JVM体系结构和工作方式
Posted wade&luffy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM体系结构和工作方式相关的知识,希望对你有一定的参考价值。
| 指令集 | 这个计算机所能识别的机器语言的命令集合。 |
| 计算单元 | 即能够识别并且控制指令执行的功能模块 |
| 寻址方式 | 地址的位数、最小地址和最大地址范围,以及地址的运行规则 |
| 寄存器定义 | 包括操作数寄存器、变址寄存器、控制寄存器等的定义、数量和使用方法 |
| 存储单元 | 能够存储操作数和保存操作结构的单元,如内核级缓存、内存和磁盘等 |
JVM体系结构分析
| 类加载器 | 在JVM启动时或者是在类运行时将需要的class文件加载到JVM中 |
| 执行引擎 | 负责执行class文件中包含的字节码指令,相当于实际机器上的CPU |
| 内存区 | 将内存划分为若干个区以模拟实际机器上的存储、记录和调度功能模块 |
| 本地方法调用 | 调用C或C++实现的本地方法的代码返回结果 |
JVM的工作机制
再将结果存入其中一个寄存器即可,不需要这么多的数据移动的操作。
执行引擎的架构设计
每当创建一个新的线程时,JVM会为这个线程创建一个Java栈,同时会为这个线程分配一个PC寄存器,并且这个PC寄存器会指向这个线程的第一行可执行代码。每当调用一个新方法时会在这个栈上创建一个新的栈帧数据结构,这个栈帧会保留这个方法的一些元信息,如在这个方法中定义的局部变量、一些用来支持常量池的解析、正常方法返回及异常处理机制等。JVM在调用某些指令时可能需要使用到常量池中的一些常量,或者是获取常量代表的数据或者这个数据指向的实例化的对象,而这些信息都存储在所有线程共享的方法区和Java堆中。
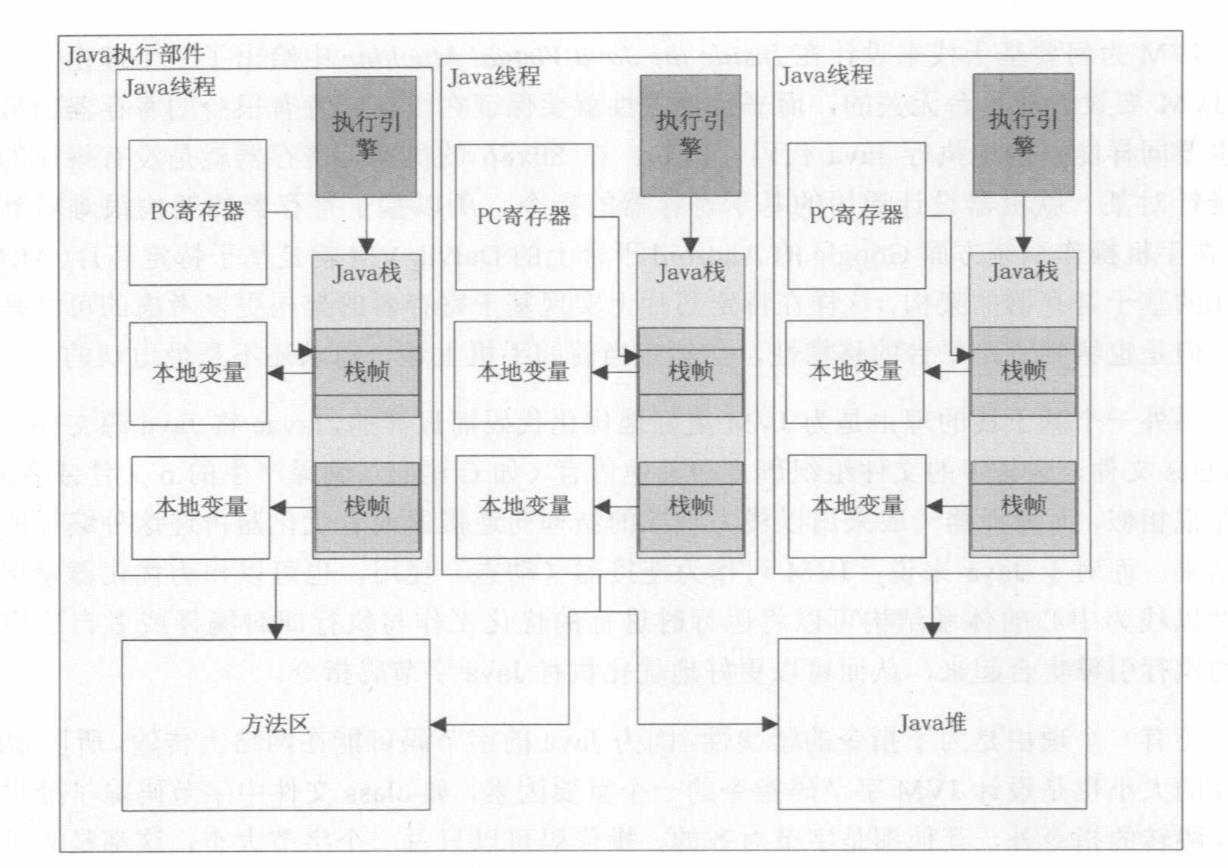
单一执行过程举例
public class Math { public static void main(String[] args) { int a=l; int b=2; int