词法分析程序
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析程序相关的知识,希望对你有一定的参考价值。
1.词法分析程序的功能:
组织输入、扫描、分析、输出;
接收字符串形式的源程序,按照源程序输入的次序依次扫描源程序,在扫描的同时根据语言的词法规则识别出具有独立意义的单词,并产生与源程序等价的属性字(Token)流 .
(1) 只要不修改接口,则词法分析器所作的修改不会影响整个编译器,且词法分析器易于维护;
(2) 整个编译器结构简捷、清晰;
(3) 可以采用有效的方法和工具进行处理。
2.符号与种别码对照表:
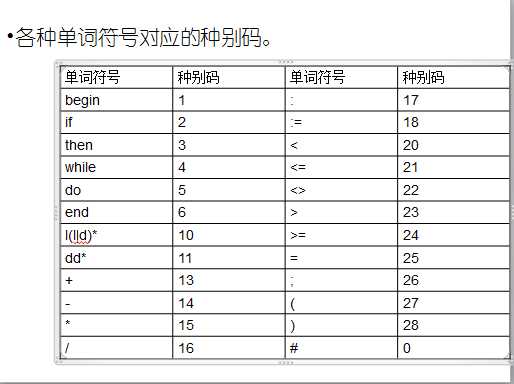
3.源程序及说明
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
char TOken[10];//分开进行比较
char ch;
/*char rwtab[6]={"begin","if","then","while","do","end"};*/
char r1[]={"auto"};
char r2[]={"break"};
char r3[]={"case"};
char r4[]={"char"};
char r5[]={"const"};
char r6[]={"continue"};
char r7[]={"default"};
char r8[]={"do"};
char r9[]={"double"};
char r10[]={"else"};
char r11[]={"enum"};
char r12[]={"extern"};
char r13[]={"float"};
char r14[]={"for"};
char r15[]={"goto"};
char r16[]={"if"};
char r17[]={"int"};
char r18[]={"long"};
char r19[]={"register"};
char r20[]={"return"};
char r21[]={"short"};
char r22[]={"signed"};
char r23[]={"sizeof"};
char r24[]={"static"};
char r25[]={"struct"};
char r26[]={"switch"};
char r27[]={"typedef"};
char r28[]={"union"};
char r29[]={"unsigned"};
char r30[]={"void"};
char r31[]={"volatile"};
char r32[]={"while"};
char r33[]={"end"};
char r34[]={"include"};
char r35[]={"stdio"};
char r36[]={"string"};
char r37[]={"main"};
char r38[]={"stdlib"};//这是我定义的
char A[10000];//输入的所有值
int syn,row;
int n,m,p,sum,j;
static int i = 0;
void scaner();
int main()
{
row = 0 ;
p = 0 ;
printf("Please input string:(end of ‘@‘)\\n");
do
{
scanf("%c",&ch);
A[p]=ch;
p++;
}//输入值到数组A【】中,以@结束
while(ch!=‘@‘);
do
{
scaner();//进入函数进行判定
switch(syn)
{
case 40: printf("(%d,%d)\\n",syn,sum); break;//如果是40,那么就是数字
case 0: printf("(%d,%c)\\n",syn,TOken[0]);break;//如果是0,那么是@ 结束
case -2: row=row++;break;
default: printf("(%d,%s)\\n",syn,TOken);break;//否则,就是变量名、关键词
}
}
while (syn!=0);
}
void scaner()
{
/*
共分为三大块,分别是标示符、数字、符号,对应下面的 if else if 和 else
*/
for(n=0;n<7;n++)
TOken[n]=0;//每次循环完就清零
ch=A[i];
while(ch==‘ ‘||ch==‘\\n‘)//如果字符是空格或者回车,跳过
{
i++;
ch=A[i];
}
if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘)) //可能是标示符或者变量名
{
m=0;
while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))//找到一个变量名或者关键字,直到遇到空格为止
{
TOken[m]=ch;m++;
i++;ch=A[i];
}
TOken[m]=‘\\0‘;
//将识别出来的字符和已定义的标示符作比较, //因为定义的begin为1,if为2......
