词法分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析相关的知识,希望对你有一定的参考价值。
词法分析程序的功能:
输入一个二元式,输出二元式的值。
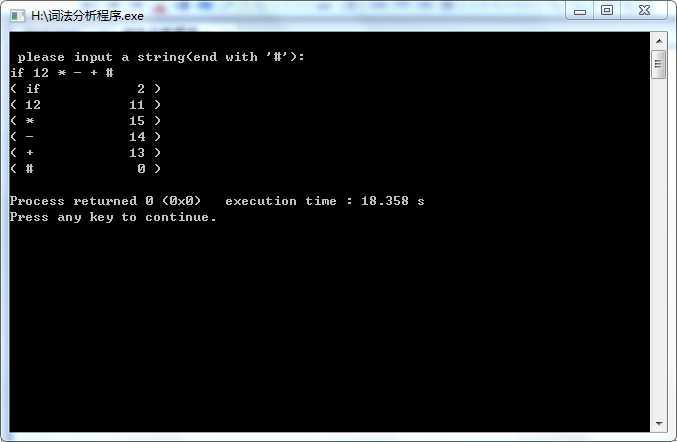
程序调试截图如下:
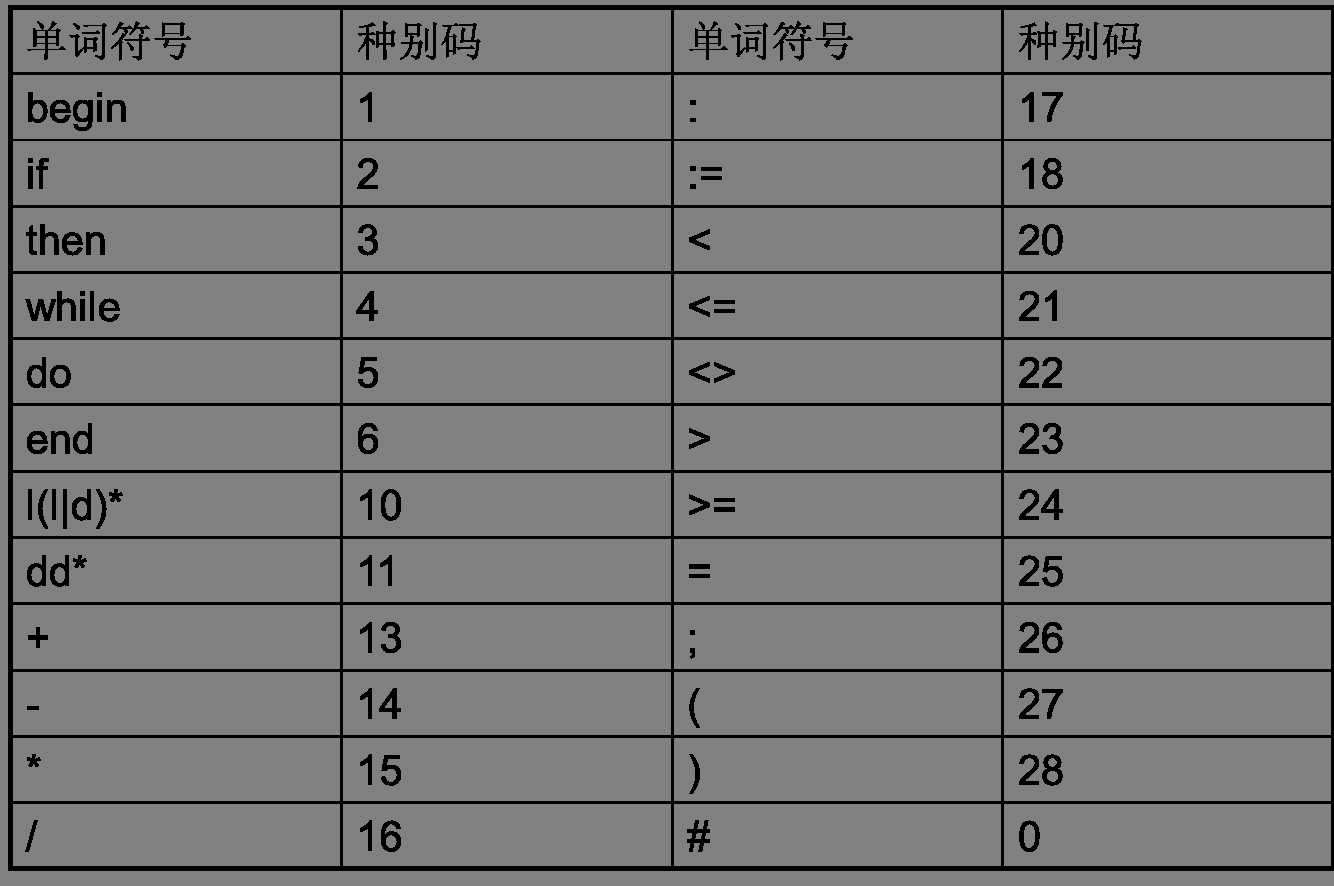
符号与种别码对照表:
用文法描述词法规则:
•<字母>→ a|b|c|……y|z
•<数字>→d|<整数>|.<小数>
•<整数常数>→1|2|3|···
•<标识符>→l|l<字母数字>
•<关键字>→→if|else|while|do|for|int|char|···
•<运算符>→+|-|-|/|=|=<等号>···
•<界符>→,|;|(|)|···
源程序代码如下:
1 #include <stdio.h> 2 #include <string.h> 3 char prog[80],token[8],ch; 4 int syn,p,m,n,sum; 5 char *rwtab[6]={"begin","if","then","while","do","end"}; 6 void scaner(void); 7 main() 8 { 9 p=0; 10 printf("\\n please input a string(end with ‘#‘):\\n"); 11 do{ 12 scanf("%c",&ch); 13 prog[p++]=ch; 14 }while(ch!=‘#‘); 15 p=0; 16 do{ 17 scaner(); 18 switch(syn) 19 { 20 case 11: 21 printf("( %-10d%5d )\\n",sum,syn); 22 break; 23 case -1: 24 printf("you have input a wrong string\\n"); 25 return 0; 26 break; 27 default: 28 printf("( %-10s%5d )\\n",token,syn); 29 break; 30 } 31 }while(syn!=0); 32 } 33 void scaner(void) 34 { 35 sum=0; 36 for(m=0;m<8;m++) 37 token[m++]= NULL; 38 ch=prog[p++]; 39 m=0; 40 while((ch==‘ ‘)||(ch==‘\\n‘)) 41 ch=prog[p++]; 42 if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))) 43 { 44 while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘))) 45 { 46 token[m++]=ch; 47 ch=prog[p++]; 48 } 49 p--; 50 syn=10; 51 for(n=0;n<6;n++) 52 if(strcmp(token,rwtab[n])==0) 53 { 54 syn=n+1; 55 break; 56 } 57 } 58 else if((ch>=‘0‘)&&(ch<=‘9‘)) 59 { 60 while((ch>=‘0‘)&&(ch<=‘9‘)) 61 { 62 sum=sum*10+ch-‘0‘; 63 ch=prog[p++]; 64 } 65 p--; 66 syn=11; 67 } 68 else 69 { 70 switch(ch) 