hadoop
Posted zhenhong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop相关的知识,希望对你有一定的参考价值。
一、环境
1、centos
2、JDK
3、hadoop
二、单机版
1、下载hadoop,地址http://120.203.214.5/8c2/71233/8c262c70bcd6098df871f293e2f9337d3f571233/hadoop-2.7.3.tar.gz?n=hadoop-2.7.3.tar.gz
2、tar -zxf hadoop-2.7.3.tar.gz,解压
3、配置hadoop的环境变量,vim /etc/profile
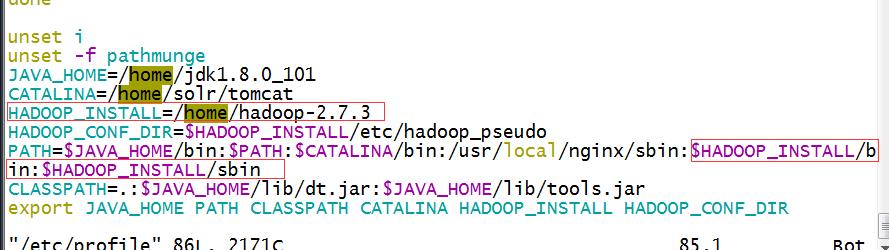
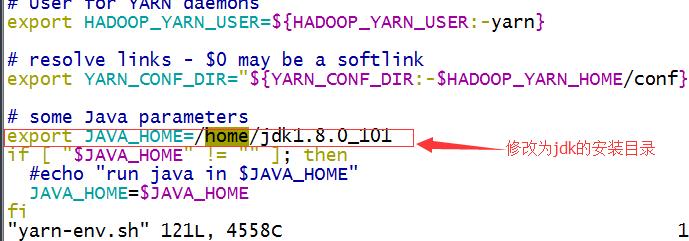
4、复制hadoop-2.7.3/etc/hadoop为hadoop-2.7.3/etc/hadoop_conf。进入hadoop_conf,修改hadoop-env.sh和yarn-env.sh
hadoop-env.sh

yarn-env.sh
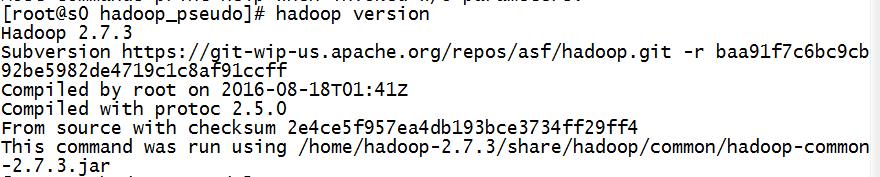
5、输入hadoop version显示版本信息
6、输入hadoop namenode -format格式化,再输入hadoop fs -ls /会显示根目录信息
三、伪分布式
1、单机、伪分布式、完全分布式一些属性的配置表

2、在hadoop-2.7.3下mkdir -p tmp dfs/name dfs/data,然后分别修改hadoop_conf下的core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml,将以下对应xml的代码拷贝到相应的xml文件中
<?xml version="1.0"?> <!-- core-site.xml --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost/</value> </property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/loal/hadoop-2.7.3/dfs/name</value>
</property>
</configuration> <?xml version="1.0"?> <!-- hdfs-site.xml --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop-2.7.3/dfs/data</value>
</property>
