概率--学习朴素贝叶斯分布
Posted 彭谨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了概率--学习朴素贝叶斯分布相关的知识,希望对你有一定的参考价值。
概率是一种基于事件发生可能性来描述未来趋势的数学工具。其本质就是通过过去已经发生的事情来推断未来事件,并且将这种推断放在一系列的公理化的数学空间当中进行考虑。例如,抛一枚均质硬币,正面向上的可能性多大?概率值是一个0-1之间的数字,用来衡量一个事件发生可能性的大小。概率值越接近于1,事件发生的可能性越大,概率值越接近于0,事件越不可能发生。天气预报员通常会使用像"明天80%的可能性会下雨"这样的术语来对降雨进行预测,这里70%或者0.7就是下雨的概率。在现实生活中,要么下雨,要么不下雨。用数学来进行描述,就是事件发生的结果要么是1(下雨),要么是0(不下雨),但是,由于我们需要预测的事件尚未发生,我们就只能通过测量类似大气条件的方法得到的前几天下雨的概率。因此,70%下雨的可能性意味着,在过去有类似天气特征的10个例子中,有7次在该地区的某个地方下雨。
到目前为止,对于多个因素影响的动力学过程,并没有一种方法能够完全精确模拟。在十八世纪,当科学家们开始研究三个或者三个以上的物体在空间的运动规律的时候就发现。对于这些物体的运动轨迹进行描述和预测,需要大量的迭代运算。运算过程中的微小误差在后期会被迅速放大,从而使得物体的运动状态和实际运动结果出现明显偏差。包括庞加莱,吉布斯等数学家对这一现象的研究表明,这种复杂演化的结果不可能被精确模拟。但是这些运动的内在的规律又必然通过一定的表面偶然性表现出来。数学家门用概率来描述这种偶然性。概率从它被提出开始,这种模糊与精确之间关系一直困扰着各种概率现象的研究者。最终,柯尔莫格罗夫等人将概率理论公理化,将概率现象转化为了在测度空间中发生的几何学问题。让概率论这种基于类比的模糊研究转化为了一套逻辑严密的数学体系。
类似现象也存在于大量的生物学和医学现象当中。本章将会讲述一种基于概率理论的机器学习算法,即根据概率原则进行分类的朴素贝叶斯算法。朴素贝叶斯算法就是应用先前事件的有关数据来估计未来事件发生的概率。举个例子,朴素贝叶斯的一个常见应用就是根据过去的病案文档中的单词使用的频率来识别新的病案文档。并且对病案文档的描述疾病种类进行预测。
为了让读者更容易的理解贝叶斯分析,本章中一开始会对统计学和概率论的知识进行回顾。即帮助读者重新整理一些概率论的知识。然后再进入贝叶斯分析的学习。
4.1. 知识的回顾
古典的概率
最早关于概率的思考是有关赌博的。赌徒们总是通过各种带有随机性的游戏来获得更多的利益。在这些游戏当中,赌徒们总是在思考两类问题:
1.在特定规则下,输赢的概率分别是多少。这个问题实际上是想推测各种出现情况的总体分布。赌徒们很早就知道,抽三张扑克牌,拿到同样花色(术语叫做同花)的概率比拿到不考虑花色只考虑点数的345(术语叫做杂顺)这样连续的点数要困难。各种排列组合的难易程度的估计有助于赌徒判断自己牌型的好坏。
2.在已经出现了特定结果的情况下,继续发生特定事件的概率是多少。如某人已经在5局赌博当中胜利了4次,他是否应该继续读下去获得更大的战果,还是应该根据现有的局面见好就收。
