机器学习技法--Blending and Bagging
Posted cyoutetsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习技法--Blending and Bagging相关的知识,希望对你有一定的参考价值。
Ensemble模型的基础概念。
先总结归纳几个aggregation的常见形式:

多选一的形式特别需要那几个里面有一个表现好的,如果表现都不太好的时候,几个模型融合到一起真的会表现好吗?
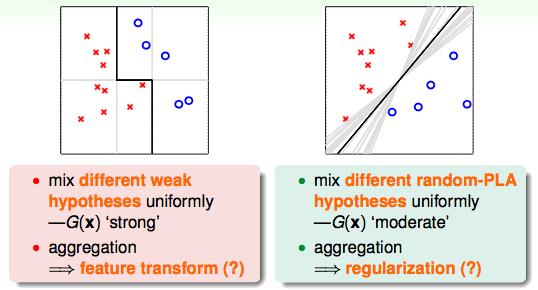
左图:如果只能用垂直的线和水平的线做分类,结果肯定不是太好,但是如果能把垂直的线和水平的线结合起来,就有可能做出这一条好的分割线;
右图:PLA会在可以分割的线中随机选一条,但是如果他们能投票的话,投票的线就会得到一个中庸的结果,就是那个黑线。
在知道了aggregate会表现好之后,下面介绍到底怎么样进行融合:
blending的前提是知道了几个g,结合的时候投票就好了:
classification的时候:
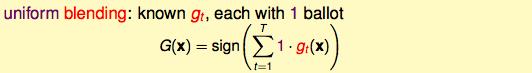
但是这几个已知的g要不一样才行,一样的话还是没有什么意义;
如果这些g很不一样的话,本质就是得出一个少数服从多数的结果。

regression的时候:做一个平均
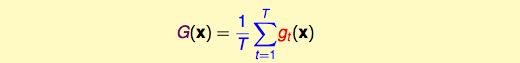

也就是说,当我们已知的g差异很大的时候,融合起来的表现一定比单个g表现要好。
数学证明:

从上式可以看出,一个演算法的表现可以分成两个部分:

Blending的过程就是一个减少方差(variance)的过程,这个过程可以让表现更加的稳定。
下面介绍Linear Blending:从一人一票改成没人投票是有权重的,这个权重又是线性的。
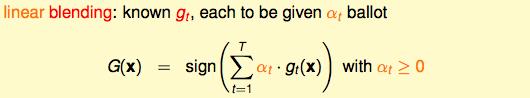
一个好的αt的标准就是最小化Ein:
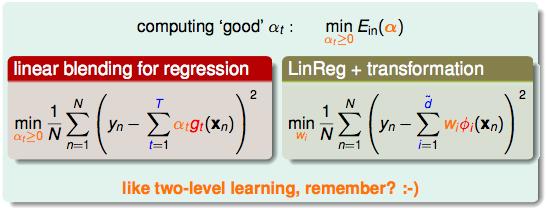
linear blending = linear model + hypotheses transform + constraints

α在二元分类问题中反过来其实也没什么,这样的话那个constraints也可以去掉了:

linear blending和model selection的区别:

如果用Ein的话,有很多的缺点,所以建议用validation error来做标准。

所以,之前说的blending是先把所有的g算出来,再做融合,那么我们能不能一边算g,一边融合呢?
怎么样保证g的多样性呢?

那么同一份数据能不能创造g的多样性呢?


bootstrapping:一个统计学的工作,其目的是从有限的数据中“模拟”更多的数据出来。其实就是放回抽样。这样的话,同一笔数据有可能被抽取多次,也有可能一次都没有被抽取。


boostrap就是bagging。这个bagging的算法在base algorithm对随机很敏感的时候表现好。
总结:
以上是关于机器学习技法--Blending and Bagging的主要内容,如果未能解决你的问题,请参考以下文章