</configuration> <?xml version="1.0"?> <!-- mapred-site.xml --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> <?xml version="1.0"?> <!-- yarn-site.xml --> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
比如mapred-site.xml
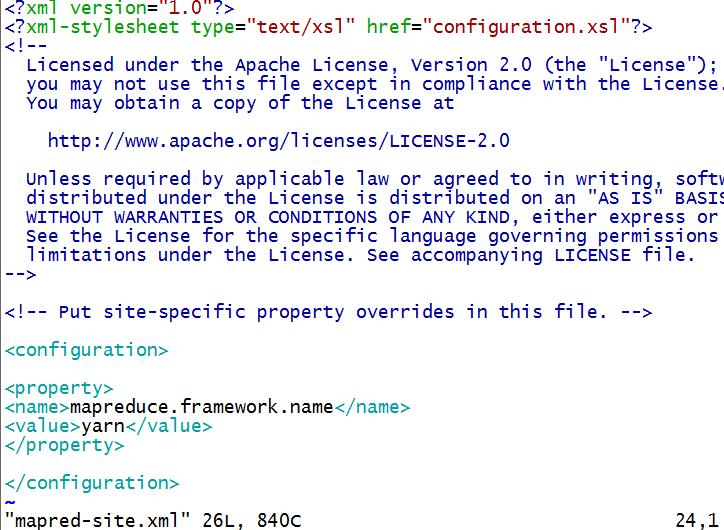
3、配置完成后,要配置ssh,查看是否安装了ssh,使用命令which ssh,若出现/usr/bin/ssh表示已安装。

4、输入命令ssh-keygen -t rsa -P \'\' -f ~/.ssh/id_rsa,它会在你的/home/xxx(当前登陆的用户文件夹)创建一个隐藏的文件夹./ssh,使用命令ls -al查看,产生的文件目录如下:
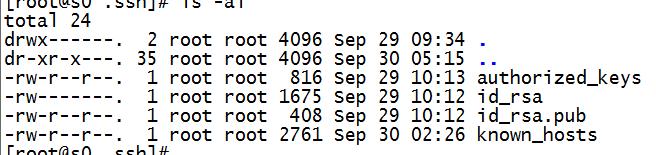
其中id_rsa为私密密钥,id_rsa.pub为公开密钥,这么做的目的是为了完全分布式时,多个hadoop之间的加密通信。私密密钥只能解密公密发过来的加密信息,公开密钥只能解密私密密钥发过来的加密信息。
5、输入命令cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys,也就是生成上图出现的authorized_keys文件,用于存储认证信息,第一登陆需要输入认证,第二次就可以直接登陆
6、登陆命令ssh localhost,第一次会出现确认信息,输入yes即可,下次登陆就没有这个步骤了,推出输入exit。
7、先格式化,hadoop namenode -format,再启动守护线程,先输入start-dfs.sh再输入start-yarn.sh最后输入(这个可以不启动)mr-jobhistory-daemon.sh start historyserver,或使用start-all.sh一键启动,不过官方已经不推荐这么用了。(注意:这样是启动不了的,因为前面我们修改了默认的配置的文件,我们真正进行了配置的文件是hadoop_conf)
(1)第一种方法给每个命令后面加上--config /home/hadoop-2.7.3/etc/hadoop_conf
(2)第二种配置环境变量 HADOOP_CONF_DIR,vim /etc/profile,增加HADOOP_CONF_DIR=/home/hadoop-2.7.3/etc/hadoop_conf
(3)第三种把原来的hadoop改个名字,再给hadoop_conf建立一个链接,ln -s hadoop_conf hadoop,当然如果你直接在hadoop上改东西的话,这一切将不会发生。
