隐语义模型LFM(latent factor model)
Posted xyq_idata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了隐语义模型LFM(latent factor model)相关的知识,希望对你有一定的参考价值。
对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。总结一下,这个基于兴趣分类的方法大概需要解决3个问题。
- 如何给物品进行分类?
- 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
- 对于一个给定的类。选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
隐含语义分析技术采用基于用户行为统计的自动聚类,较好地解决了上面提出的问题。
隐含语义分析技术的分类来自对用户行为的统计,代表了用户对物品分类的看法。隐含语义分析技术和ItemCF在物品分类方面的思想类似,如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。隐含语义分析技术允许指定最终有多少个分类,这个数字越大,分类的粒度就会越细,反之分类粒度就会越粗。隐含语义分析技术会计算出物品属于每个类的权重,因此每个物品都不是硬性地被分到某一个类中。隐含语义分析技术给出的每个分类都不是同一个维度的,它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给出的类也是相同的维度。隐含语义分析技术可以通过统计用户行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个物品在这个类中的权重就可能比较高。
LFM通过如下公式计算用户u物品i的兴趣:
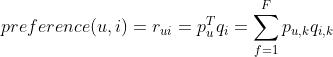
这个公式中和
是模型的参数,其中
度量了用户
的兴趣和第
个隐类的关系,而
度量了第
个隐类和物品
之间的关系。那么下面的问题就是如何计算这两个参数。
要计算这两个参数,需要一个训练集,对于每个用户,训练集里都包含了用户
喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模型参数。
推荐系统的用户行为分为显性反馈和隐性反馈。LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。这里主要讨论的是隐性反馈数据集,这种数据集的特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。
对负样本采样时应该遵循以下原则:
- 对每个用户,要保证正负样本的平衡(数目相似)。
- 对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
下面的python代码实现了负样本采样过程:
def RandomSelectNegativeSample(self, items):
#items是一个dict,它维护了用户已经有过行为的物品的集合
#在这个列表中,物品i出现的次数和物品i的流行度成正比
ret = dict()
for i in items.keys():
ret[i] = 1
n = 0
#将范围上限设为len(items) * 3,主要是为保证正、负样本数量接近。
for i in range(0, len(items) * 3):
#items_pool维护了候选物品的列表
item = items_pool[random.randint(0, len(items_pool) - 1)]
if item in ret:
continue
ret[item] = 0
n += 1
if n > len(items):
break
return ret
以上是关于隐语义模型LFM(latent factor model)的主要内容,如果未能解决你的问题,请参考以下文章