flume+sparkStreaming实例 实时监控文件demo
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flume+sparkStreaming实例 实时监控文件demo相关的知识,希望对你有一定的参考价值。
1,flume所在的节点不和spark同一个集群 v50和 10-15节点 flume在v50里面
flume-agent.conf
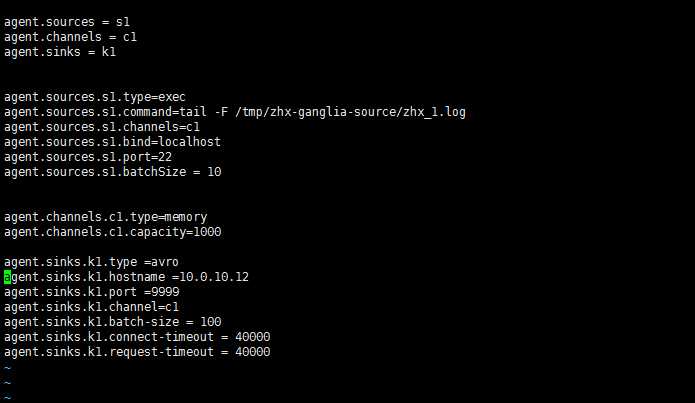
spark是开的work节点,就是单点计算节点,不涉及到master发送管理 只是用到了sparkStreming的实时功能
开启的是spark-shell不是spark-submit 提交jar的形式,提交jar的形式还需要后面研究下
如下 在结算节点下
和flume的jar包要在各个节点上的spark 都要放入:
bin/spark-shell \\
--jars /hadoop/spark/spark-2.0/jars/flume-ng-sdk-1.6.0.jar
,/hadoop/spark/spark-2.0/jars/flume-avro-source-1.5.0.1.jar,
/hadoop/spark/spark-2.0/jars/spark-streaming-flume_2.11-2.0.0.jar \\
--master local[2]
12端口
val stream = FlumeUtils.createStream(ssc, "10.0.10.12", 9999)
11端口的spark
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.flume._
val ssc = new StreamingContext(sc, Seconds(5))
//9999就是开启的端口 像socket一样 用端口连接
val stream = FlumeUtils.createStream(ssc, "10.0.10.12", 9999)
val wordCountStream = stream.map(x => new String(x.event.getBody.array())).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
wordCountStream.print()
ssc.start()
ssc.awaitTermination()
flume命令
bin/flume-ng agent --conf conf --conf-file conf/taile2stream.conf --name agent -Dflume.root.logger=INFO,console
以上是关于flume+sparkStreaming实例 实时监控文件demo的主要内容,如果未能解决你的问题,请参考以下文章