71 { 72 case ‘<‘: 73 token[m++]=ch; 74 ch=prog[p++]; 75 if(ch==‘=‘) 76 { 77 syn=22; 78 token[m++]=ch; 79 } 80 else 81 { 82 syn=20; 83 p--; 84 } 85 break; 86 87 case ‘>‘: 88 token[m++]=ch; 89 ch=prog[p++]; 90 if(ch==‘=‘) 91 { 92 syn=24; 93 token[m++]=ch; 94 } 95 else 96 { 97 syn=23; 98 p--; 99 } 100 break; 101 102 case ‘+‘: 103 token[m++]=ch; 104 ch=prog[p++]; 105 if(ch==‘+‘) 106 { 107 syn=17; 108 token[m++]=ch; 109 } 110 else 111 { 112 syn=13; 113 p--; 114 } 115 break; 116 117 case ‘-‘: 118 token[m++]=ch; 119 ch=prog[p++]; 120 if(ch==‘-‘) 121 { 122 syn=29; 123 token[m++]=ch; 124 } 125 else 126 { 127 syn=14; 128 p--; 129 } 130 break; 131 132 case ‘!‘: 133 ch=prog[p++]; 134 if(ch==‘=‘) 135 { 136 syn=21; 137 token[m++]=ch; 138 } 139 else 140 { 141 syn=31; 142 p--; 143 } 144 break; 145 146 case ‘=‘: 147 token[m++]=ch; 148 ch=prog[p++]; 149 if(ch==‘=‘) 150 { 151 syn=25; 152 token[m++]=ch; 153 } 154 else 155 { 156 syn=18; 157 p--; 158 } 159 break; 160 case ‘*‘: 161 syn=15; 162 token[m++]=ch; 163 break; 164 case ‘/‘: 165 syn=16; 166 token[m++]=ch; 167 break; 168 case ‘(‘: 169 syn=27; 170 token[m++]=ch; 171 break; 172 case ‘)‘: 173 syn=28; 174 token[m++]=ch; 175 break; 176 case ‘{‘: 177 syn=5; 178 token[m++]=ch; 179 break; 180 case ‘}‘: 181 syn=6; 182 token[m++]=ch; 183 break; 184 case ‘;‘: 185 syn=26; 186 token[m++]=ch; 187 break; 188 case ‘\\"‘: 189 syn=30; 190 token[m++]=ch; 191 break; 192 case ‘#‘: 193 syn=0; 194 token[m++]=ch; 195 break; 196 case ‘:‘: 197 syn=17; 198 token[m++]=ch; 199 break; 200 default: 201 syn=-1; 202 break; 203 } 204 } 205 token[m++]=‘\\0‘; 206 }