On cloud, be cloud native
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了On cloud, be cloud native相关的知识,希望对你有一定的参考价值。
本来不想起一个英文名,但是想来想去都没能想出一个简洁地表述该意思的中文释义,所以就用了一个英文名称,望见谅。
Cloud Native是一个刚刚由VMware所提出一年左右的名词。其表示在设计并实现一个应用时,软件开发人员需要尽量使用云所提供的一系列较为先进的特性来提高应用的开发及部署效率,并使得应用的服务质量,如高可用性等,得到显著的提升。其并没有一个定量的要求,而只是一种定性的思维方式。那么对云所提供的哪些特性的使用可以提高应用的开发及部署效率,提升服务质量呢?
由于网络上已经有了很多有关创建一个Cloud Native应用所需要遵守的一系列规则的讨论,因此我们将不再对这些泛泛的讨论进行讲解。而在本文中,我们将以Amazon为例,讲解如何利用其所提供的一系列功能来做到Cloud Native。由于这只是一篇类似于简介的文章,因此我会控制在10页Word以内。
云所带来的不同
我相信的一点是,无论您是否开发过云应用,您对云至少会有多多少少的了解。本节将只对将会涉及到的云的特性进行简单地介绍。
云所提供的是一系列虚拟化的资源,而这些虚拟化的资源则实际运行在一系列物理资源之上。相较于直接使用物理资源,云使用了额外的一层虚拟化层:
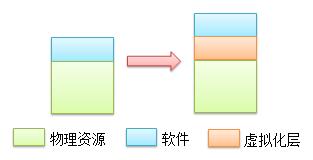
我们都知道,额外的组成会带来额外的风险。这个多出的虚拟化层也一样。在使用物理资源时,操作系统直接运行在物理资源上。此时我们所面临的风险有:物理资源的失效,以及在其上所运行的软件的失效。而在添加了额外的一层虚拟化层之后,我们同样需要面对物理资源失效这一问题。而且由于虚拟化层所使用的操作系统或多或少都与原版系统有一些不同,因此这些操作系统也常常具有较大的出错概率。除此之外,虚拟化层自身也有可能出现问题,例如虚拟化层管理软件失效等。因此运行在一个虚拟化环境中的独立组成常常会拥有更大的失效概率。
那运行在云之上的应用岂不是会有更多的宕机时间?答案是:这取决于应用到底是如何设计的。如果一个部署在云上的应用和运行在物理资源上的应用的设计思路没有什么不同,那么这个应用的确拥有更高的宕机概率。但是如果我们能充分利用云所提供的一系列功能来完成应用的灾难恢复以及高可用性设计,那么该应用反而会提供更高的可用性。除此之外,我们还可以在扩展性(Scalability,国内译法有歧义,无法与Extensibility区分),灾难恢复等一系列非功能性需求上得到显著地提升。
那这句“充分利用云所提供的一系列功能”该如何理解呢?
首先就是,在云上创建一台虚拟机往往比向我们自己的服务集群添加一台物理机容易得多,也快速得多。在添加一台物理机时,我们需要完成物理机的安装,布线,添加电力管理等一系列操作。甚至在手头上没有现成物理机的时候经由采购购买新的机器。因此从有了需求直到所有的环境准备完毕至少需要几个小时,甚至可能需要数个月的时间。如果物理机发生了损坏,如断电后无法成功启动,那么分析并解决问题也常常需要数个小时的时间。相比较下,在云上申请一台新的虚拟机则往往只需要几分钟。在需要一个新的虚拟机实例时,我们只需要简单地向云服务提供商发送一个请求并等待几分钟就可以得到该实例。而在一个虚拟机发生了故障时,我们也可以直接通过请求一台虚拟机来替换原有虚拟机的方式继续提供服务。而所有这一切常常只需要几分钟。
