是还是属于拉丁字母。
说了这么多,就是要让你知道,后面内容所提到的英文字母,其来源于拉丁字母,而且我们汉语的汉语拼音,也是拉丁字母。
即:
- 基本的拉丁字母 = 26个英文字母 = 汉语中的汉语拼音
- 衍生的拉丁字母 = 从基本的26个英文字母,加上连字,变音等字符而衍生出来的拉丁字母 = 很多西欧国家的字母 (每个国家都不太一样)
计算机中存放的都是0和1的二进制值。8个位对应一个字节,常用16进制来表示。
而我们普通用户所希望看到的是,计算机把其所存储的对应的16进制的数值,转化为对应的字符,包括英文和中文等其他语言的字符,然后输出到屏幕上。
而所谓编码,就是,定义了一套规则,去指定,哪些数值,对应着哪些字符。
举个最简单的例子,常见65=0x41对应的是大写字母A,97=0x61对应的是小写字母a,而这套数值和字母之间的映射关系,说白了,就是一套规则,就叫做字符编码,即我们常说的ASCII编码。
那有人会问了,如果我定义了一套规则,假如叫张三编码,然后故意去把ASCII中的映射关系改变,比如97=0x61对应的是大写字母A,65=0x41对应的是小写字母a,等等,可不可以?答案是,完全可以,不过这套规则,首先没有得到所有计算机业界的一致认同,所以,除了你自己用,其他人不原意使用,那么也就是没了存在的价值了。
换句话说,当初ASCII之所以这么定义这套规则,就是这么定义了而已,然后大家都接受这个标准,然后就都用这个定义了。
即,如果当初定义为0x41代表的是小写字母a,而不是大写字母A,那么现在你所看到的,就是小写字母a就是对应着计算机中存储的0x41,而不是之前的0x61了。
所以,简单的说就是:
所谓字符编码,就是定义了一套规则,指定了计算机中存放的这么多值中的哪个值,对应了电脑屏幕显示出来的哪个字母。
目录
- 2.1. 只支持基本的拉丁字符的字符编码:ASCII
- 2.1.1. ASCII的由来
- 2.1.2. ASCII编码规则
- 2.1.2.1. ASCII字符集中的功能/控制字符
- 2.1.2.1.1. 什么是Function Code功能码或 Function Character功能字符
- 2.1.2.1.2. ASCII中的Function/Control Code功能字符的详细含义
- 2.1.2.1.2.1. 0 – NUL – NULl 字符/空字符
- 2.1.2.1.2.2. 1 – SOH – Start Of Heading 标题开始
- 2.1.2.1.2.3. 2 – STX,3 – ETX
- 2.1.2.1.2.4. 4 – EOT – End Of Transmission 传输结束
- 2.1.2.1.2.5. 5 – ENQ – ENQuiry 请求
- 2.1.2.1.2.6. 6 – ACK – ACKnowledgment 回应/响应
- 2.1.2.1.2.7. 7 – BEL – [audible] BELl
- 2.1.2.1.2.8. 8 – BS – BackSpace 退格键
- 2.1.2.1.2.9. 9 – HT – Horizontal Tab 水平制表符
- 2.1.2.1.2.10. 10 – LF – Line Feed 换行
- 2.1.2.1.2.11. 11 – VT – Vertical Tab 垂直制表符
- 2.1.2.1.2.12. 12 – FF – Form Feed 换页
- 2.1.2.1.2.13. 13 – CR – Carriage return 机器的滑动部分/底座 返回 -> 回车
- 2.1.2.1.2.14. 14 – SO,15 – SI
- 2.1.2.1.2.15. 16 – DLE – Data Link Escape 数据链路转义
- 2.1.2.1.2.16. 17 – DC1 – Device Control 1 / XON – Transmission on
- 2.1.2.1.2.17. 18 – DC2 – Device Control 2
- 2.1.2.1.2.18. 19 – DC3 – Device Control 3 / XOFF – Transmission off 传输中断
- 2.1.2.1.2.19. 20 – DC4 – Device Control 4
- 2.1.2.1.2.20. 21 – NAK – Negative AcKnowledgment 负面响应-> 无响应, 非正常响应
- 2.1.2.1.2.21. 22 – SYN – SYNchronous idle
- 2.1.2.1.2.22. 23 – ETB – End of Transmission Block 块传输中止
