Spark history-server 配置 !运维人员的强大工具
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark history-server 配置 !运维人员的强大工具相关的知识,希望对你有一定的参考价值。
spark history Server产生背景
以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息;但该WEBUI随着Application的完成(成功/失败)而关闭,也就是说,Spark Application运行完(成功/失败)后,将无法查看Application的历史记录;
Spark history Server就是为了应对这种情况而产生的,通过配置可以在Application执行的过程中记录下了日志事件信息,那么在Application执行结束后,WEBUI就能重新渲染生成UI界面展现出该Application在执行过程中的运行时信息;
Spark运行在yarn或者mesos之上,通过spark的history server仍然可以重构出一个已经完成的Application的运行时参数信息(假如Application运行的事件日志信息已经记录下来);
spark history Server的配置
1. 在Spark的conf目录下/usr/local/spark-1.6.0-bin-hadoop2.6/conf,将spark-defaults.conf.template改名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf

spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ ls
bin data examples licenses NOTICE README.md work
CHANGES.txt derby.log lib logs python RELEASE
conf ec2 LICENSE metastore_db R sbin
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ cd conf/
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template metrics.properties.template spark-env.sh
fairscheduler.xml.template slaves
log4j.properties.template spark-defaults.conf.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ mv spark-defaults.conf.template spark-defaults.conf
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template metrics.properties.template spark-env.sh
fairscheduler.xml.template slaves
log4j.properties.template spark-defaults.conf
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$
2. 对spark-defaults.conf 配置
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ vim spark-defaults.conf
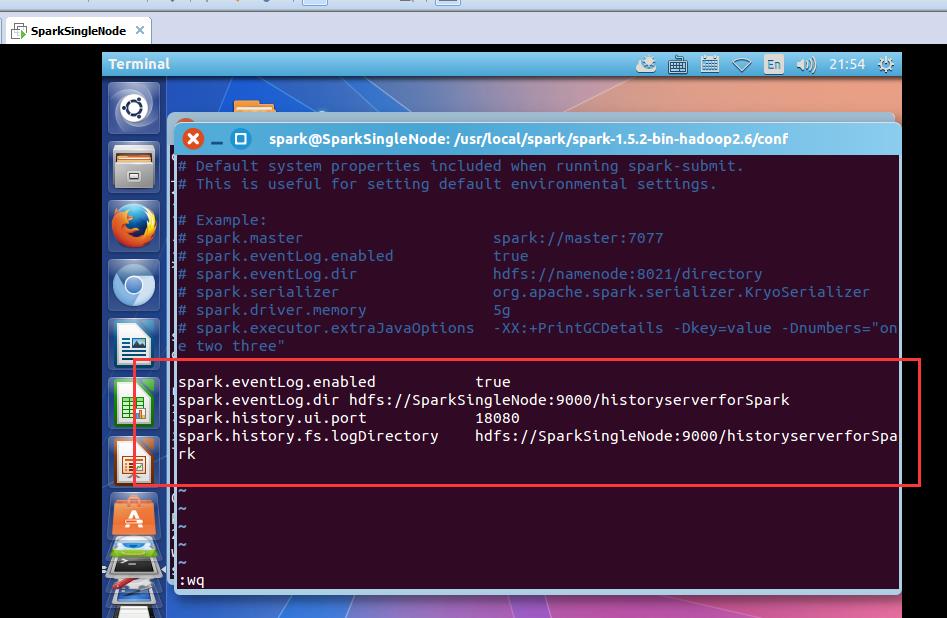
spark.eventLog.enabled true
spark.eventLog.dir hdfs://SparkSingleNode:9000/historyserverforSpark
spark.history.ui.port 18080
spark.history.fs.logDirectory hdfs://SparkSingleNode:9000/historyserverforSpark
3.启动history-server
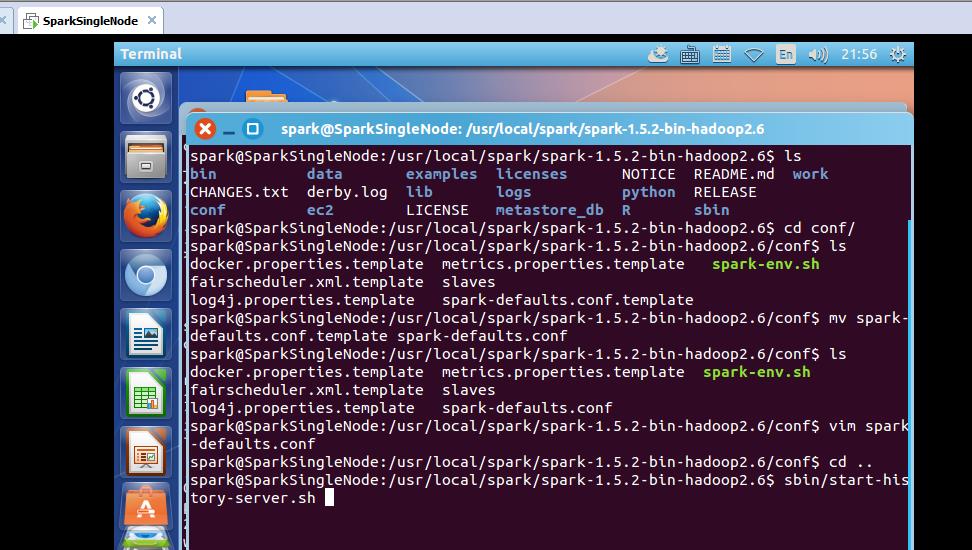
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cd ..