8、启动后输入hadoop fs -ls /你会发现是空的,此时你可以使用hadoop fs -mkdir /user/建立一个user文件夹,再次使用hadoop fs -ls / 就可以看到刚才建立的user文件夹。
四、完全分布式
1、再克隆3个虚拟机
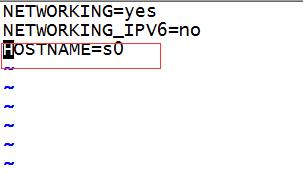
2、打开全部虚拟机,修改每个虚拟机的主机名,vim /etc/sysconfig/network,vim /etc/hosts,并且添加本机和其他主机的ip和主机名,全部重启
network
hosts
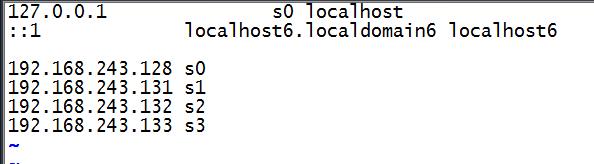
3、此时可以在其中任何一台机器上访问其他的主机

4、我们以s0主机作为namenode,所以我们修改s0的配置文件,修改core-site.xml、yarn-site.xml,hdfs-site.xml,给hadoop_conf下的slaves添加s1,s2,s3,表示添加三个数据节点
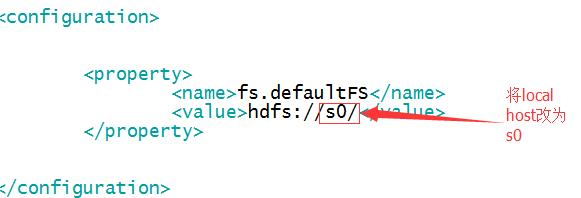
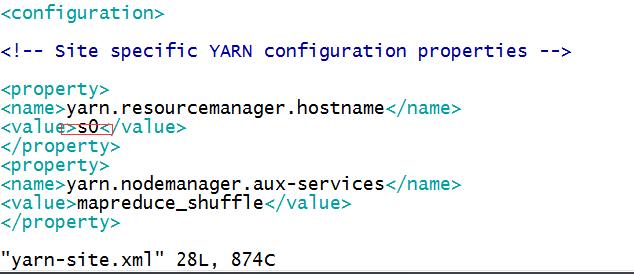
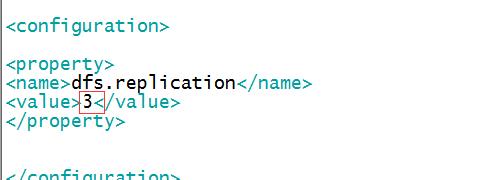
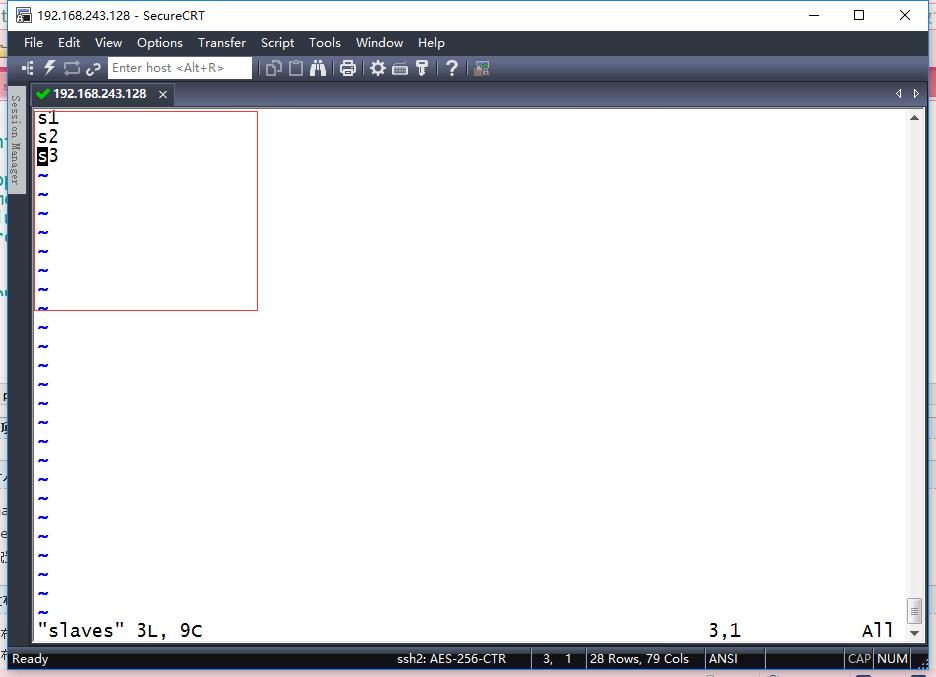
如果还要设置一个secondaryNode,比如将s2同时设置成secondaryNode,那么修改masters文件输入s2保存即可。
5、其他的主机应当配置一个和s0主机一样的配置文件,由于直接改麻烦,我们可以用远程复制方式
依次使用命令scp -r hadoop_conf root@s1:/home/hadoop-2.7.3/etc/hadoop_conf,
scp -r hadoop_conf root@s1:/home/hadoop-2.7.3/etc/hadoop_conf,
scp -r hadoop_conf root@s2:/home/hadoop-2.7.3/etc/hadoop_conf,
scp -r hadoop_conf root@s3:/home/hadoop-2.7.3/etc/hadoop_conf
6、hadoop namenode -format ,start-all.sh启动
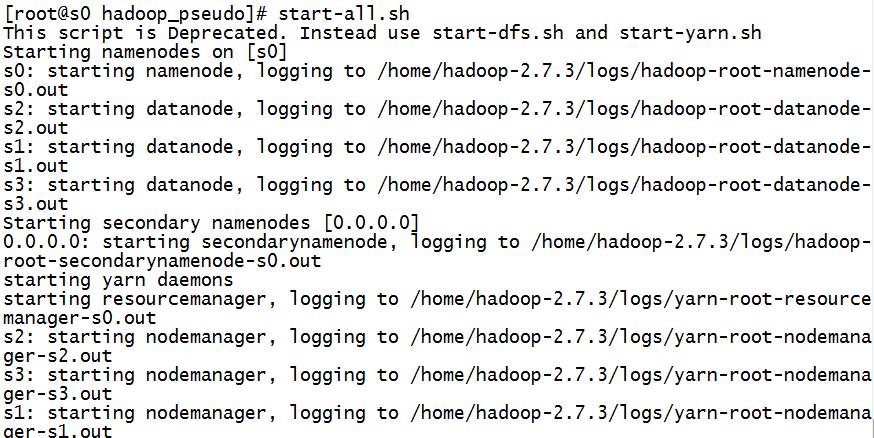
启动所有的服务后可在windows的浏览器中输入 http://s0:50070/来访问namenode。这个s0是nameNode的主机名,可以修改windows下的一个叫做hosts的文件,它的位置C:\\Windows\\System32\\drivers\\etc\\下。
添加类似以下内容即可:
192.168.243.128 s0
以上是关于hadoop的主要内容,如果未能解决你的问题,请参考以下文章