除此之外,云平台所提供的自动化支持也常常是一个巨大的优势。试想一下,如果监控系统发现了应用中的某台虚机已经无法正常工作,那么它完全可以向处理该情况的组成发送一个通知。接收到该通知的组成将向云平台重新申请一台虚拟机,并销毁原有的虚拟机。在自动化支持的帮助下,这一切完全可以在数分钟内完成。所以基于云的服务常常拥有一系列脚本,以能够自动地进行灾难恢复,容量扩展等一系列原本非常耗时的操作。
而在这两点之上,云服务常常会提供一系列对服务开发人员进行支持的工具。最为常见的例子就是在云上部署用于开发及测试的环境。在云所提供的快速部署虚拟机以及自动化脚本的帮助下,软件开发及测试人员常常可以通过一键点击的方式来完成对特定版本应用的部署,进而在其上完成对新功能的开发及测试。而在不再需要这些部署出的应用时,我们也只需要一次点击就对这些应用所占用的资源进行回收。
除此之外,云还能帮助企业节省大量的资金。在自行搭建应用所运行的硬件平台的情况下,我们首先要考虑的就是如何定义应用所需要的容量。如果容量太小,那么应用的负载将很容易地超过硬件容量,造成应用所提供的服务质量下降,甚至产生临时的无法提供服务的情况;如果容量太大,那么将有大量的处理能力将被闲置,从而造成资源的利用率非常低。而在云上的应用则不同了。当应用负载处于波谷时,我们可以缩减应用所使用资源的规模,以减少资源占用,提高资源的利用率,降低成本;而当应用的负载到达某个阈值时,我们可以向云申请更多的资源。由于这些资源都是按实际的使用情况计费的,因此一个设计良好的Cloud Native应用将为我们节省大量的资金。
当然,我们只是列出了最为基本的几条。而在真正开发一个Cloud Native应用时,我们不仅仅需要了解这些基础的思路,更重要的是对云所提供的功能有所了解。只有充分地利用了云平台所提供的便捷功能,才能最大限度地保证云上应用的高质量运行。
另外需要插一句的是,Cloud Native无助于解决云所具有的Vendor lock-in问题,甚至是对该问题的解决有一定的影响。这是因为每种云都有一系列自身所特有的功能,而对特有功能的使用则会导致应用在云之间迁移变得较为困难。
基础设计
在设计时,一个Cloud Native应用就需要考虑如何使用云平台所提供的各种特性。这其中的很多特性实际上是和运维有关的。一个最常见的例子就是如何对应用进行扩容。在以往的应用中,运维人员需要根据当前服务的负载来判断是否应用的现有容量能够应对所有的负载。如果现有容量只能勉强处理负载的峰值,那么他就需要开始着手准备对应用进行扩容了。但是在云上,我们完全可以将这些自动化:当当前服务的某个组成达到非安全负载时,监控系统会向服务发送一条通知,而通知的响应逻辑会与云进行通讯以得到更多的容量。这一切功能都需要软件开发人员在应用设计时就将这些机制考虑进去,而不再是交由运维人员负责。
软件开发人员在设计一个Cloud Native应用时所遇到的最大困难莫过于如何定义一系列合适的运维准则。这一方面和软件开发人员并不熟悉运维知识有关,而且就算知道了这些运维知识,也会因为传统运维经验和基于云的运维之间的差距而导致作为运维行为发生标准的各个阈值与最佳数值之间存在着较大的偏差。
因此如果软件开发人员希望能够开发出较为出色的Cloud Native应用,那么他必须要学习一系列和运维相关的知识。除此之外,他还需要将这些阈值设计为一系列可以被更改的配置文件,并通过一系列版本管理工具来记录这些修改。这样才能够较为容易地根据应用的实际运行对整个服务进行逐步调优。
而接下来的事情就是对整个产品进行架构设计了。鉴于Cloud Native应用对于高可用性以及扩展性(Scalability)的要求,一种常见的组织应用组织方式就是Micro-service。Micro-service中的最基本组成是各个子服务。这些子服务可以很容易地通过添加结点进行扩容,因此其对服务的扩展性支持得很好。同时通过向服务中添加冗余结点,我们可以很容易地通过这些冗余结点构建具有高可用性的解决方案。有关扩展性以及Micro-service的讲解请看我的另两篇博客《服务的扩展性》以及《Microservice简介》。在这里我们不再赘述。