- 2.1.2.1.2.23. 24 – CAN – CANcel 取消
- 2.1.2.1.2.24. 25 – EM – End of Medium 已到介质末端,介质存储已满
- 2.1.2.1.2.25. 26 – SUB – SUBstitute character替补/替换
- 2.1.2.1.2.26. 27 – ESC – ESCape 逃离/取消
- 2.1.2.1.2.27. 28 – FS – File Separator 文件分隔符
- 2.1.2.1.2.28. 29 – GS – Group Separator分组符
- 2.1.2.1.2.29. 30 – RS – Record Separator记录分隔符
- 2.1.2.1.2.30. 31 – US – Unit Separator 单元分隔符
- 2.1.2.1.2.31. 32 – SP – White SPace 空格键
- 2.1.2.1.2.32. 127 – DEL – DELete 删除
- 2.1.2.1.3. 各种字符的标准的读法/叫法
- 2.1.3. ISO 646
- 2.2. 支持多种衍生拉丁字母的字符编码:EASCII和ISO 8859
- 2.3. 各种单字节编码标准的关系
- 2.4. 支持世界上几乎所有字符的字符编码:Unicode
- 2.5. 代码页Code Page
- 2.6. ANSI字符编码
- 2.7. BOM
- 2.8. 中文字符编码标准
- 2.9. 字符存储(交换)标准
- 2.10. 字形和你所看到的字符的关系
计算机刚出现的时候,虽然是美国人发明的,但是也要面对一个问题,即如何将对应的计算机中的数值,转化为对应的字母,而显示出来,即采用什么样的规则,而当时,各个厂家或公司都有自己的做法,也就是说,编码规则没有统一。
但是相对来说,得到大家认可的有,IBM的EBCDIC和此处要谈的ASCII。
其中EBCDIC现在基本没人再用,而大家统一都用ASCII了。
ASCII,即American Standard Code for Information Interchange,美国信息交换标准代码。
单独看名字,就是知道,这字符编码是设计给美国人用的。
那是因为,计算机是美国人所发明和使用的,所以计算机的早期,所设计编码标准,自然需要先为英文字符来设计和考虑,所以此最早的字符编码ASCII可以显示常见的英文字符,也可以这么说,也只能显示基本的英文字符。
由于ASCII编码中,不包括其他欧洲的很多国家的衍生的拉丁字母的那些字符,更不包含亚洲,比如中国的中文字符,因此才会有后面所提到的各种其他字符集,为的就是可以让计算机显示出自己国家的字符。
ASCII的编码规则,由于最初只是为英文字母所考虑的,而英文只有26个字母,以及加上其他大小写字母,常见的字符,常见数字等,所有的加起来,也就几十个,而一个字节8位中前7位的理论上可以表示27=128个字符,所以对于设计出来的编码规则来说,只需要用一个字节来表示,就足够了。
即ASCII编码规则中规定,用单个字节共8位来表示字符,其中最高位为0,其他7位所对于的每一个值,映射到某个特定的字符,这样就形成了ASCII编码。
ASCII共包含了27=128个字符。
其中包括33个不可显示的字符和95个可显示的字符。
而对于ASCII编码规则,简单说就是:
7位的字符编码,即每个字节的最高位第8位为0,其余7位的某个值对应着某个字符。
ASCII字符集共27=128个字符 = 33个控制字符 + 95个可见字符。
 |
>ASCII中的可显示的字符和不可显示字符 |
|---|---|
|
ASCII中可显示的字符,也叫可打印printable字符; 而ASCII中的值为0 – 31的那些字符,叫做不可显示的字符,也叫不可见字符,不可打印(non-printable)字符,由于其字符的作用是起一定的控制作用,所以常称为控制字符(control character),即不同的字符实现不同的功能,因此又称为功能字符(function code,function character)。 即ASCII字符集中: 不可见字符 =不可打印(non-printable)字符 =控制字符(control character) =功能字符(function code,function character) 对于ASCII中的控制字符,都包括哪些,以及每个字符的详细含义,第 2.1.2.1 节 “ASCII字符集中的功能/控制字符”中会有详细介绍。 |
ASCII字符集,大家都知道吧,最基本的包含了128个字符。其中前32个,0-31,即0x00-0x1F,都是不可见字符。这些字符,就叫做控制字符。
