CUDA入门1
Posted Tequila Sunrise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA入门1相关的知识,希望对你有一定的参考价值。
1GPUs can handle thousands of concurrent threads.
2The pieces of code running on the gpu are called kernels
3A kernel is executed by a set of threads.
4All threads execute the same code (SPMD)
5Each thread has an index that is used to calculate memory addresses that this will access.
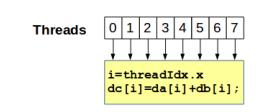
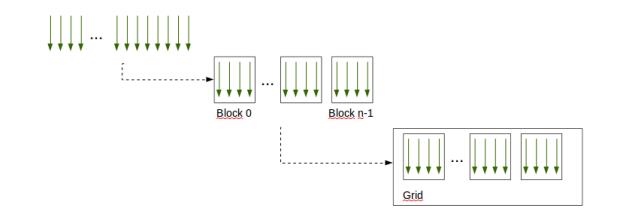
1Threads are grouped into blocks
2 Blocks are grouped into a grid
3 A kernel is executed as a grid of blocks of threads
Built-in variables ⎯ threadIdx, blockIdx ⎯ blockDim, gridDim

CUDA的线程组织即Grid-Block-Thread结构。一组线程并行处理可以组织为一个block,而一组block并行处理可以组织为一个Grid。下面的程序分别为线程并行和块并行,线程并行为细粒度的并行,而块并行为粗粒度的并行。addKernelThread<<<1, size>>>(dev_c, dev_a, dev_b);
1 #include "cuda_runtime.h" 2 #include "device_launch_parameters.h" 3 #include <stdio.h> 4 #include <time.h> 5 #include <stdlib.h> 6 7 #define MAX 255 8 #define MIN 0 9 cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size,int type,float* etime); 10 __global__ void addKernelThread(int *c, const int *a, const int *b) 11 { 12 int i = threadIdx.x; 13 c[i] = a[i] + b[i]; 14 } 15 __global__ void addKernelBlock(int *c, const int *a, const int *b) 16 { 17 int i = blockIdx.x; 18 c[i] = a[i] + b[i]; 19 } 20 int main() 21 { 22 const int arraySize = 100; 23 24 int a[arraySize] = { 1, 2, 3, 4, 5 }; 25 int b[arraySize] = { 10, 20, 30, 40, 50 }; 26 27 for (int i = 0; i< arraySize ; i++){ 28 a[i] = rand() % (MAX + 1 - MIN) + MIN; 29 b[i] = rand() % (MAX + 1 - MIN) + MIN; 30 } 31 int c[arraySize] = { 0 }; 32 // Add vectors in parallel. 33 cudaError_t cudaStatus; 34 int num = 0; 35 36 float time; 37 cudaDeviceProp prop; 38 cudaStatus = cudaGetDeviceCount(&num); 39 for(int i = 0;i<num;i++) 40 { 41 cudaGetDeviceProperties(&prop,i); 42 } 43 44 cudaStatus = addWithCuda(c, a, b, arraySize,0,&time); 45 46 47 printf("Elasped time of thread is : %f \\n", time); 48 printf("{%d,%d,%d,%d,%d} + {%d,%d,%d,%d,%d} = {%d,%d,%d,%d,%d}\\n",a[0],a[1],a[2],a[3],a[4],b[0],b[1],b[2],b[3],b[4],c[0],c[1],c[2],c[3],c[4]); 49 50 cudaStatus = addWithCuda(c, a, b, arraySize,1,&time); 51 52 53 printf("Elasped time of block is : %f \\n", time); 54 55 if (cudaStatus != cudaSuccess) 56 { 57 fprintf(stderr, "addWithCuda failed!"); 58 return 1; 59 } 60 printf("{%d,%d,%d,%d,%d} + {%d,%d,%d,%d,%d} = {%d,%d,%d,%d,%d}\\n",a[0],a[1],a[2],a[3],a[4],b[0],b[1],b[2],b[3],b[4],c[0],c[1],c[2],c[3],c[4]); 61 // cudaThreadExit must be called before exiting in order for profiling and 62 // tracing tools such as Nsight and Visual Profiler to show complete traces. 63 cudaStatus = cudaThreadExit(); 64 if (cudaStatus != cudaSuccess) 65 { 66 fprintf(stderr, "cudaThreadExit failed!"); 67 return 1; 68 } 69 return 0; 70 } 71 // Helper function for using CUDA to add vectors in parallel. 72 cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size,int type,float * etime) 73 { 74 int *dev_a = 0; 75 int *dev_b = 0; 76 int *dev_c = 0; 77 clock_t start, stop; 78 float time; 79 cudaError_t cudaStatus; 80 81 // Choose which GPU to run on, change this on a multi-GPU system. 82 cudaStatus = cudaSetDevice(0); 83 if (cudaStatus != cudaSuccess) 84 { 85 fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); 86 goto Error; 87 } 88 // Allocate GPU buffers for three vectors (two input, one output) . 89 cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); 90 if (cudaStatus != cudaSuccess) 91 { 92 fprintf(stderr, "cudaMalloc failed!"); 93 goto Error; 94 } 95 cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); 96 if (cudaStatus != cudaSuccess) 97 { 98 fprintf(stderr, "cudaMalloc failed!"); 99 goto Error; 100 } 101 cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); 102 if (cudaStatus != cudaSuccess) 103 { 104 fprintf(stderr, "cudaMalloc failed!"); 105 goto Error; 106 } 107 // Copy input vectors from host memory to GPU buffers. 108 cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); 109 if (cudaStatus != cudaSuccess) 110 { 111 fprintf(stderr, "cudaMemcpy failed!"); 112 goto Error; 113 } 114 cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); 115 if (cudaStatus != cudaSuccess) 116 { 117 fprintf(stderr, "cudaMemcpy failed!"); 118 goto Error; 119 } 120 121 122 // Launch a kernel on the GPU with one thread for each element. 123 if(type == 0){ 124 start = clock(); 125 addKernelThread<<<1, size>>>(dev_c, dev_a, dev_b); 126 } 127 else{ 128 start = clock(); 129 addKernelBlock<<<size, 1>>>(dev_c, dev_a, dev_b); 130 } 131 132 stop = clock(); 133 time = (float)(stop-start)/CLOCKS_PER_SEC; 134 *etime = time; 135 // cudaThreadSynchronize waits for the kernel to finish, and returns 136 // any errors encountered during the launch. 137 cudaStatus = cudaThreadSynchronize(); 138 if (cudaStatus != cudaSuccess) 139 { 140 fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\\n", cudaStatus); 141 goto Error; 142 } 143 // Copy output vector from GPU buffer to host memory. 144 cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); 145 if (cudaStatus != cudaSuccess) 146 { 147 fprintf(stderr, "cudaMemcpy failed!"); 148 goto Error; 149 } 150 Error: 151 cudaFree(dev_c); 152 cudaFree(dev_a); 153 cudaFree(dev_b); 154 return cudaStatus; 155 }
运行的结果是
Elasped time of thread is : 0.000010
{103,105,81,74,41} + {198,115,255,236,205} = {301,220,336,310,246}
Elasped time of block is : 0.000005
{103,105,81,74,41} + {198,115,255,236,205} = {301,220,336,310,246}
以上是关于CUDA入门1的主要内容,如果未能解决你的问题,请参考以下文章