接下来,我们就可以开始着手开发应用中的各个子服务了。首先要考虑的是,这些子服务在运行时的负载到底是什么样的?那现在就让我们以一个股票交易系统为例,讲解到底应该如何对应用所具有的负载进行处理。通常情况下,股票交易系统会在开市前的集合竞价阶段以及刚刚开市时的交投活跃阶段接收到大量交易委托;而在其它交易时间段,交易量将大幅下降;而在当日休市后,股票交易系统将只负责对一系列基本信息的读取操作。也就是说,该系统的负载是在不断变化并具有一定的时间规律的:
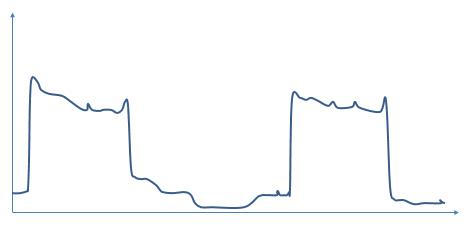
如果我们自行搭建服务运行所需要的物理环境,那么我们就需要保证该物理环境的容量大于可能产生的特殊情况下的峰值负载。而该值将远大于通常情况下的峰值负载:
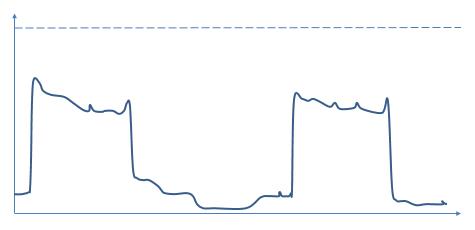
可以看到,这种方法要求我们将服务所提供的容量定义得远远超出实际需求,而仅仅是为了能够在服务迎来超级峰值时能为用户提供优质的服务。也就是说,我们需要为了发生概率非常小的事件提供了远超过实际需求的容量。
而大多数云所能提供的快速增加/减少容量的功能则最适合用来处理这种容量变化的情况。就让我们以一个负载波峰为例展示云是如何根据自身负载来对容量进行控制的:
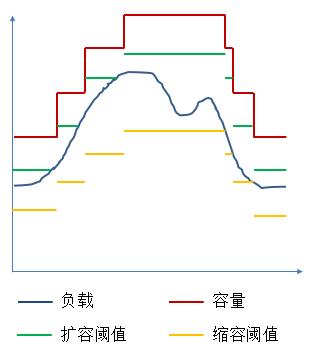
上图中展示了一个基于云的应用所需要的容量随着负载发生变化的情况。可以看到,如果当前系统的负载达到了系统当前容量的扩容阈值,那就表示系统的当前负载已经接近当前的容量极限。为了避免由于系统的负载超过系统容量而导致无法为某些用户提供服务,软件将向云发送扩容通知,并在几分钟后获得云平台所提供的新增加的容量。而在负载下降时,系统的负载将可能触及缩容阈值。此时软件将要求云平台对其部分容量进行回收,从而减少对资源的占用,以降低应用的运营成本。
总的来说,基于云的应用在运行时将根据实际负载来决定自身的容量,而云自身将只对应用所消耗的容量进行计费。因此其实际上大大地降低了运行该应用的实际成本。
而Amazon所提供的一系列虚拟机实例购买方式则可以让应用的运营成本进一步降低。其所提供的虚拟机购买方式如下所示:
- On-Demand:随时可以获得并按小时收费的虚拟机实例
- Reserved:以优惠价格购买较长使用时间的虚拟机实例
- Scheduled:在固定时间可以使用的虚拟机实例,价格较为便宜
- Spot:以喊价方式获得的虚拟机实例,出价高的用户将获得该实例。因此较适合需要较多计算资源而并不那么紧迫的任务
- Dedicated host:指定虚拟机在特定的硬件上运行。其价格较为高昂
那么对于上图所示的具有周期性负载的服务,我们就可以通过一系列购买组合来减少我们运行服务所需要的成本:
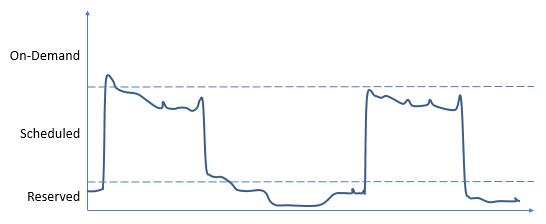
从上图中可以看出,对于一个负载具有周期性变化的资源,其中用来提供服务的虚拟机实例常常是由通过不同方式购买的虚拟机实例共同组成的:Reserved实例所具有的容量只略大于用来处理负载波谷时期的能力,并且全天都处于服务状态下;而Scheduled实例将在特定时间内提供服务,是处理高峰负载的主力。但是有些时候,服务所接受到的瞬间负载常常会超过这两种资源所拥有的容量。此时用来提供服务的便是On-Demand实例。
当然,服务是不断发展的。当服务获得了越来越多的用户,其所对应的峰值负载等都会有相应的增加。此时我们就需要根据实际情况更改每种购买方式的购买量。
由于不同的云所提供的虚拟机实例购买方式并不相同,因此在创建您自己的Cloud Native应用时,您需要根据该云平台所实际提供的虚拟机销售方式设计一套方案,以获取相对较低的运行成本。
