算法之美_源代码发布
Posted 白马负金羁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法之美_源代码发布相关的知识,希望对你有一定的参考价值。
这是TensorFlow文档中的一个例子(参加文献【1】,代码笔者略有改动),可以作为学习TensorFlow的一个实例教程。同时,借由这个例子也可以方便读者理解Softmax,或称多元逻辑回归( Multinomial Logistic Regression),的基本思想。在学习本文之前,读者应该参考如下两篇文章,以补充必要之基础。
- 从逻辑回归到多元逻辑回归(Multinomial Logistic Regression )
- TensorFlow简明入门宝典
一、关于数据集
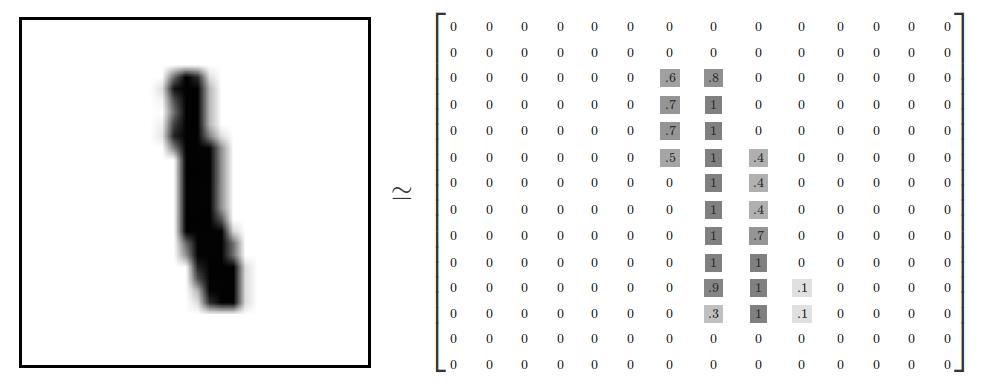
作为例子,我们这里要完成的任务是对0~9这十个手写数字进行分类。所使用的数据集为著名的MINST,其中的每一个输入文件都是像下面中的一个这样的一副大小为28x28的图像。

首先要做的事情当然是引入TensorFlow,并读入数据,因为MNIST这个数据集太有名(几乎是用来做深度学习编程示例的最被频繁使用的一个数据集),TensorFlow中已经将其包含,所以直接用下面的语句就可以将其读入:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)MNIST 数据集被划分成了3个部分:
- 训练数据 (mnist.train),包含 55000 个数据点;
- 测试数据(mnist.test), 包含 10000 个数据点;
- 验证数据(mnist.validation),包含 5000 个数据点。
每一个 MNIST 数据点都包含两部分:一幅手写数字的图像(称为"x")以及一个对应的标签(称为"y")。训练数据集和测试数据集皆是如此。例如,训练数据的图像就是 mnist.train.images,测试数据的标签就是mnist.train.labels。
注意,这里每个输入的图像的都是一个28x28的矩阵(如下图所示),所以也可以看成是28x28=784维的一个向量。
以上是关于算法之美_源代码发布的主要内容,如果未能解决你的问题,请参考以下文章