对于上述第一类问题的思考,可以发现,第一类问题的答案取决于赌博的规则。而第二类问题不但取决于赌博的规则,还取决于你现在已经发生的状态。比如手气是否足够好,以往的人们在类似的情况下不同选择获得的不同结局。
对于这两类问题的进一步思考最终导致了两种不同的统计学研究范式:前者认为,所有的随机过程的概率分布取决于过程的内部特性。我们把这类统计学研究范式称为古典概率统计学。而对于第二类问题的研究,则带来了另外一个类型的统计学研究--基于贝叶斯方法的统计学。
古典概率通常又叫事前概率,是指当随机事件中各种可能发生的结果及其出现的次数都可以由演绎或外推法得知,而无需经过任何统计试验即可计算各种可能发生结果的概率。比如我们抛硬币的时候,如果硬币质地均匀,抛硬币手法规范,那么正面和反面的出现概率就一定是各占50%。哪怕是连续抛出了100次正面,第101次出现正面的概率也还是50%。
而基于贝叶斯方法的统计学则不然,如果我们只观察到了100次抛硬币,哪怕是我们承认硬币没有问题,抛硬币的手法也非常规范,但是连续出现100次正面这一现象本身就足以让我们考虑是否有硬币之外的原因在影响抛硬币的结果。因此,我们再考虑接下来抛硬币的结果的时候,需要引入另外一种被称为"主观概率"的概念。也就是说前面100次的正面让我们必须考虑到一些其它的类似"手气"的因素。
主观概率的引入看起来在数学上不太规范,有一种在问题解决到一半的情况下强行增加条件的感觉。但是实际上,在实际工作中,很多问题并不会像投硬币一样简单,以至于我们可以对其概率产生的原理进行充分分析。如我我们对某种现象的观测的次数有限,此时的确需要通过已经发生的事情来对未发生的事情进行进一步判断。
古典概率虽然更严谨,但是只适合对那些已经充分掌握了发生机理的随机过程,拥有几乎无限次观测经验的事件进行总结。而如果要通过已知的有限观测结果来预测未发生的事情,则需要引入贝叶斯方法。
4.2 理解朴素贝叶斯和分类
朴素贝叶斯算法起源于18世纪数学家托马斯·贝叶斯(Thomas Bayes)的工作,贝叶斯发明了用于描述事件在已知的一系列事件发生的情况下发生的概率以及如何根据各种增加的附加信息修正概率的基本数学原理(现称为贝叶斯方法)。
利用贝叶斯算法可以通过已知条件来预测未知发生的事情。如果把已知条件理解为贝叶斯的先验概率分布,需要预测的结局看成是一种分类结果。那么利用贝叶斯算法对样本进行分类就被成为贝叶斯分类。朴素贝叶斯分类器(Naive Bayes classifier),是一种简单有效的常用分类算法。
分类问题本质上都是构造某种映射规则,即通过已经发生的变量建立一个映射函数来预测未知变量。一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
基于贝叶斯方法的分类器是利用训练数据并根据特征的取值来计算每个类别被观察到的概率。当分类器之后被应用到无标签数据时,分类器就会根据观测到的概率来预测新的特征最有可能属于哪个类。这是简单的想法,但根据这种想法就产生了一种方法,这种方法得到的结果与很多复杂算法得到的结果是等价的。在医学上贝叶斯分类器已用于以下方面:
-
文本分类,比如垃圾邮件过滤、作者识别和主题分类等。
-
在计算机网络中进行入侵检测或者异常检测。
-
根据一组观察到的症状,诊断身体状况。