现在我们有了用于运行应用所需要的各个虚拟机,下一步就是设计到底应该如何将它们组织在一起以提供服务了。一个传统的Web应用所常具有的结构如下所示:
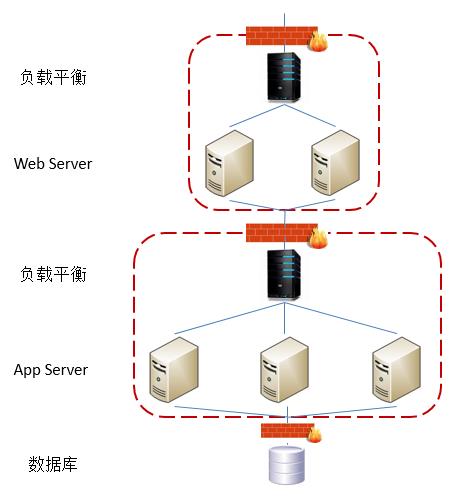
上图展示了一个传统的Web应用所具有的最基本架构。其主要由Web Server,App Server以及数据库组成。Web Server主要用来处理HTTP请求,App Server则用来完成应用在提供服务时所需要处理的操作,而数据库则用来存储数据。
而在Amazon上定义的应用所具有的基本架构则会有一点不同:
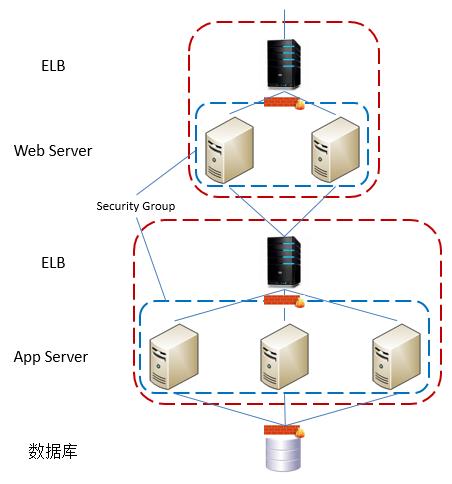
可以看到,基于Amazon的应用对虚拟机实例的组织方式与传统的Web应用的物理机组织方式基本相同。唯一不同的是,防火墙的位置是在Elastic Load Balancer之后了。这是因为在Amazon中,防火墙的功能主要是通过Security Group完成的。
当然,除了这些功能之外,您还可以使用以下一些功能来提高应用的性能:
- CloudFront:Amazon所提供的CDN。其提供了与AWS的原生集成。在用户发送一个请求时,如果该请求可以由CloudFront来处理,那么该用户将被导向距离他最近的服务。如果CloudFront不能向用户提供缓存的内容,那么它就会向服务实例请求该内容,然后再将请求的结果发送给用户。
- Route 53:Amazon所提供的DNS服务。其提供域名注册服务,DNS服务,并辅助检测DNS后的应用是否正常工作。通过Route 53,我们可以实现基于DNS的负载平衡(详见《企业级负载平衡简介》),也既是根据用户所在地对应用进行基于Z轴的扩展(详见《服务的扩展性》)。
- ElastiCache:服务端缓存。用户可以选择到底是通过Memcache还是Redis协议来对数据进行存取。如果您的服务之前就使用这两种服务端缓存,那么将服务端缓存功能迁移到ElastiCache之上是一件非常容易的事情。
提高了应用的性能即可以减少系统运行所需要的资源,从而降低了应用的开销。
Day 2 Operation的支持
在这一节中,我们会介绍与云应用维护相关的一系列相关功能。这些功能会自动地被触发,并自动地对脚本进行执行,从而使得运维变得简单高效。
这一切的核心主要是CloudWatch。在运行时,每种AWS资源都会将一系列运行指标定时地保存在一个被称为Repository的数据容器中。除此之外,用户还可以在这些Repository中保存一系列自定义的指标。在用户需要的时候,软件开发人员可以通过特定的API调用读取这些指标。如果软件开发人员希望能够在某个指标到达某种状态时自动执行某些运行逻辑,那么他就需要使用CloudWatch的Alarm功能。这些Alarm会监听指定的指标,并在指标到达特定条件时发送一个通知到Amazon SNS或一个Auto Scaling Policy之上,进而执行相应的处理逻辑:
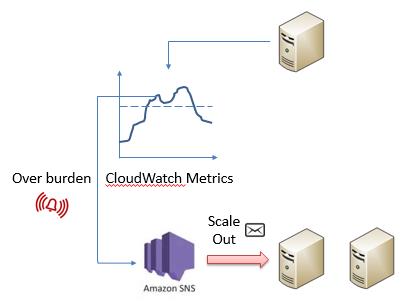
如上图所示,有了监控,我们就可以根据系统状态探测并解决系统出现的问题了。这些问题可能包含有系统过载,虚拟机实例失效等。一旦CloudWatch发现了问题,它就可以通过Amazon SNS发送通知消息的方式来促使相应的组成来执行用来解决这些问题的脚本。
