ODI多库抽取到一个库解决方案II
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ODI多库抽取到一个库解决方案II相关的知识,希望对你有一定的参考价值。
前面提到,当多库通过ODI抽取到一个库时,通过建立中间用户,在中间用户上建立日志表,将源端日志写入中间用户日志表方式进行数据抽取。发现,实际使用过程中由于通过dblink进行远端写,并且跟系统繁忙程度有关,发现生产库上大量网络等待。为了解决该问题,需要把日志写在本地库中。然而,要解决这个问题,需要为不同库,生成不同临时对象(以解决临时对象冲突问题)。本例以FOLDERS表为例,说明如何对不同库创建不同模型,来生成不同临时对象,以解决临时对象冲突问题。
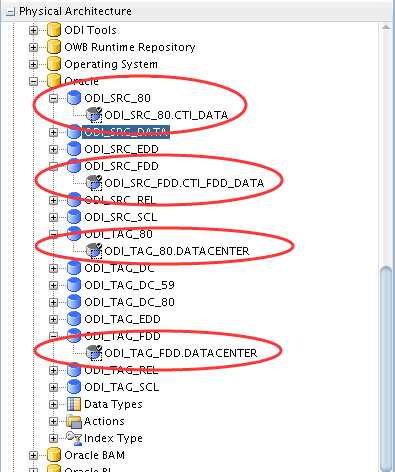
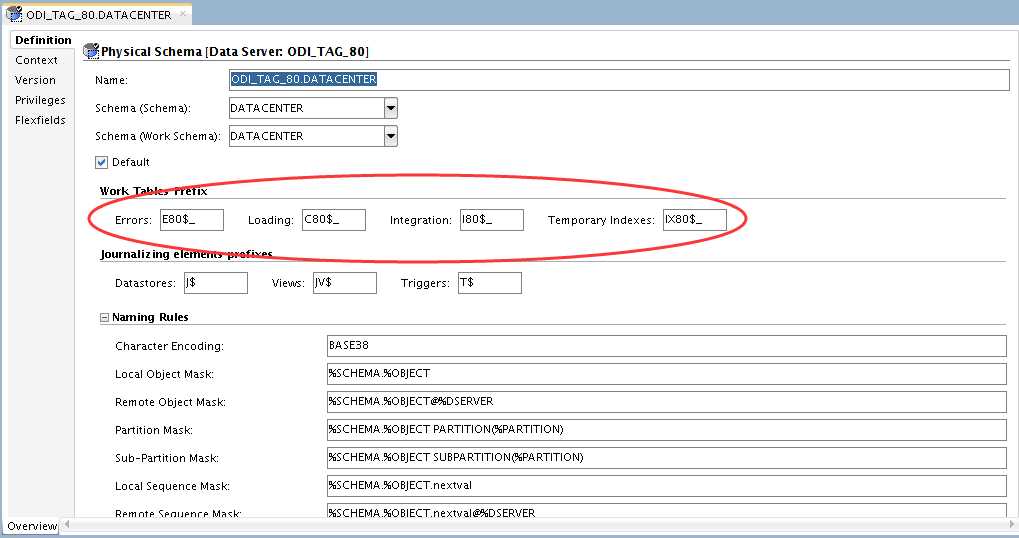
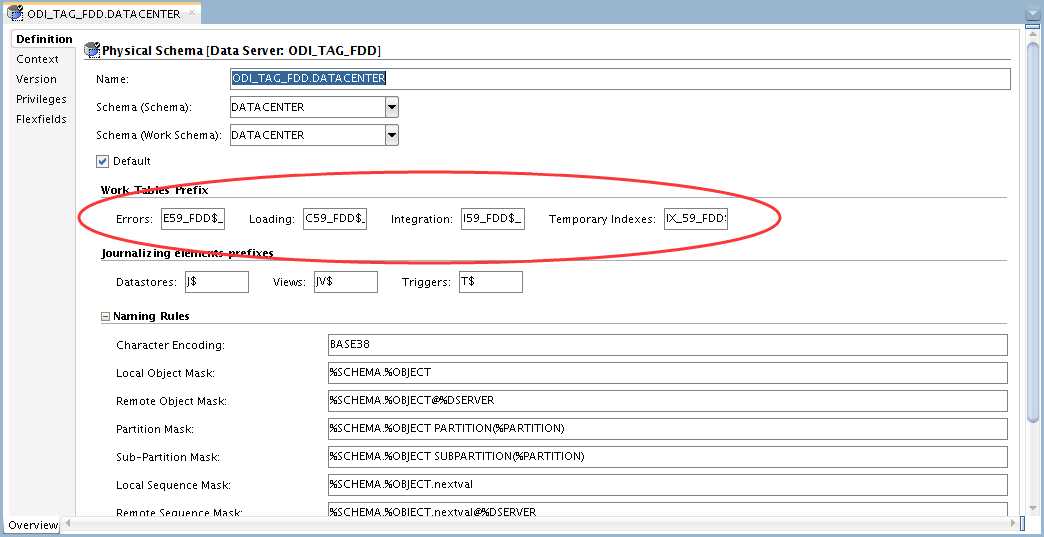
如上,分别创建了物理体系结构ODI_SRC_80、ODI_SRC_FDD、ODI_TAG_80、ODI_TAG_FDD,前两者对应源,后两者对应目标。对于TAG端的命名规则,我们设置如下
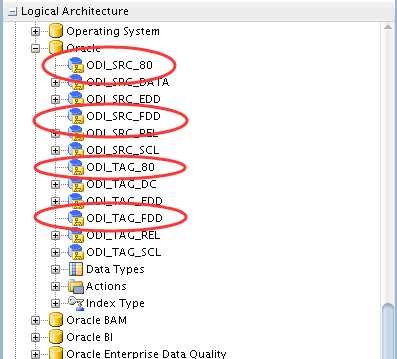