c = (a+b)*10; } } 偏移量 指令 说明 0: iconst_1 常数1入栈 1: istore_1 将栈顶元素移入本地变量1存储 2: iconst_2 常数2入栈 3 : istore_2 将栈顶元素移人本地变量2存储 4: iload_1 本地变量1入栈 5: iload_2 本地变量2入栈 6: iadd 弹出栈顶两个元素相加 7: bipush 10 将 10 入栈 9: imul 栈顶两个元素相乘 10: istore_3 栈顶元素移入本地变量3存储 11: return 返回
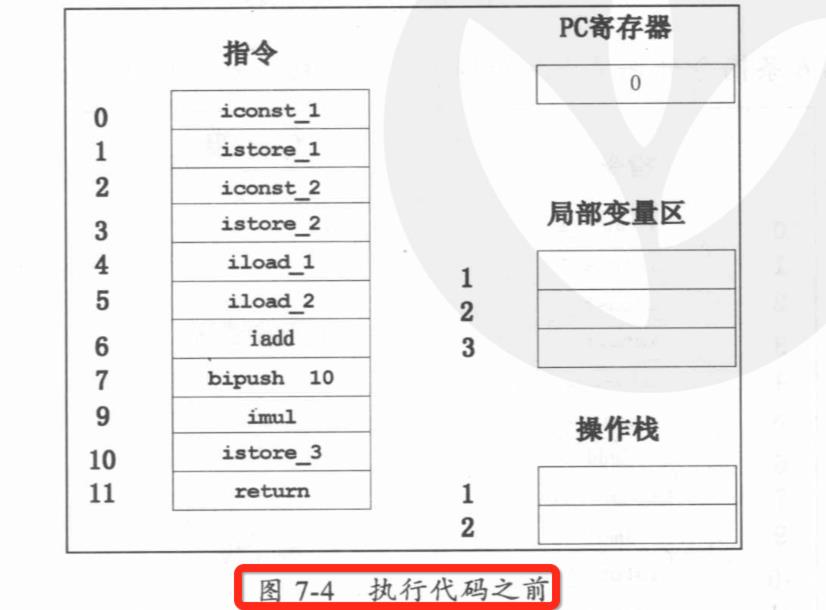
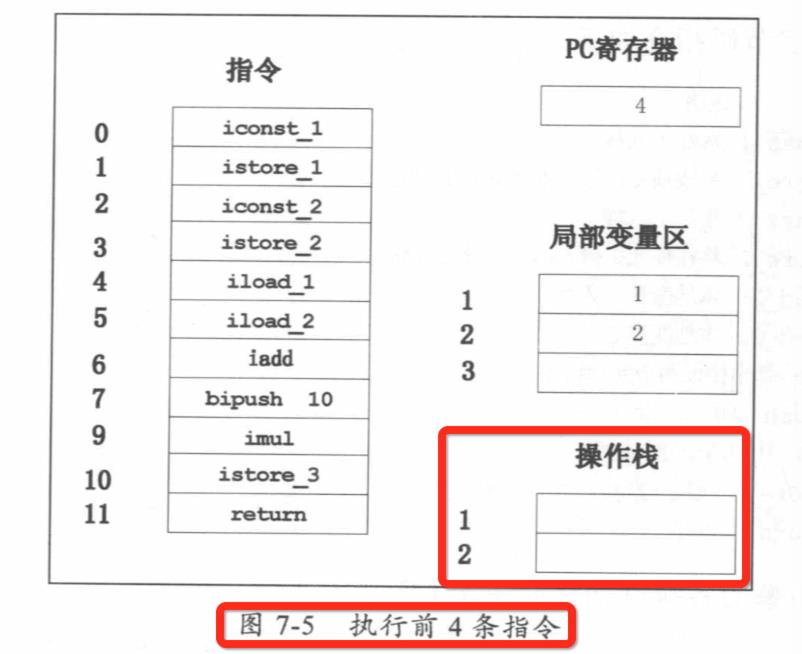
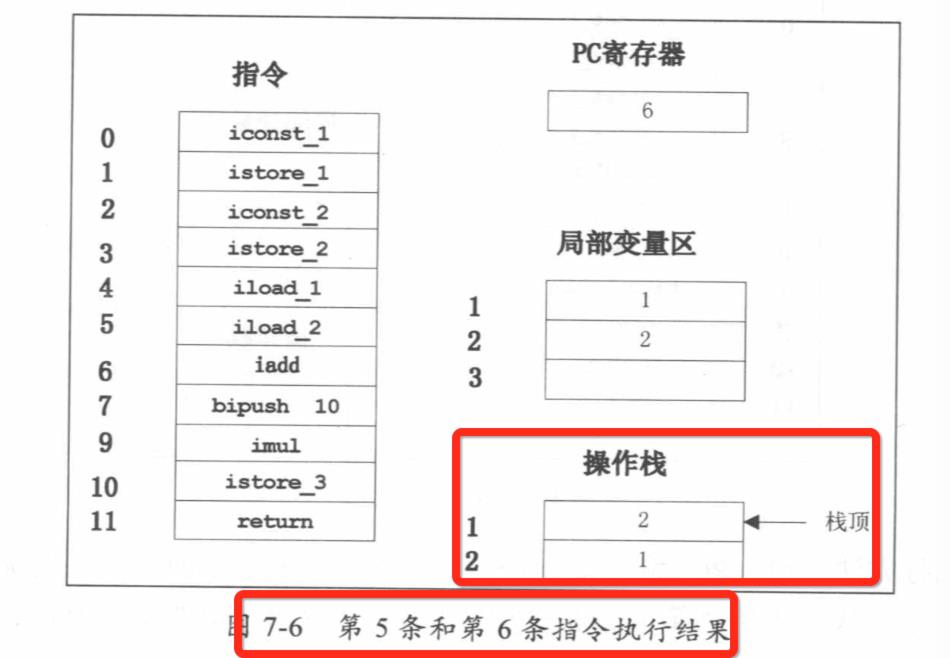
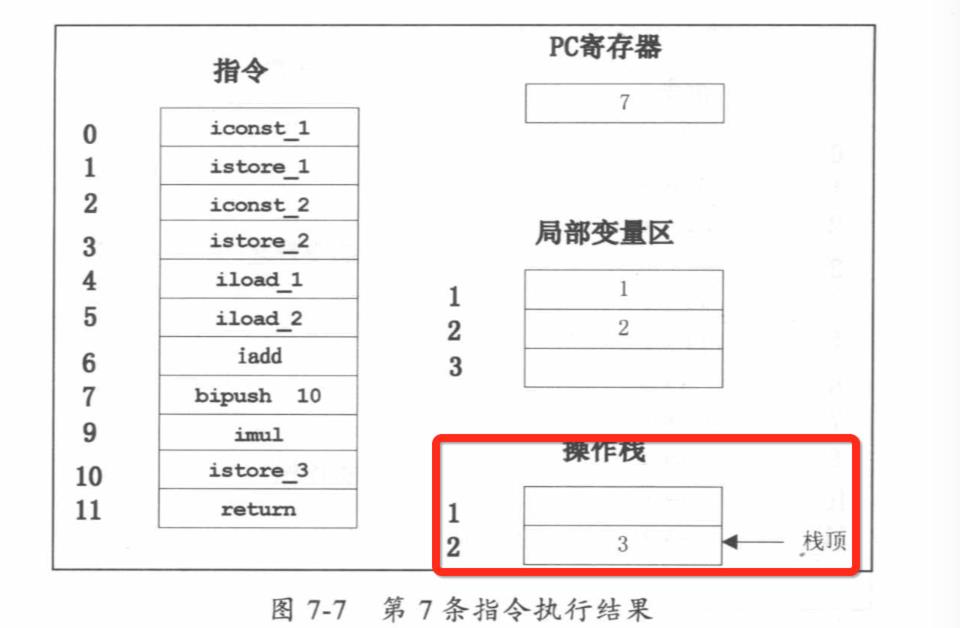
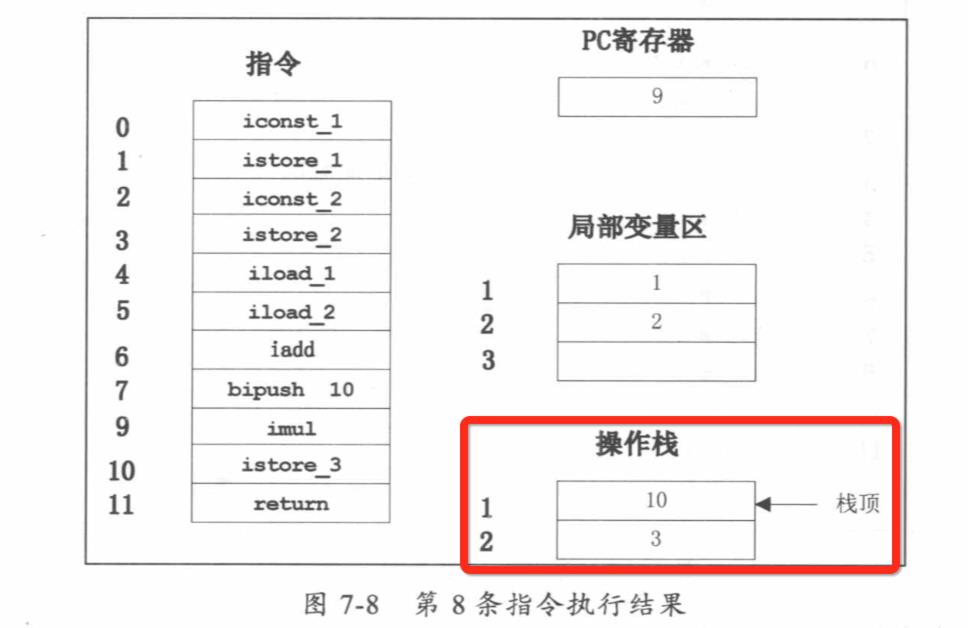