而对于一些常用的解决方案,如虚拟机实例的横向扩展以及灾难恢复,Amazon则提供了一系列解决方案。例如在需要对容量进行扩展时,最“Cloud Native”的方法就是Auto Scaling Group了。可以说,这是Amazon所具有的特有功能(Openstack现在有一个Proposal)。在创建一个Auto Scaling Group时,软件开发人员可以标示其所管理的实例类型,每个实例所使用的AMI,以及其可以包含的实例个数的最大值,最小值以及默认值。当然了,对于这样一组实例,其自然需要一个负载平衡服务器来完成对请求的分发。为此,软件开发人员只需要在配置中设置好需要使用的负载平衡服务器实例即可。而在服务运行过程中,如果负责监控的CloudWatch发现Auto Scaling Group中的某些实例负载过重,那么其将可以发送一个Alarm并由Auto Scaling Group执行对它的响应:

除此之外,Auto Scaling Group还可以帮助我们实现N+1冗余,以帮助我们的应用实现高可用性。简单地说,就是N个能够正常工作并处理现有负载的实例由N+1个实例所共同负担。在一个处于Auto Scaling Group中的实例失效时,其它N个能够正常工作的实例仍能够向用户提供正常的服务。由于Auto Scaling Group会自动探测失效的实例并将重新启动一个实例来替换失效的实例,因此在数分钟之后,Auto Scaling Group将会重新拥有N+1个能够正常工作的实例。
而Amazon所提供的另外两个功能,存储在S3上的AMI以及EBS存储则可以帮助我们进一步加快这个实例替换的过程。试想一下一个全新的物理机要达到工作状态需要做什么样的工作:首先要将物理机设置完毕并启动,然后安装并配置操作系统,最后安装并配置其所需要的软件,甚至还需要通过数据库日志或运行脚本等一系列方式进行预热。这一切都需要很多时间不是么?但是在AMI以及EBS存储的帮助下,这一切将会缩短到几分钟:
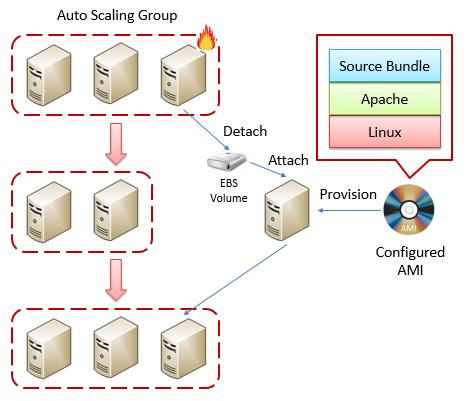
上图中展示了一个Auto Scaling Group中的一个实例出现故障时是如何对其进行恢复的。在一个虚拟机实例出现故障时,其将首先被从Auto Scaling Group移出,并且与之关联的EBS存储也将与之解除关联。该存储上可能记录了日志等一系列有关运行的数据。接下来,Amazon将通过预先配置好的AMI重新请求一台虚拟机。该AMI不仅仅包含了该虚拟机运行时所需要的操作系统,更包含了虚拟机运行时所需要的一系列配置好的组成,如其运行时所需要使用的Servlet Container以及运行于其上的Source Bundle(WAR包等)。这样一旦创建完毕,虚拟机中的大部分软件就已经被部署好了。这大大地减少了重新创建一台虚拟机所需要的时间。接下来,Amazon将会把刚刚从损坏的虚拟机上解除关联的EBS存储与新创建的虚拟机相关联,并将其添加到Auto Scaling Group中。这样Auto Scaling Group就拥有了原有数量的虚拟机。所有这一切都将在虚拟机发生故障后的几分钟内完成。
当然,一个AMI中到底包含了多少预定义信息也会影响虚拟机的启动速度。例如对于一个包含了操作系统,Servlet Container以及应用代码的AMI,Amazon只需要通过该AMI创建一个虚拟机并启动它即可。而对于只包含了操作系统的AMI,其启动之后还需要安装运行子服务所需要的一系列软件,从而可能需要较长的时间。反过来,一个包含了操作系统,Servlet Container以及应用代码的AMI常常需要更多的维护工作。因此到底如何制作并维护AMI也是一个蛮有意思的话题。只是由于该话题离Cloud Native较远,因此我们在这里将不再详述。如果您对此感兴趣,请参考Amazon论文《Managing your AWS Infrastructure at Scale》中的“Provision New EC2 Instances”一节。