这些字符没法打印出来,但是每个字符,都对应着一个特殊的控制功能的字符,简称功能字符或功能码Function Code。
简言之:ASCII中前32个字符,统称为Function Code功能字符。
此外,由于ASCII中的127对应的是Delete,也是不可见的,所以,此处根据笔者的理解,也可以归为Function Code。
此类字符,对应不同的“功能”,起到一定的“控制作用”,所以,称为控制字符。
关于每个控制字符的控制功能缩写,参见表 2.1 “ASCII中的控制字符”
表 2.1. ASCII中的控制字符
| 十进制 | 十六进制 | 控制字符 | 转义字符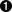 | 说明 | Ctrl + 下列字母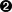 |
|---|---|---|---|---|---|
| 0 | 00 | NUL | \0 | Null character(空字符) | @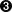 |
| 1 | 01 | SOH | Start of Header(标题开始) | A | |
| 2 | 02 | STX | Start of Text(正文开始) | B | |
| 3 | 03 | ETX | End of Text(正文结束) | C | |
| 4 | 04 | EOT | End of Transmission(传输结束) | D | |
| 5 | 05 | ENQ | Enquiry(请求) | E | |
| 6 | 06 | ACK | Acknowledgment(收到通知/响应) | F | |
| 7 | 07 | BEL | \a | Bell(响铃) | G |
| 8 | 08 | BS | \b | Backspace(退格) | H |
| 9 | 09 | HT | \t | Horizontal Tab(水平制表符) | I |
| 10 | 0A | LF | \n | Line feed(换行键) | J |
| 11 | 0B | VT | \v | Vertical Tab(垂直制表符) | K |
| 12 | 0C | FF | \f | Form feed(换页键) | L |
| 13 | 0D | CR | \r | Carriage return(回车键) | M |
| 14 | 0E | SO | Shift Out(不用切换) | N | |
| 15 | 0F | SI | Shift In(启用切换) | O | |
| 16 | 10 | DLE | Data Link Escape(数据链路转义) | P | |
| 17 | 11 | DC1 | Device Control 1(设备控制1) /XON(Transmit On) | Q | |
| 18 | 12 | DC2 | Device Control 2(设备控制2) | R | |
| 19 | 13 | DC3 | Device Control 3(设备控制3) /XOFF(Transmit Off) | S | |
| 20 | 14 | DC4 | Device Control 4(设备控制4) | T | |
| 21 | 15 | NAK | Negative Acknowledgement(拒绝接收/无响应) | U | |
| 22 | 16 | SYN | Synchronous Idle(同步空闲) | V | |
| 23 | 17 | ETB | End of Trans the Block(传输块结束) | W | |
| 24 | 18 | CAN | Cancel(取消) | X | |
| 25 | 19 | EM | End of Medium(已到介质末端/介质存储已满) | Y | |
| 26 | 1A | SUB | Substitute(替补/替换) | Z | |
| 27 | 1B | ESC | \e | Escape(溢出/逃离/取消) | [ |
| 28 | 1C | FS | File Separator(文件分割符) | \ | |
| 29 | 1D | GS | Group Separator(分组符) | ] | |
| 30 | 1E | RS | Record Separator(记录分隔符) | ^ |
|
| 31 | 1F |
以上是关于字符编码详解的主要内容,如果未能解决你的问题,请参考以下文章