通常情况下,贝叶斯分类器最适用于解决这样一类问题:在这类问题中,为了估计一个结果的概率,从众多属性中提取的信息应该被同时考虑。尽管很多算法忽略了具有弱影像的一些特征,但是贝叶斯方法利用了所有可以获得的证据来巧妙地修正预测。如果有大量特征产生的影响较小,但将它们放在一起,它们的组合影响可能会相当大。
4.2.1 贝叶斯定理
在进入朴素贝叶斯算法学习之前,我们值得花一些时间来定义一些概念,这些概念在贝叶斯方法中经常用到。用一句话概括,贝叶斯概率理论植根于这样一个思想,即一个事件的似然估计应建立在手中已有证据的基础上。事件(event)就是可能的结果,比如晴天和阴天、抛掷一枚硬币得到的正面或者反面、垃圾电子邮件和非垃圾电子邮件等。试验(trial)就是事件发生一次的机会,比如某天的天气、抛掷一枚硬币、一封电子邮件等。
贝叶斯分类的基础是贝叶斯定理,这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:

这个公式是贝叶斯分布的最基本也是最好理解的公式。比如我们想知道被医学检验结果诊断为阳性(事件B)的条件下,某人真的是某种疾病(事件A)的几率。就需要考虑所有诊断为阳性的人当中,的确是某疾病的人有多少。而这个比例实际上就是所有诊断为阳性并且的确是某疾病的概率和所有诊断为阳性的人之比。所有诊断为阳性,且的确是某种疾病的人,则可以理解为诊断阳性(B)和患病(A)同时发生表示为P(AB)。
更进一步,两件事情同事发生的概率P(AB),实际上等于某一件事情独立发生的概率(P(A))和在A发生的情况下B发生的概率(P(B|A))的乘积,因此有贝叶斯定理是关于条件概率的定理,其公式如下:

公式中P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(A)是A的先验概率或边缘概率(Prior probability)。代表着我们想考察事件在自然界中的一般分布。
P(B)是B的先验概率或边缘概率,又称为标准化常量(Normalized constant)。代表着我们已经知道的条件B在自然界当中的一般分布。
P(B|A) 是已知A发生后B的条件概率,叫做似然函数(likelihood)也由于得自A的取值而被称作B的后验概率。代表在已经发生的各种情况中,我们想考察的事件A是否经常伴随着条件B出现。
必须指出,即使事件A经常伴随着条件B出现,也不能说明条件B的出现一定意味着A会出现。因为如果条件B是一种非常常见的现象,那么条件B出现与否和A事件发生的关系也不会太大,因此我们可以将P(B|A)/ P(B)理解为调整因子,也被称为标准化似然度(standardised likelihood)。此时公式可以变为:

通过上述的推导可以看出,如果我们想考虑条件B发生之后事件A会发生的概率,我们可以通过观察以前每次事件A发生的时候B伴随的概率以及估计B和A发生的独立概率来 对上述问题进行判断。
贝叶斯推断中有几个关键的概念需要说明下:
-
第一个是先验概率,先验概率是一种分布,可以理解为我们一般条件下我们认为某件事情是不是经常发生。
-
第二个是似然函数,似然函数是对某件事发生的可能性的判断,与条件概率正好相反。似然函数是给定某一参数值,求某一结果的可能性。可以理解为以前长期观察得到的两者相关概率。例如:概率是抛一枚匀质硬币,抛10次,问6次正面向上的可能性多大?而似然函数是问抛一枚硬币,抛10次,结果6次正面向上,问其是匀质的可能性多大?