反过来,让我们回想一下基于物理机的灾难恢复解决方案:在一个基于物理机的系统中,如果其中一台物理机不再正常工作,我们常常需要访问这台物理机,并尝试找到发生异常的原因。有时候我们还需要通过尝试重新启动系统等一系列操作来尝试恢复其工作。如果实在不行,那么我们就需要重新在该物理机上安装软件。之所以这么做,是因为我们只有有限的物理机,并且重新在物理机上创建系统是一个非常麻烦的事情。但是在云的帮助下,这个问题的解决方案就将变成“丢掉以前的,几分钟之内就能创建个新的”这种简单的逻辑。
也就是说,云的某些特性将显著地更改一系列解决方案的解决思路。Cloud Native应用需要充分地利用云所提供的这些功能,以提高效率。那这些物理机中所没有的特性有哪些呢?虚拟机的快速创建,更多更强的内置管理工具以及对自动化脚本的更好的支持。
这些特性会进一步发展为更高一层次的优点。就以虚拟机的创建为例:由于我们可以在云上快速地创建一台虚拟机,而且在不再需要时直接丢弃该虚拟机,而不像物理机时代需要几个小时甚至几天才能设置好。因此基于云的应用常常具有“灵活性”这一特征:虚拟机想要就请求,不要的时候就删除。
这些特性更可以进一步发展,从而推出一系列云所特有的解决方案。上面所介绍的基于Auto Scaling Group的吞吐量管理以及灾难恢复就是其中一个实例。
开发Cloud Native应用
在有了合适的设计之后,我们就可以开始计划开发您的Cloud Native应用了。此时我们可以从云平台上得到的好处有:原生云管理软件的支持,DevOps支持,甚至一些Cloud Native Framework等。
Amazon为我们提供了一系列用来对资源及应用进行管理的组件。迄今为止,这些组件有:CloudFormation,Beanstalk以及OpsWorks。三者的定位各有不同。
CloudFormation用来对云上的资源进行管理。首先,用户需要通过一个模板来描述所需要的所有种类的AWS资源以及这些资源之间的关系。一个简单的CloudFormation模板如下所示(自Amazon CloudFormation官方文档):
1 { 2 "Parameters" : { 3 "KeyName" : { 4 "Description" : "The EC2 Key Pair to allow SSH access to the instance", 5 "Type" : "AWS::EC2::KeyPair::KeyName" 6 } 7 }, 8 "Resources" : { 9 "Ec2Instance" : { 10 "Type" : "AWS::EC2::Instance", 11 "Properties" : { 12 "SecurityGroups" : [ { "Ref" : "InstanceSecurityGroup" }, "MyExistingSecurityGroup" ], 13 "KeyName" : { "Ref" : "KeyName"}, 14 "ImageId" : "ami-7a11e213" 15 } 16 }, 17 18 "InstanceSecurityGroup" : { 19 "Type" : "AWS::EC2::SecurityGroup", 20 "Properties" : { 21 "GroupDescription" : "Enable SSH access via port 22", 22 "SecurityGroupIngress" : [ { 23 "IpProtocol" : "tcp", 24 "FromPort" : "22", 25 "ToPort" : "22", 26 "CidrIp" : "0.0.0.0/0" 27 } ] 28 } 29 } 30 } 31 }
