词法分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析相关的知识,希望对你有一定的参考价值。
1、 词法分析的功能:
词法分析器的主要任务是读入源程序的输入字符、将它们组成词素,生成并输出一个词法单元序列,每个词法单元对应于一个词素。
当词法分析器发现了一个标识符的词素时,要将这个词素添加到符号表中。
其他任务:
- 过滤掉源程序中的注释和空白。
- 将编译器生成的错误信息与源程序的位置联系起来。记录行号等。
词法分析器的两个级联的处理阶段:
- 扫描阶段:简单处理,删除注释,压缩空白字符。
- 词法分析阶段:处理扫描阶段的输出并生成词法单元。
|
2、符号与种别码对照表 单词符号 |
# |
begin |
if |
then |
while |
do |
End |
+ |
- |
* |
/ |
: |
: = |
|
种别码 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
13 |
14 |
15 |
16 |
17 |
18 |
|
单词符号 |
< |
<> |
<= |
> |
>= |
= |
; |
( |
) |
Letter(letter|digit) |
digit digit* |
|
种别码 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
10 |
11 |
二。符号与种别码的对照表以及源程序。
我所做的词法分析程序和大多数程序差不多,也有着很多的不足,我将需要进行翻译的各种单词符号的对应的种别码分成了若干个数组,并且在后期的修改中将老师的种别表进行了扩充,具体的功能是:输入需要翻译的东西作为字符串存储在A[][]的数组中,用字符ch来存储一个个的字符,在一次的循环中翻译出一个个种别类并将其用(,)来显示出来,一次循环,用数组TOKEN[]存储,进行下一次循环的同时清除里面的数据,方便进行下一次的翻译与存储。大致是如此。
源代码如下:
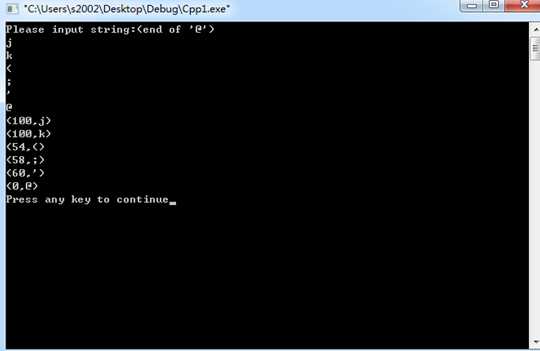
#include<stdio.h> #include<string.h> #include<stdlib.h> char TOken[10];//分开进行比较 char ch; /*char rwtab[6]={"begin","if","then","while","do","end"};*/ char r1[]={"auto"}; char r2[]={"break"}; char r3[]={"case"}; char r4[]={"char"}; char r5[]={"const"}; char r6[]={"continue"}; char r7[]={"default"}; char r8[]={"do"}; char r9[]={"double"}; char r10[]={"else"}; char r11[]={"enum"}; char r12[]={"extern"}; char r13[]={"float"}; char r14[]={"for"}; char r15[]={"goto"}; char r16[]={"if"}; char r17[]={"int"}; char r18[]={"long"}; char r19[]={"register"}; char r20[]={"return"}; char r21[]={"short"}; char r22[]={"signed"}; char r23[]={"sizeof"}; char r24[]={"static"}; char r25[]={"struct"}; char r26[]={"switch"}; char r27[]={"typedef"}; char r28[]={"union"}; char r29[]={"unsigned"}; char r30[]={"void"}; char r31[]={"volatile"}; char r32[]={"while"}; char r33[]={"end"}; char r34[]={"include"}; char r35[]={"stdio"}; char r36[]={"string"}; char r37[]={"main"}; char r38[]={"stdlib"};//这是我定义的 char A[10000];//输入的所有值 int syn,row; int n,m,p,sum,j; static int i = 0; void scaner(); int main() { row = 0 ; p = 0 ; printf("Please input string:(end of ‘@‘)\\n"); do { scanf("%c",&ch); A[p]=ch; p++; }//输入值到数组A【】中,以@结束 while(ch!