-
第三个是调整因子:调整因子是似然函数与先验概率的比值,这个比值相当于一个权重,用来调整后验概率的值,使后验概率更接近于真实概率。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易通过对以往的事情观测直接得出P(A|B),而P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。贝叶斯推断可以理解为通过先验概率和调整因子来获得后验概率。
后验概率 = 先验概率 × 调整因子
举个例子:
某青年人在参加单位组织的体检时,被检出HIV呈阳性。这自然会让这人感到极度震惊。
假设整个人群感染HIV的概率是0.08%。这家医院使用的检测方法正确率是99%(也就是对已经确诊携带HIV病毒的病人检测出阳性的概率是99%(true positive rate),对没有携带HIV病毒的人检测呈阴性的概率也是是99%(true negative rate))。那么我们用贝叶斯定理可以计算出计算一下小李的患病概率。假设A表示携带HIV病毒事件,B表示检测结果呈阳性事件,那么我们要求解的就是在检测结果呈阳性的情况下的真实患病概率,即 P(A|B)。P(A)表示患病概率,在我们的例子里是0.08%。P(B|A)表示一个人已确诊患病,检测呈阳性的概率是多少,从例子里知道P(B|A)=99%。P(B)表示随机一个人被检测呈阳性的概率是多少,这包括两部分的数据,一部分是患病且被检测呈阳性的概率,它的数值是0.08%×99%,另一部分没患病但被检测呈阳性的概率,它的数值是(1-0.08%)×(1-99%)。根据贝叶斯定理:
 =7.34%
=7.34%
从中我们可以看出,如果人群中HIV感染率很低,那么即使是用一种正确率为99%的方法来检测,此人感染了HIV的概率并不高。
而感染概率并不高的原因则是因为我们假设的人群中HIV感染艾滋病的概率仅仅为0.08%。如果我们假设此人属于某个感染率为10%的高危群体,那么此时此人感染的概率就会高达91%。读者不妨可以根据上面的公式自己计算。
同样原理,如果此人为了确诊自己是否真的患病,用同样方法再检测了一次,依然是阳性,那么根据上面的公式:
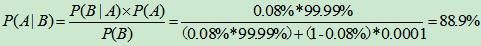
此时我们可以看出,不做任何其它调查,如果再一次检验同样也是阳性,那么该患者感染了HIV的可能性则会急剧上升到88.9%。因此在临床上我们也经常会看到,对于某些重大疾病的诊断和确诊,增加一次检测,就可以得到准确得多的结果。而通过问诊、查体等一般性的活动,采集一些不能确诊的病案信息,对于最后的确诊也是大有好处。
4.2.2 朴素贝叶斯算法
朴素贝叶斯(Naive Bayes,NB)算法描述应用贝叶斯定理进行分类的一个简单应用。它的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,我们可以举这样一个例子:你在校医院的门诊看到一个学生有点发烧,一般状况尚可。此时在不做其它临床检测的情况下判断该学生最有可能是什么疾病。作为一名有一定临床经验的医生,你十有八九会猜是普通感冒。为什么呢?因为常识告诉我们,到校医院来看病的患者最常见的就是普通感冒。当然患者也有可能是流感甚至肿瘤这样的发热性疾病,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
特别地,朴素贝叶斯假设数据集的所有特征都具有相同的重要性和独立性,而在大多数的实际应用中,这些假设是鲜有成立的。然而,在大多数情况下,当违背这些假设时,朴素贝叶斯依然可以很好地应用,甚至在极端事件中,特征之间具有很强的依赖性,朴素贝叶斯也可以用。由于该算法的通用性和准确性,适用于很多类型的条件,所以在分类学习任务中,朴素贝叶斯算法往往是很强大的,排在候选算法的第一位。
利用贝叶斯原理当连续的几个独立变量出现在一个患者身上的时候,贝叶斯算法能够帮助我们以相对简单的方法获得患者的重要患病概率。
连续贝叶斯
连续朴素贝叶斯分类的定义如下:
-
设X={a1,a2,...,am}为一个待分类项目,而每个a为X的一个特征属性值。我们可以把X理解为一个新的病人,我们已经采集到了他的身高,职业,年龄等各种不相关的临床参数。
-
有分类集合C={y1,y2,...,yn},这个分类集合可以看成病人需要诊断的临床结局,比如可以假定y1=感冒,y2=脑震荡
-
计算先验概率:P(y1|x),P(y2|x),...,P(yn|x).也就是各种参数在该病人身上的发生概率。也就是条件概率
-
如果P(yk|x)=max{P(y1|x),P(y2|x),...,P(yn|x)},则x∈yk.
