信息论小记
Posted dnbc66
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息论小记相关的知识,希望对你有一定的参考价值。
一、首先考虑一个离散的随机变量x;当我们观测到这个随机变量的某一个具体值的时候,我们需要考虑这个值给予了我们多少信息,这个信息的量可以看成是在学习x的值的时候的“惊讶程度”(degree of surprise)。如果我们知道事件A一定会发生,那么我们就不会收到关于该事件的信息;如果一件相当不可能的事情发生了,我们将接收到很多信息。、
显然,我们对于信息内容的度量将依赖于概率分布p(x),因此我们要找到一个函数h(x),它是p(x)的单调递增函数,表示信息的内容,概率学给出了这个公式:
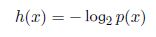
负号确保信息一定是非负数,低概率事件x对应于高的信息量。下面给出的是平均信息量的计算公式:
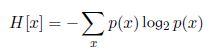
这个量就是著名的“熵”,对数取2为底数的话熵的单位是bit.条件熵公式如下,即给定x,y的条件熵:
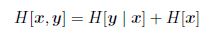
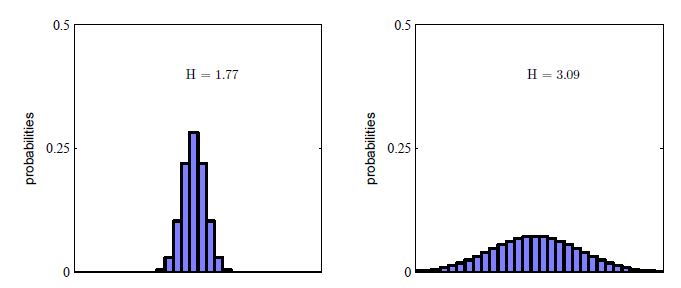
如下图所示,如果概率分布p(x)集中于几个值,那么熵就会比较低,如果分布比较均匀,则熵值会比较高,如果有某一个值使得p(x)=1,则熵值为0.
二、相对熵;
考虑某个未知的分布p(x),假定我们已经使用一个近似的分布q(x)对它进行了建模。如果我们使用q(x)来建立一个编码体系,用来把x的值传给接收者,那么,由于我们使用了q(x)而不是真实分布p(x),因此在具体化x的值时,我们需要一些附加的信息。我们需要的平均的附加信息量(单位是nat,底数为e)为:
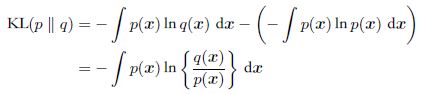
这被称为分布p(x)和分布q(x)之间的相对熵(relative entropy) 或者Kullback-Leibler散度,值恒为非负数。
三、互信息;
相对熵表示两个随机分布之间距离的度量,或者说是两者之间的差异。互信息是随机变量包含另一个随机变量信息量的度量。互信息也是在给定另一个随机变量情况下,原随机变量不确定度的缩减量:
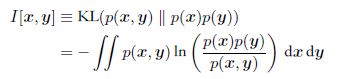
四、相对熵和互信息的关系;
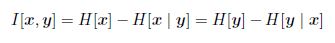
因此我们可以把互信息看成由于知道y值而造成的x的不确定性的减小(反之亦然)。从贝叶斯的观点来看,我们可以把p(x)看成x的先验概率分布,把p(x|y)看成我们观察到新数据y之后的后验概率分布。因此互信息表式一个新的观测y造成的x的不确定性的减小。
以上是关于信息论小记的主要内容,如果未能解决你的问题,请参考以下文章