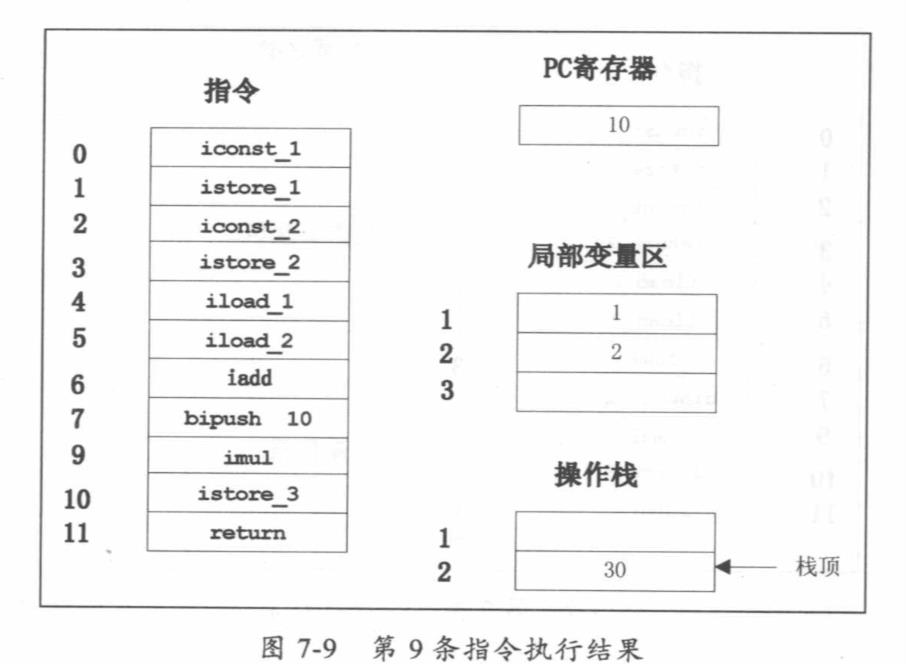
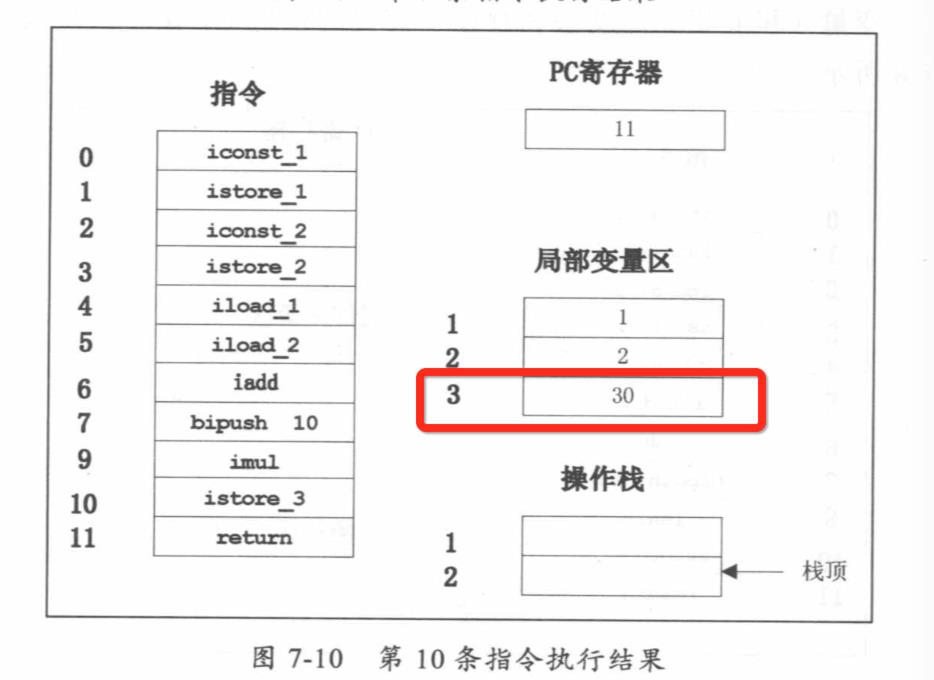
JVM方法调用栈举例
JVM的方法调用分为两种:一种是Java方法调用,另一种是本地方法调用。本地方法调用由于各个虚拟机的实现不太相同,所以这里主要介绍Java的方法调用情况。
public class Math { public statie void main(String[] args) { int a=1; int b=2; int c = math(a,b)/10; } public static int math(int a,int b){ return (a+b)*10; } } public static void main(java.lang.String[]}; Code: 0: iconst_1 1: istore_1 2: iconst_2 3: istore_2 4: iload_1 5: iload_2 