要计算第三步的条件概率,可以通过建立一些已经知道分类情况的样本来形成训练样本集。然后根据公式

来计算条件概率。在这个公式里面Px是发病率,对于所有类别都是常数,所以我们只需要将分子设法最大化皆可。又因为各特征属性是条件独立的。所以有:

也就是说,只需要把特定临床结局下各症状的概率用连乘乘起来,再乘以该特定临床结局的先验分布,就可以获得在特定一系列症状下该临床结局的概率。
4.3.1 第一步,收集数据
为了使用贝叶斯分类器来对生物数据分类,我们采用最经典的生物学数据集iris来考察贝叶斯分析如何对不同性状的生物进行分类,该数据集可以在MATLAB自带的工具包中找到,也可以在网站()上下载。Iris数据集是1936年由FISHER通过测量鸢尾花的是一类多重变量分析的数据集。数据集总共有5个变量,前面四个变量分别为:花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性,最有一个变量说明花朵来自:山鸢尾Setosa,杂色鸢尾Versicolour和 弗吉尼亚鸢尾Virginica三个种类中的哪一类。在默认模式下安装的matlab可以通过在命令行直接输入load fisheriris命令获得:
load fisheriris
数据集总共有两组数据,一组命名为meas分别是花朵属性,另外一组命名为species是cell类型的变量,用文字说明每组鸢尾花的归属。总共有150组数据。三种鸢尾花每种测量了50朵。运行结束之后可以看到workspace窗口当中多出这两个变量

4.3.2 第二步 探索和准备数据
构建分类器的第一步涉及到原始数据的分析和处理。作为一种成熟的分析的数据集,首先需要对数据分布进行了解。Matlab有很多可以对数据分布进行观测的函数或者工具对本身的数据。例如你可以在命令行输入plot matrix
Plot matrix

此时获得的图形表示变量meas当中四列数据相互之间的的关系,如第一行第二列的数据表示的就是meas当中,花萼长度和花萼宽度之间的关系。从数据的分布来看,相关性并不算太强。而第一行第三列表示的则是花萼宽度和花瓣长度之间的关系,点呈线状分布表明这两个变量之间的关系相对较为密切。整个图上对角线上的小图表示每个变量的分布频率。从中我们可以看出花萼的长度和宽度基本符合正态分布,而花瓣的长度和宽度则不符合正态分布。
4.3.3 第三步 基于数据对模型进行训练
Matlab有多种统计学模型的训练方法。但是总体上说,所有的统计学模型的训练都可以分为两个步骤,训练和预测。具体到贝叶斯判别分析,这两个部分可以解释为:
-
训练:利用已有的数据,估计出基于贝叶斯分布的概率分布参数
-
预测:在新的数据加入之后,根据上述估计出的分布概率参数,计算出新样本属于某一个类别的先验概率。对于判别分析来说则可以计算出新来的样本属于哪一类分类的概率。随着条件分布的不断改变,标本属于特定分类的概率也会不断改变。
在matlab命令行中输入如下代码
load fisheriris
X = meas
Y = species;
Mdl = fitcnb(X,Y,\'ClassNames\',{\'setosa\',\'versicolor\',\'virginica\'})
可以对数据集进行贝叶斯判断建模,建模生成的Mdl是一个分类对象,这个对象的属性如下:

Matlab是一种面向对象的编程语言,我们获得的变量Mdl就是一个贝叶斯模型分类对象(ClassificationNaiveBayes object),这个对象有很多属性。例如属性PredictiorNames属性代表用于建模的变量名字,而DistributionParameters代表的是每分类花朵的两个变量的平均值和样本标准差。利用Mdl.DistributionParameters Mdl.ClassNames这样在对象后面加点的方法可以引出这些对象的属性值。而输入method(lassificationNaiveBayes)则可以查看对上述对象可以使用何种方法进行处理。利用MDL对象,可以对整个贝叶斯分类器的数据分布进行估计。
在默认情况下,朴素贝叶斯分类模型会认为模型当中的每个分类都是正态分布。每个分布都有一个平均值和样本标准差。我们可以在Mdl对象的DistributionParameters属性当中获得这些分布值,例如可以用:
Mdl.DistributionParameters{1,2}
ans =
3.4280
0.3791
来引入第一个分类第二个变量的分布,也就是说\'setosa\'的分类的变量的花萼宽度平均值是3.428和标准差0.379.根据统计学知识我们可以知道,如果我们知道了一个正态分布变量的均质和标准差,实际上也就知道了这个变量的分布规律,甚至可以估计出特定长度的花蕊属于这个分布的百分比。因此根据该变量的分布知道了特定变量的分布,实际上就获得了贝叶斯原理非常重要的概率似然率:P(h|D)。
Mdl1是一个对象,这个对象叫做分类对象。通过对第一章关于面向对象编程的相关知识学习可以知道,可以用methods(\'ClassificationNaiveBayes\')来查看这个对象可以使用各种方法:
methods(\'ClassificationNaiveBayes\')
Methods for class ClassificationNaiveBayes:
compact crossval logP margin resubEdge resubMargin compareHoldout edge loss predict resubLoss resubPredict
其中resubPredict方法可以用分类器来对数据进行分类。例如我们用
Ypredict = resubPredict(Mdl);
Ypredict
就可以获得在上述模型判别下面所有的Y分类变量数值。更进一步,如果我们用
[label,Posterior,Cost] = resubPredict(Mdl)
语句,就可以获得整个模型的分类标记,后验概率,和期望的错误分类代价数值,如果我们输入
>> Cost(52,:)
ans =
1.0000 0.0571 0.9429
这就表示第52个样本属于setosa错误的可能性是100%,属于versicolor错误的可能是0.05%,属于virginca 错误的可能是94%,很明显,这个样本最可能的是属于versicolor. 但是也有一定可能属于virginca.利用类似的的方法,我们不但可以对样本进行分类预测,还可以给出每一类预测犯错误或者正确的概率。
我们甚至可以对整个模型数据分布进行预测。模型数据分布进行估计,输入以下语句:
figure
gscatter(X(:,1),X(:,2),Y);
h = gca;
xylim = [h.XLim h.YLim]; % 找出作图X轴和Y轴的合理最大值
hold on
Params = cell2mat(Mdl.DistributionParameters);
Mu = Params(2*(1:3)-1,1:2); % Extract the means
Sigma = zeros(2,2,3);
for j = 1:3
Sigma(:,:,j) = diag(Params(2*j,:)); % Extract the standard deviations
ezcontour(@(x1,x2)mvnpdf([x1,x2],Mu(j,:),Sigma(:,:,j)),...
xylim+0.5*[-1,1,-1,1]) ...
% Draw contours for the multivariate normal distributions
end
title(\'Naive Bayes Classifier -- Fisher\'\'s Iris Data\')
xlabel(\'Petal Length (cm)\')
ylabel(\'Petal Width (cm)\')
hold off
可以获得贝叶斯分布当中每一类变量的置信区间。

从上图可以看出不同种类的鸢尾花,其花瓣长度和宽度分布各不相同,其中versicolor和virginica的花瓣长宽分布有重叠,而setosa的分布自成一体。椭圆形勾勒出的是假设长度和宽度都呈正态分布的时候的95%的置信区间。一朵未知的花,它的花瓣长宽分别为1.5,0.5从图上我们可可以看出,它有90%以上的可能属于setosa区间。完成朴素贝叶斯分类学习之后,就可以利用上面这幅图的分布情况对未知的特定样本分类进行预判。
4.3.4 评估模型性能
