ElasticSearch实战-入门
Posted jhhu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch实战-入门相关的知识,希望对你有一定的参考价值。
http://www.cnblogs.com/smartloli/
1.概述
今天接着《ElasticSearch实战-日志监控平台》一文来给大家分享后续的学习,在《ElasticSearch实战-日志监控平台》中给大家介绍一个日志监控平台的架构方案,接下来给大家分享如何去搭建部署这样一个平台,给大家做一个入门介绍。下面是今天的分享目录:
- 搭建部署 Elastic 套件
- 运行集群
- 截图预览
下面开始今天的内容分享。
2.搭建部署 Elastic 套件
搭建 Elastic 套件较为简单,下面我们开始去搭建部署相关套件,首先我们准备必要的环境。
2.1 基础软件
大家可以 Elastic 的官方网站下载对应的安装包,地址如下所示:
[下载地址]
另外,一个基础环境就是需要用到 JDK,ES 集群依赖 JDK,地址如下所示:
[下载地址]
2.2 Logstash 部署
这里我们将 Logstash 的服务部署在中心节点中,其核心配置文件如下所示:
- central.conf

input {
redis {
host => "10.211.55.18"
port => 6379
type => "redis-input"
data_type => "list"
key => "key_count"
}
}
filter {
grok {
match => ["message", "%{IPORHOST:client} (%{USER:ident}|-) (%{USER:auth}|-) \\[%{HTTPDATE:timestamp}\\] \\"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\\" %{NUMBER:response} %{NUMBER:bytes} \\"(%{QS:referrer}|-)\\" \\"(%{QS:agent}|-)\\""]
}
kv {
source => "request"
field_split => "&?"
value_split => "="
}
urldecode {
all_fields => true
}
}
output {
elasticsearch {
cluster => "elasticsearch"
codec => "json"
protocol => "http"
}
}
其代理节点,分别部署在日志生产节点之上,核心配置文件如下所示:
- shipper.conf
input {
file {
type => "type_count"
path => ["/home/hadoop/dir/portal/t_customer_access.log"]
exclude => ["*.gz", "access.log"]
}
}
output {
stdout {}
redis {
host => "10.211.55.18"
port => 6379
data_type => "list"
key => "key_count"
}
}
2.3 Elasticsearch 部署
接着,我们部署 ES 集群,配置较为简单,其配置内容如下所示:
- elasticsearch.yml