创建逻辑体系结构ODI_SRC_80、ODI_SRC_FDD、ODI_TAG_80、ODI_TAG_FDD
创建模型
创建映射
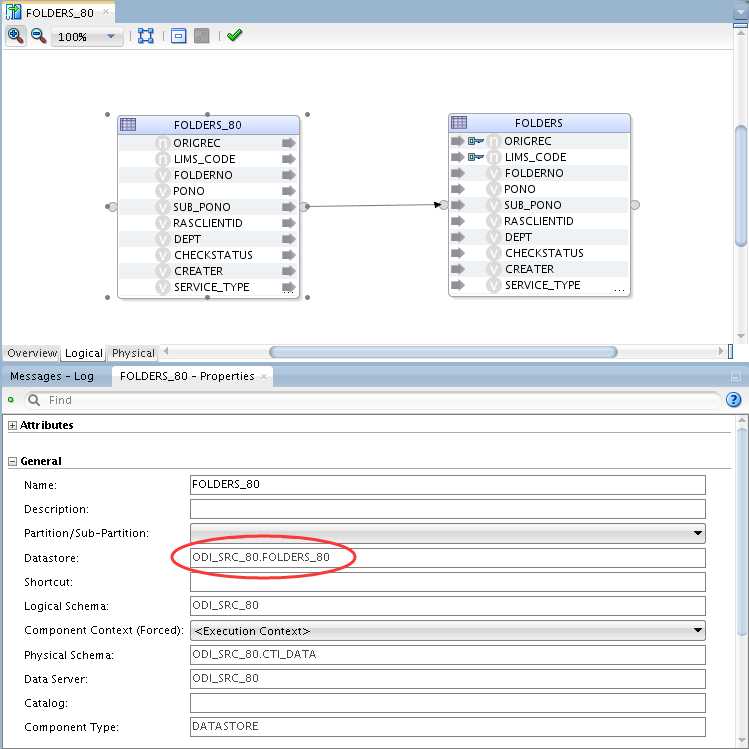
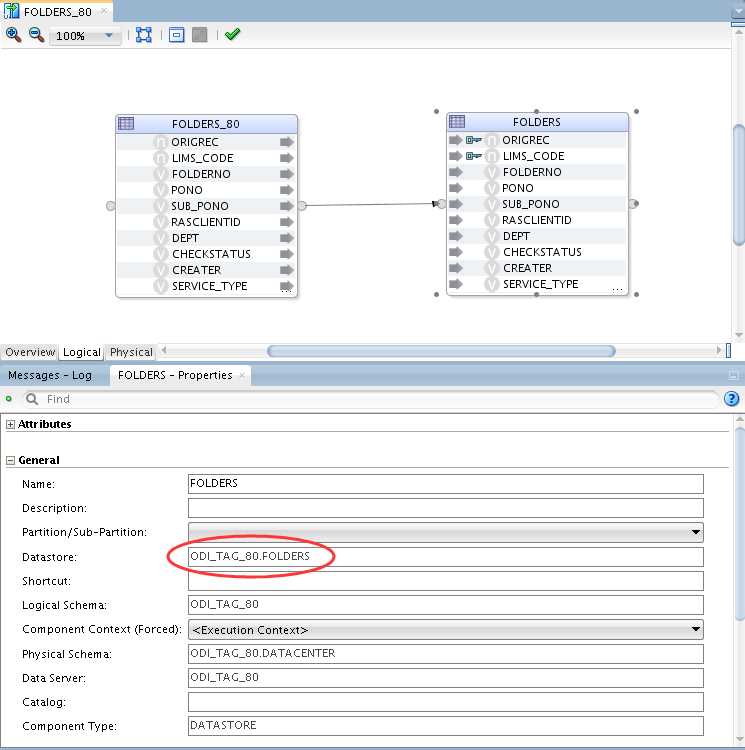
FOLDERS_80映射
FOLDERS_FDD映射
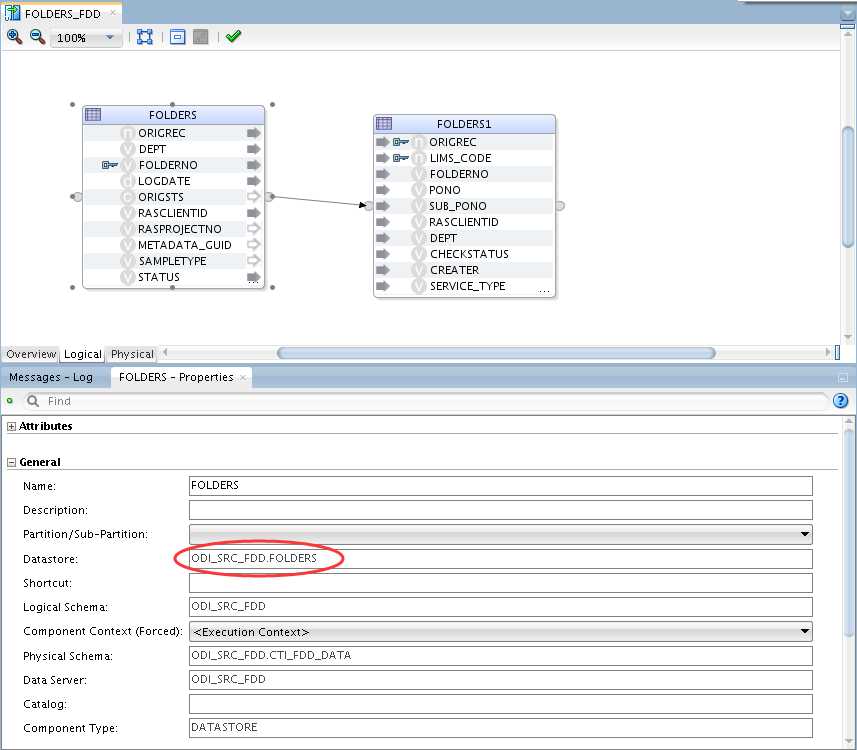
通过定义不同的物理体系结构,为不同库定义不同的工作表前缀,来解决原单结构下工作表共享问题,实现到多库到单库下的数据抽取。
以上是关于ODI多库抽取到一个库解决方案II的主要内容,如果未能解决你的问题,请参考以下文章