可以看到,上面的模板将用来创建一个EC2实例以及一个Security Group,并将其添加到刚刚创建的Security Group中。在使用该模板的时候,软件开发人员可以通过KeyName参数传入创建虚拟机时所使用的KeyPair。
在用户通过该模板创建资源时,CloudFormation会分析该模板中所记录的信息,并据此来分配并配置资源。如果软件开发人员对该模板进行了修改并提交,CloudFormation会根据用户所修改的配置对已经部署好的资源进行更新。同样地,我们也可以通过CloudFormation删除已经部署好的资源,那么这些之前分配好的资源都将被删除。
而Beanstalk则主要用来完成简单应用的部署。在使用Beanstalk在云上部署应用时,我们只需要上传该应用的Source Bundle,如WAR包,并提供一系列部署的信息,就能完成对应用的部署。此时用户并不需要关心资源分配,负载平衡,应用的容量扩展以及应用的监控等一系列问题。如果需要对应用进行更新,我们只需要上传新版本的Source Bundle并指定新的配置即可。在部署完成以后,我们就可以通过一系列管理工具,如AWS Management Console,对这些部署好的应用进行管理。
OpsWorks则是最为强大也是最为复杂的应用管理工具。软件开发人员可以为需要部署的应用定义一系列Layer,每个Layer表示一系列用于特定用途的EC2实例,如数据库实例。每个Layer中可以包含一系列Chef recipe,以用来在特定生命周期,如Setup,Configure,Deploy,Undeploy以及Shutdown等事件发生时执行特定任务,从而允许软件开发人员指定在这些生命周期执行的自定义逻辑。因为它是如此常用,因此我在想是不是有机会专门为该工具写一篇介绍的博客。
而这一系列部署工具同样也构成了基于AWS的DevOps的基础。再加上一系列其它代码管理工具如CodeCommit以及CodeDeploy等将可以构成完整的DevOps解决方案。因为我对CodeCommit以及CodeDeploy等产品了解并不多,因此在这里不加以详细介绍。如果希望对基于AWS的DevOps有更深入的了解,请看Amazon的一篇文章《Introduction to DevOps on AWS》。
除了这些之外,最近兴起的一个有关Cloud Native的话题就是Cloud Native Framework。如Airavata等。这些框架常常将一系列云所提供的功能包装起来。这样软件开发人员就可以将精力集中于业务逻辑的开发,而不再需要过多地关心如何正确地使用云这一类问题。有兴趣的读者可以持续地关注这一方面,毕竟是一个新兴起的符合大趋势的方向。
更多资源:
Cloud Native [email protected]: http://blogs.vmware.com/cloudnative/
Cloud Native Computing Foundation:https://cncf.io/
转载请注明原文地址并标明转载:http://www.cnblogs.com/loveis715/p/5185367.html
商业转载请事先与我联系:[email protected]
公众号一定帮忙别标成原创,因为协调起来太麻烦了。。。
以上是关于On cloud, be cloud native的主要内容,如果未能解决你的问题,请参考以下文章
微服务浪潮中,程序猿如何让自己 Be Cloud Native
微服务浪潮中,程序猿如何让自己 Be Cloud Native
分布式系统开发实战:Cloud Native架构,Cloud Native特性
spring.cloud.config.server.native.search-locations 不适用于 Spring Cloud Config 服务器中的占位符