node.name: "node1"
这里我只配置了其节点名称信息,集群名称使用默认的,若大家需要配置其他信息可自行处理,需要注意的是,这里在实用 scp 命令分发到其他节点时,需要修改其属性值,保持每个节点的 node.name 值不一样即可。
另外,在安装插件 ES 集群的相关插件时,可以使用以下命令:
- head 插件
sudo elasticsearch/bin/plugin -install mobz/elasticsearch-head
- bigdesk 插件
sudo elasticsearch/bin/plugin -install lukas-vlcek/bigdesk
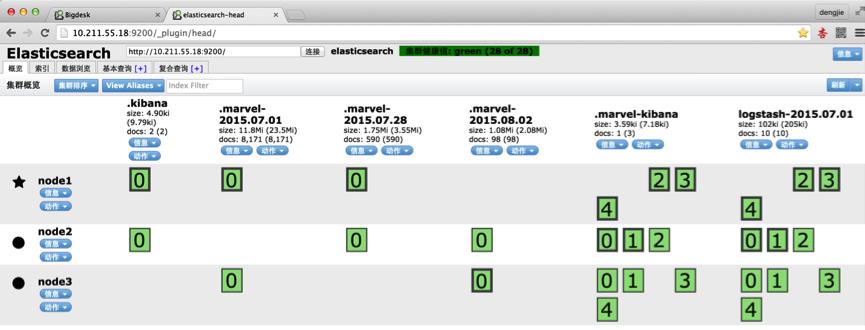
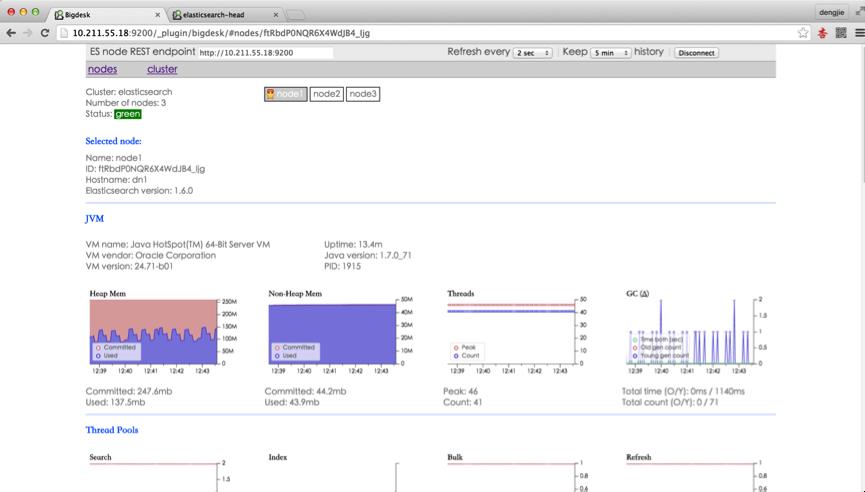
其对应的 Web UI 界面如下图所示:
- head插件的界面
- bigdesk的界面
关于其他的 ES 集群的插件,搭建可以根据实际业务需求进行选择性的安装,这里就不多赘述了。
2.4 Kibana 部署
这里我们需要安装一个能够去可视化 ES 集群数据的工具,这里我们选择 Kibana 工具去可视化我们的数据,其安装较为简单,只需配置对应的核心文件即可,配置如下:
-
kibana.yml
elasticsearch_url: "http://10.211.55.18:9200"
这里去可视化 node1 节点 ES 集群中数据。
3.运行集群
接着,我们启动整个系统,启动步骤如下所示:
- 启动 Redis
[hadoop@dn1 ~]$ redis-server &
- 启动代理节点(分别在其代理节点启动shipper)
bin/logstash agent --verbose --config conf/shipper.conf --log logs/stdout.log &
- 启动中心服务
bin/logstash agent --verbose --config conf/central.conf --log logs/stdout.log &
- 启动 ES 集群(分别在 ES 节点启动)
bin/elasticsearch start
- 启动 Kibana 服务
bin/kibana
4.预览截图
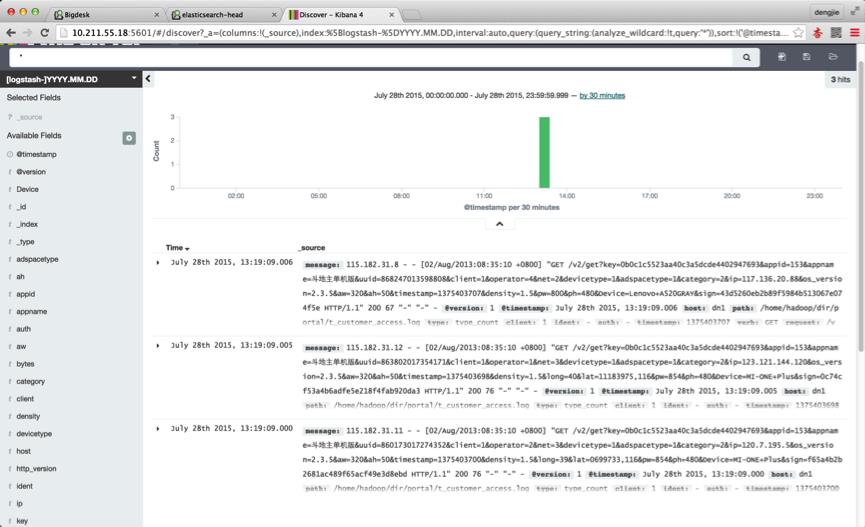
这里,我们可以预览收集的日志,日志信息我只抽取了几条,截图如下:
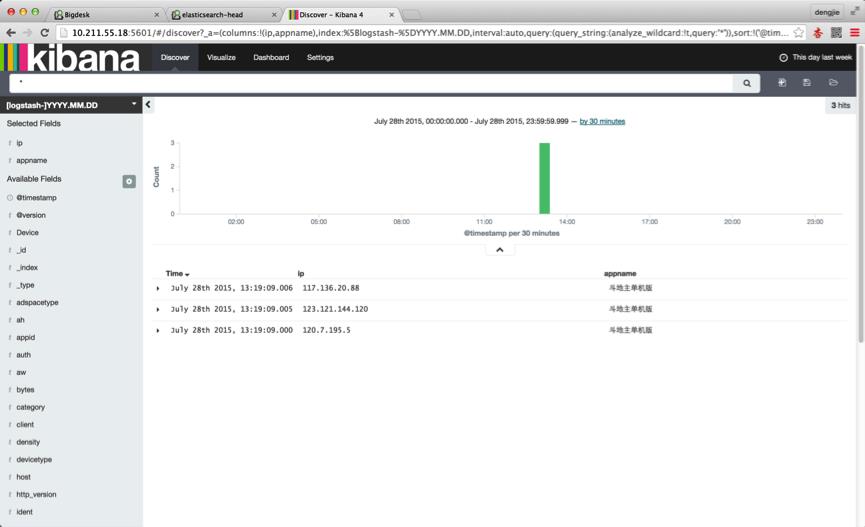
我们还可以使用筛选功能,选取我们需要观察的数据结果,这里我们筛选了 IP 和 AppName 属性进行观察,如下图所示:
5.总结
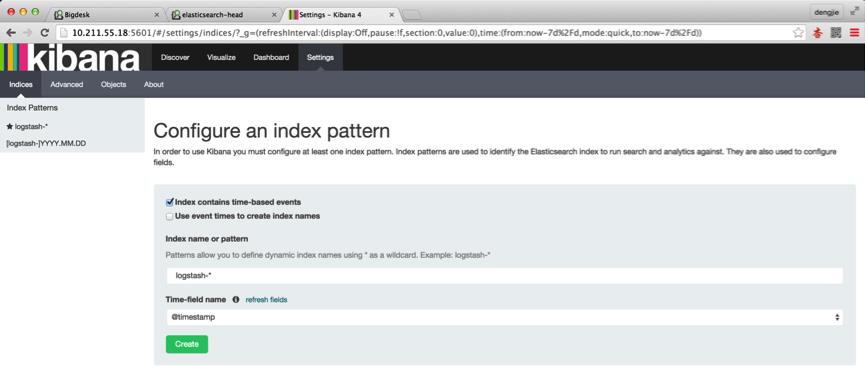
这里需要注意的是,若是我们首次启动 Kibana 服务,收集日志信息为空的情况下,在我们创建索引时,Settings 模块下的界面中 Create 按钮会是灰色状态,导致无法创建,这里大家在创建的时候需要保证我们有日志已被收集存储到 ES 集群。如下图,由于我已收集存储日志到 ES 集群,所以按钮呈现绿色状态,供点击创建。如下图所示:
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于ElasticSearch实战-入门的主要内容,如果未能解决你的问题,请参考以下文章