=‘@‘); do { scaner();//进入函数进行判定 switch(syn) { case 40: printf("(%d,%d)\\n",syn,sum); break;//如果是40,那么就是数字 case 0: printf("(%d,%c)\\n",syn,TOken[0]);break;//如果是0,那么是@ 结束 case -2: row=row++;break; default: printf("(%d,%s)\\n",syn,TOken);break;//否则,就是变量名、关键词 } } while (syn!=0); } void scaner() { /* 共分为三大块,分别是标示符、数字、符号,对应下面的 if else if 和 else */ for(n=0;n<7;n++) TOken[n]=0;//每次循环完就清零 ch=A[i]; while(ch==‘ ‘||ch==‘\\n‘)//如果字符是空格或者回车,跳过 { i++; ch=A[i]; } if((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘)) //可能是标示符或者变量名 { m=0; while((ch>=‘0‘&&ch<=‘9‘)||(ch>=‘a‘&&ch<=‘z‘)||(ch>=‘A‘&&ch<=‘Z‘))//找到一个变量名或者关键字,直到遇到空格为止 { TOken[m]=ch;m++; i++;ch=A[i]; } TOken[m]=‘\\0‘; //将识别出来的字符和已定义的标示符作比较, //因为定义的begin为1,if为2...... if(strcmp(TOken,r1)==0){syn=1;} else if(strcmp(TOken,r2)==0){syn=2; } else if(strcmp(TOken,r3)==0){syn=3;} else if(strcmp(TOken,r4)==0){syn=4;} else if(strcmp(TOken,r5)==0){syn=5;} else if(strcmp(TOken,r6)==0){syn=6;} else if(strcmp(TOken,r7)==0){syn=7;} else if(strcmp(r8,TOken)==0){syn=8;} else if(strcmp(r9,TOken)==0){syn=9;} else if(strcmp(r10,TOken)==0){syn=10;} else if(strcmp(r11,TOken)==0){syn=11;} else if(strcmp(r12,TOken)==0){syn=12;} else if(strcmp(r13,TOken)==0){syn=13;} else if(strcmp(r14,TOken)==0){syn=14;} else if(strcmp(r15,TOken)==0){syn=15;} else if(strcmp(r16,TOken)==0){syn=16;} else if(strcmp(r17,TOken)==0){syn=17;} else if(strcmp(r18,TOken)==0){syn=18;} else if(strcmp(r19,TOken)==0){syn=19;} else if(strcmp(r20,TOken)==0){syn=20;} else if(strcmp(r21,TOken)==0){syn=21;} else if(strcmp(r22,TOken)==0){syn=22;} else if(strcmp(r23,TOken)==0){syn=23;} else if(strcmp(r24,TOken)==0){syn=24;} else if(strcmp(r25,TOken)==0){syn=25;} else if(strcmp(r26,TOken)==0){syn=26;} else if(strcmp(r27,TOken)==0){syn=27;} else if(strcmp(r28,TOken)==0){syn=28;} else if(strcmp(r29,TOken)==0){syn=29;} else if(strcmp(r30,TOken)==0){syn=30;} else if(strcmp(r31,TOken)==0){syn=31;} else if(strcmp(r32,TOken)==0){syn=32;} else if(strcmp(r33,TOken)==0){syn=33;} else if(strcmp(r34,TOken)==0){syn=34;} else if(strcmp(r35,TOken)==0){syn=35;} else if(strcmp(r36,TOken)==0){syn=36;} else if(strcmp(r37,TOken)==0){syn=37;} else if(strcmp(r38,TOken)==0){syn=38;} else{syn=100;} //变量名 } else