为了评估分类器的效能,正常的做法是采集一些新的鸢尾花样本来测试模型能否正确的进行分类。不过这样做往往会增加实验成本,甚至有时候对于一些采集较难的数据,完全不可能新增数据,这是就需要用一种叫做交叉验证(cross validation)来处理数据。
交叉验证是一种能够对模型分类效果进行测试的方法。其思想就是将大部分数据作为训练集进行建模,然后看剩余数据是否符合模型。例如10折交叉验证(10-fold cross validation),将数据集分成十份,轮流将其中9份做训练1份做验证,10次的结果的均值作为对算法精度的估计。如果我们每次都建模获得的结果都可以对剩下的1份归属做精确验证。那么我们就有理由相信这个模型的分类方法是靠谱的。
可以用如下的方法检验交叉验证的结果:
CVMdl = crossval(Mdl);
Loss = kfoldLoss(CVMdl)
Loss =
0.0467
从中可以看出,利用了交叉验证之后,总共有占比为0.0467的样本发生了分类错误。最后,为了看出哪些部分的样本分类发生错误,可以用:
P=kfoldMargin(CVMdl);
stem(P);
来观察验证的结果。其中stem(P)表示对交叉验证的结果进行作图,我们可以看出,在150个样本当中,大部分的样本可以获得较为良好的分类结果(可靠性接近100%,但是也有少数样本无法通过交叉验证。对于这些样本的识别,基于贝叶斯分类的判断结果可能出错。

还可以使用下面的语句来观察交叉验证的结果
isLabels1 = kfoldPredict(CVMdl);
ConfusionMat1 = confusionmat(Y,isLabels1)
>> ConfusionMat1
ConfusionMat1 =
50 0 0
0 47 3
4 46
由此可以看出有7个样本交叉验证结果和原始分类的结果不一样。
4.3.5 提升模型性能
贝叶斯分析是基于先验概率分布来判断后验概率分布的一种方法。我们甚至可以用:
后验概率 = 标准似然度 * 先验概率
的公式来描述贝叶斯分布的基本特征。从前面所讲的HIV感染的例子中可以看出,先验概率对于后验概率的计算结果至关重要。换句话说,如果要正确判断出一组数据是否属于特定的鸢尾花种类,三种特定鸢尾花的基本分布也就非常重要。在我们先前的分析当中,我们可以通过语句:
Mdl.ClassNames
Mdl.Prior
ans =
\'setosa\'
\'versicolor\'
\'virginica\'
ans =
0.3333 0.3333 0.3333
来查看模型的先验概率分布。可以看出,在进行贝叶斯建模的时候,模型Mdl的先验概率分布实际上就是三种花在样本中的分布,各占1/3。然而,在现实生活中,很可能三种花的分布并不相等。比如,可以假设virginica鸢尾花在中国就非常少见,如果我们在中国找到的一株鲜花样本,那么先验概率就确定了这株花是virginica鸢尾花的概率会降低。在建立上述模型的时候,可以通过:
prior = [0.5 0.4 0.1];
Mdlnew = fitcnb(X,Y,\'Prior\',prior)
来对建立好模型的鸢尾花进行赋值。然后可以通过下面的语句分别对模型进行交叉验证:
defaultCVMdl = crossval(Mdlnew);
defaultLoss = kfoldLoss(defaultCVMdl)
CVMdl = crossval(Mdl);
Loss = kfoldLoss(CVMdl)
最后获得结果:
defaultLoss =
0.0533
Loss =
0.0467
可以看出先验概率的改变可以让交叉验证的训练结果发生改变。
Tip:由于交叉验证每次是随机抽出一些数据来进行验证,因此每次运行的结果可能和笔者展示的结果不一样。可以在crossvalidation之前先用rng(1) 来使结果可以重复。
4.4 总结
贝叶斯分类是所有分类算法中最直观最基础的算法,这种算法本质上是通过已经发生的事件来对未发生的事件进行预测。而当我们把已发生的事件当成人工智能的训练集的时候,根据训练集中的数据分布就有可能对未知样本进行判别。贝叶斯算法不但可以对未知样本的类别进行归类,还可以通过简单的计算给出特定样本属于未知类别的概率,甚至给出样本的每一个特征对于判别的贡献,因此,这种算法有助于人类对于样本的各种数据分布的理解。
-
以上是关于概率--学习朴素贝叶斯分布的主要内容,如果未能解决你的问题,请参考以下文章