if(strcmp(TOken,r1)==0){syn=1;}
else if(strcmp(TOken,r2)==0){syn=2; }
else if(strcmp(TOken,r3)==0){syn=3;}
else if(strcmp(TOken,r4)==0){syn=4;}
else if(strcmp(TOken,r5)==0){syn=5;}
else if(strcmp(TOken,r6)==0){syn=6;}
else if(strcmp(TOken,r7)==0){syn=7;}
else if(strcmp(r8,TOken)==0){syn=8;}
else if(strcmp(r9,TOken)==0){syn=9;}
else if(strcmp(r10,TOken)==0){syn=10;}
else if(strcmp(r11,TOken)==0){syn=11;}
else if(strcmp(r12,TOken)==0){syn=12;}
else if(strcmp(r13,TOken)==0){syn=13;}
else if(strcmp(r14,TOken)==0){syn=14;}
else if(strcmp(r15,TOken)==0){syn=15;}
else if(strcmp(r16,TOken)==0){syn=16;}
else if(strcmp(r17,TOken)==0){syn=17;}
else if(strcmp(r18,TOken)==0){syn=18;}
else if(strcmp(r19,TOken)==0){syn=19;}
else if(strcmp(r20,TOken)==0){syn=20;}
else if(strcmp(r21,TOken)==0){syn=21;}
else if(strcmp(r22,TOken)==0){syn=22;}
else if(strcmp(r23,TOken)==0){syn=23;}
else if(strcmp(r24,TOken)==0){syn=24;}
else if(strcmp(r25,TOken)==0){syn=25;}
else if(strcmp(r26,TOken)==0){syn=26;}
else if(strcmp(r27,TOken)==0){syn=27;}
else if(strcmp(r28,TOken)==0){syn=28;}
else if(strcmp(r29,TOken)==0){syn=29;}
else if(strcmp(r30,TOken)==0){syn=30;}
else if(strcmp(r31,TOken)==0){syn=31;}
else if(strcmp(r32,TOken)==0){syn=32;}
else if(strcmp(r33,TOken)==0){syn=33;}
else if(strcmp(r34,TOken)==0){syn=34;}
else if(strcmp(r35,TOken)==0){syn=35;}
else if(strcmp(r36,TOken)==0){syn=36;}
else if(strcmp(r37,TOken)==0){syn=37;}
else if(strcmp(r38,TOken)==0){syn=38;}
else{syn=100;} //变量名
}
else if((ch>=‘0‘&&ch<=‘9‘)) //数字
{
sum=0;
while((ch>=‘0‘&&ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;//显示其数字sum
i++;
ch=A[i];
}
syn=40;
}
else switch(ch) //其他字符
{
case‘<‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)//<>为22
{
syn=41;
TOken[m]=ch;m++;i++;
}
else
{
syn=46;
}
break;
case‘>‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=42;
TOken[m]=ch;m++;i++;
}
else
{
syn=47;
}
break;
case‘:‘:m=0;TOken[m]=ch;m++;
i++;ch=A[i];
if(ch==‘=‘)
{
syn=44;
TOken[m]=ch;m++;i++;
}
else
{
syn=49;
}
break;
case‘@‘:syn=0;TOken[0]=ch;i++;break;
case‘=‘:syn=48;TOken[0]=ch;i++;break;
case‘#‘:syn=50;TOken[0]=ch;i++;break;
case‘+‘:syn=50;TOken[0]=ch;i++;break;
case‘-‘:syn=51;TOken[0]=ch;i++;break;
case‘*‘:syn=52;TOken[0]=ch;i++;break;
case‘/‘:syn=53;TOken[0]=ch;i++;break;
case‘(‘:syn=54;TOken[0]=ch;i++;break;
case‘)‘:syn=55;TOken[0]=ch;i++;break;
case‘{‘:syn=56;TOken[0]=ch;i++;break;
case‘}‘:syn=57;TOken[0]=ch;i++;break;
case‘;‘:syn=58;TOken[0]=ch;i++;break;
case‘.‘:syn=59;TOken[0]=ch;i++;break;
case‘\\‘‘:syn=60;TOken[0]=ch;i++;break;
case‘\\n‘:syn=-2;break;
default: syn=-1;break;
}
}
以上是关于词法分析程序的主要内容,如果未能解决你的问题,请参考以下文章