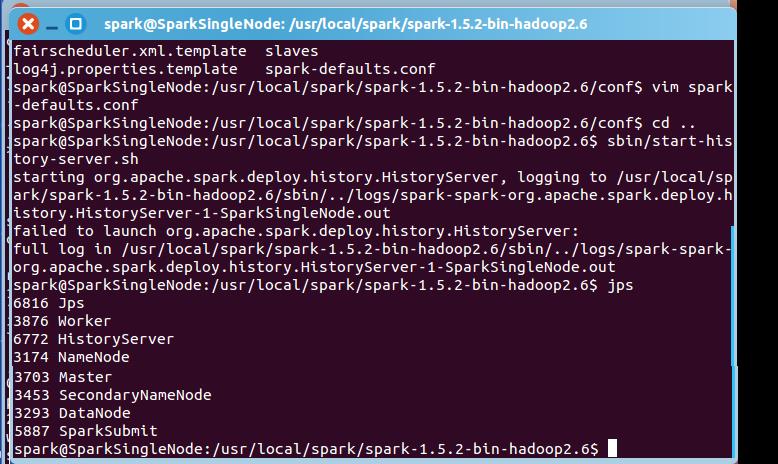
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.history.HistoryServer-1-SparkSingleNode.out
failed to launch org.apache.spark.deploy.history.HistoryServer:
full log in /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.history.HistoryServer-1-SparkSingleNode.out
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ jps
6816 Jps
3876 Worker
6772 HistoryServer
3174 NameNode
5990 CoarseGrainedExecutorBackend
3703 Master
3453 SecondaryNameNode
3293 DataNode
5887 SparkSubmit
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$


4、spark-env.sh
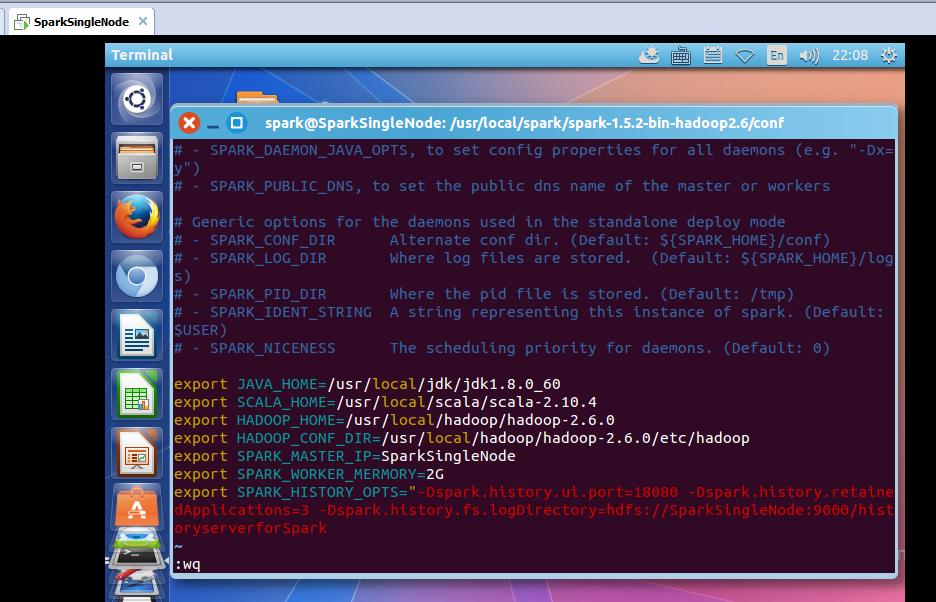
5.在web浏览器中查看http://SparkSingleNode:18080/ 显示页面
1.6.0 History Server
Event log directory: hdfs://Master:9000/historyserverforSpark
成功!
以上是关于Spark history-server 配置 !运维人员的强大工具的主要内容,如果未能解决你的问题,请参考以下文章