if((ch>=‘0‘&&ch<=‘9‘)) //数字 { sum=0; while((ch>=‘0‘&&ch<=‘9‘)) { sum=sum*10+ch-‘0‘;//显示其数字sum i++; ch=A[i]; } syn=40; } else switch(ch) //其他字符 { case‘<‘:m=0;TOken[m]=ch;m++; i++;ch=A[i]; if(ch==‘=‘)//<>为22 { syn=41; TOken[m]=ch;m++;i++; } else { syn=46; } break; case‘>‘:m=0;TOken[m]=ch;m++; i++;ch=A[i]; if(ch==‘=‘) { syn=42; TOken[m]=ch;m++;i++; } else { syn=47; } break; case‘:‘:m=0;TOken[m]=ch;m++; i++;ch=A[i]; if(ch==‘=‘) { syn=44; TOken[m]=ch;m++;i++; } else { syn=49; } break; case‘@‘:syn=0;TOken[0]=ch;i++;break; case‘=‘:syn=48;TOken[0]=ch;i++;break; case‘#‘:syn=50;TOken[0]=ch;i++;break; case‘+‘:syn=50;TOken[0]=ch;i++;break; case‘-‘:syn=51;TOken[0]=ch;i++;break; case‘*‘:syn=52;TOken[0]=ch;i++;break; case‘/‘:syn=53;TOken[0]=ch;i++;break; case‘(‘:syn=54;TOken[0]=ch;i++;break; case‘)‘:syn=55;TOken[0]=ch;i++;break; case‘{‘:syn=56;TOken[0]=ch;i++;break; case‘}‘:syn=57;TOken[0]=ch;i++;break; case‘;‘:syn=58;TOken[0]=ch;i++;break; case‘.‘:syn=59;TOken[0]=ch;i++;break; case‘\\‘‘:syn=60;TOken[0]=ch;i++;break; case‘\\n‘:syn=-2;break; default: syn=-1;break; } }
/*这是我定义的种别类 符号:
@ 0 # 33
auto 1
break 2
case 3
char 4
const 5
continue 6
default 7
do 8
double 9
else 10
enum 11
extern 12
float 13
for 14
goto 15
if 16
int 17
long 18
register 19
return 20
short 21
signed 22
sizeof 23
static 24
struct 25
switch 26
typedef 27
union 28
unsigned 29
void 30
volatile 31
while 32
end 33
include 34
stdio 35
string 36
main 37
stdlib 38
qita 100
number 40
# 33
<= 41
>= 42
== 43
:= 44
<> 45
< 46
> 47
= 48
: 49
+ 50
- 51
* 52
/ 53
( 54
) 55
{ 56
} 57
; 58
. 59
*/
三 .用文法描述词法规则。
这个概念我不是太懂,但是也说说自己的理解和想法。
首先是文法形式的定义:A-〉B ,A代表的是左部符号,‘-〉’意思是为生成,而B代表的是右部的符号串。
有着终结符号:如0,1:1.组成语言的终止符。2.基本有小写字母组成。
文法(Vn,Vt,P,S)
就比如说:A->a|b|e|Aa|Ae|Ao|A
Vn = {A},
Vt ={a,b,c,d,e,0,1}
P={A->a|b|e|Aa|Ae|Ao|A}
S = A .
其实A-〉Aa 就代表着循环的意思,每进行一次,就会增加一个a,假如A-〉Aaa,意思就是每循环一次,就增加aa,所以暂时也就是理解到了这个意思,然后通过几道题来强化自己的理解。
就好比Q={a,b},L={a^2n ,b^2n|n>=1}
首先是看好n的取值范围,然后看n具体指了多少个,那么就比如一起来进行循环,这个题a,b都有n,但是是分开的,所以不用一起进行。
解题思路如下:
1.增长的趋势:a^2n,aa aaaa aaaaaa........
b^2n,bb bbbb bbbbbb.......
2.循环规律:A->aa A->Aaa
B->bb B->Bbb
3.S->A|B
A->aa|Aaa // 意思是aa为开头,循环不断增加aa
B->bb|Bbb // 意思是bb为开头,循环不断增加bb
以上是关于词法分析的主要内容,如果未能解决你的问题,请参考以下文章