6: invokestatic #2; //Method math:(II) 9: bipush 10 11: idiv 12: istore_3 13: return public static int math{int int); Code: 0: iload_0 1: iload_1 2: iadd 3: bipush 10 5: imul 6: ireturn

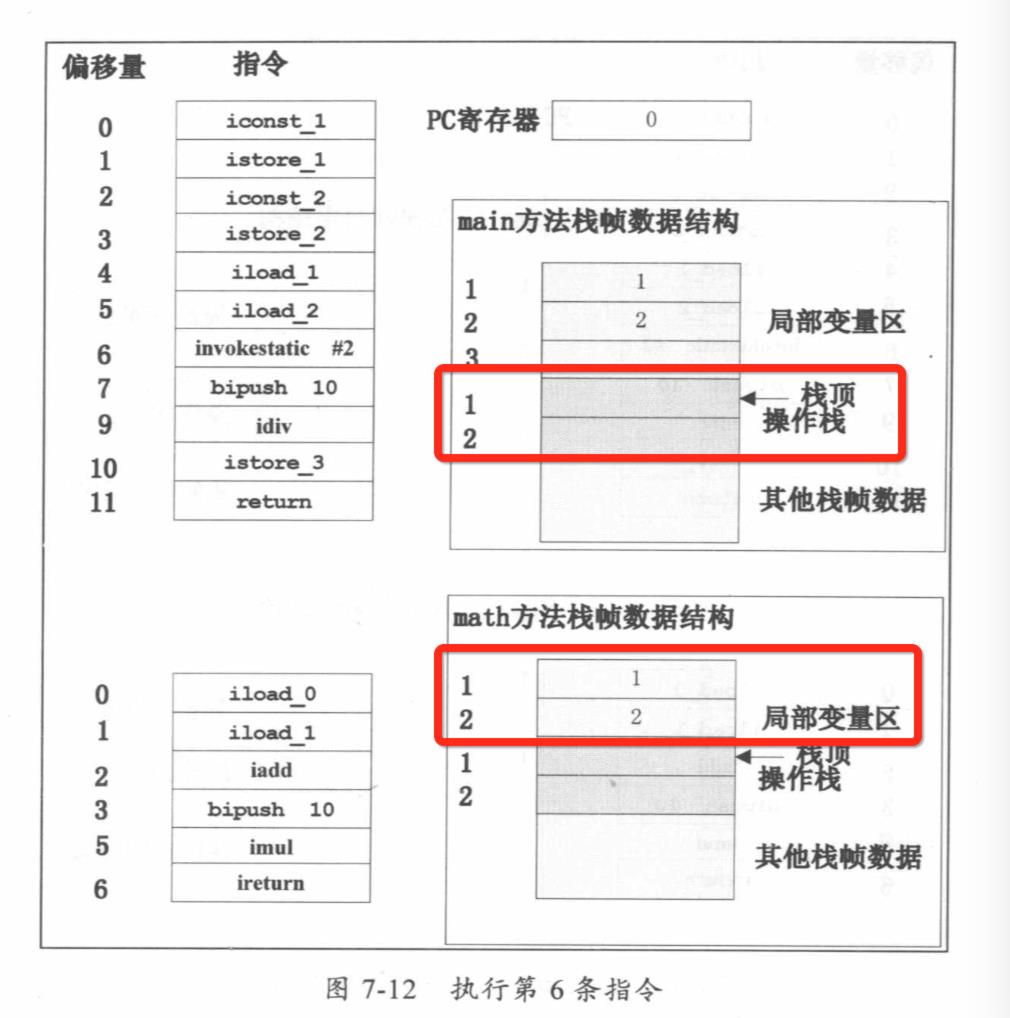



当JVM执行main方法时,首先将两个常数1和2分别存锗到局部变量区1和2中,然后调用静态math方法。从math的字节码指令可以看出,math的两个参数也存储在其对应的方法栈帧中的局部变量区0和1中,先将这两个局部变量分别入栈,然后进行相加操作再和常数10相乘,最后将结果返回。
当执行invokestatic指令时JVM会为math方法创建一个新的栈帧,并且将两个参数存在math方法对应的栈帧的前两个局部变量区中,这时PC寄存器会清零,并且会指向math方法对应栈帧地第一条指令地址,执行invokestatic指令时,创建了一个新的栈帧,这时栈帧中的局部变量区中已经有两个变量了,这两个变量是从mam方法的栈帧中的操作栈中传过来的。当执行math方法时,math方法对应的栈帧成为当前的活动栈帧,PC寄存器保存的是当前这个栈帧中的下一条指令地址,所以是0。math方法先将a、b两个变量相加,再乘以10,最后返回这个结果执行到第5条指令的状态,math的操作栈中的栈顶元素相乘的结果是30,最后一条指令是ireturn,这条指令是将当前栈帧中的栈顶元素返回到调用这个方法的栈中,而这个栈帧也将撤销,PC寄存器的值恢复调用桟的下一条指令地址, main方法将math方法返回的结果再除以10存放在局部变量区3中,当执行return指令时main方法对应的栈帧也将撤销,如果当前线程对应的Java栈中没有栈帧,这个Java栈也将被JVM撤销,整个JVM退出。
入栈
以上是关于JVM体系结构和工作方式的主要内容,如果未能解决你的问题,请参考以下文章