FFmpeg学习3:播放音频
Posted laughingQing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FFmpeg学习3:播放音频相关的知识,希望对你有一定的参考价值。
参考dranger tutorial,本文将介绍如何使用FFmpeg解码音频数据,并使用SDL将解码后的数据输出。
本文主要包含以下几方面的内容:
- 关于播放音频的需要的一些基础知识介绍
- 使用SDL2播放音频
- 数据队列
- 音频格式的转换
dranger tutorial确实入门FFmpeg比较好的教程,虽然作者在2015年的时候根据新版本的FFmpeg更新了,
但是其中还是有不少API过时了。特别是,教程中使用的是SDL1.0,和现在的SDL2的API也有很大的不同,并且不能兼容。

1. 关于音频的一些基础知识
和视频一样,音频数据也会被打包到一个容器中,其文件的扩展名并不是其编码的方法,只是其打包文件的格式。
现实世界中,我们所听到的声音是一个个连续的波形,但是计算机无法存储和处理这种拥有无限点的波形数据。所以通过重采样,按照一定的
频率(1秒采集多少个点),将有无限个点的连续波形数据转换为有有限个点的离散数据,这就是通常说的A/D转换(模数转换,将模拟数据转换为数字数据)。
通过上面转换过程的描述可以知道,一个数字音频通常由以下三个部分组成:
- 采样频率 采样是在拥有无限个点的连续波形上选取有限个离散点,采集到的离散点越多,也就越能真实的波形。由于声音是在时间上的连续波形,其采样点的间隔就是两次采样的时间间隔。通俗来说,采样率指的是每秒钟采样的点数,单位为HZ。采样率的倒数是采样周期,也就是两次采样的时间间隔。采样率越大,则采集到的样本点数就越多,采样得到的数字音频也就更接近真实的声音波形,相应的其占用的存储空间也就越大。常用的采样频率有:
- 22k Hz 无限广播所用的采样率
- 44.1k Hz CD音质
- 48k Hz 数字电视,DVD
- 96k Hz 192k Hz 蓝光盘,高清DVD
-
采样精度 采集到的点被称为样本(sample),每个样本占用的位数就是采样精度。这点和图像的像素表示比较类似,可以使用8bit,16bit或者24bit来表示采集到的一个样本。同样,一个样本占用的空间越大其表示的就越接近真实的声音。
-
通道 支持不同发声的音响的个数。常用的声道有单声道、双声道、4声道、5.1声道等。不同的声道在采样的时候是不同的,例如双声道,在每次采样的时候有采集两个样本点。
下图是一个三通道的音频示例
- 比特率 指的是每秒传送的比特(bit)数,其单位是bps(Bit Per Second),是间接衡量声音质量的一个标准。
- 没有压缩编码的音频数据,其比特率 = 采样频率 * 采样精度 * 通道数,通过该公式可以看出,比特率越高,采样得到的声音质量就越高,相应的占用的存储空间也就越大。
-
经过压缩编码后的音频数据也有一个比特率,这时候的比特率也可以称之为码率,因为其反映了压缩编码的效率。码率越高,压缩后的数据越大,得到音频质量越好,相应的压缩的效率也就越低。
码率 = 音频文件的大小 / 时长,在时长一定的情况下,码率越高则音频文件越大,其音频的品质也就越高。常见的一些码率: - 96 Kbps FM质量
- 128 - 160 Kbps 比较好的音频质量
- 192Kbps CD质量
-
256Kbps 320Kbps 高质量音频
通常我们所说的比特率(码率)指的是编码后的每秒钟的数据量。码率越高,压缩比就越小,音频文件就越大,相对的音频质量也就越好。码率可以反映出音频的质量,码率越高,音频质量就越,反之亦然。
2.SDL2播放音频
使用SDL播放解码后的音频数据,SDL播放音频数据的流程如下: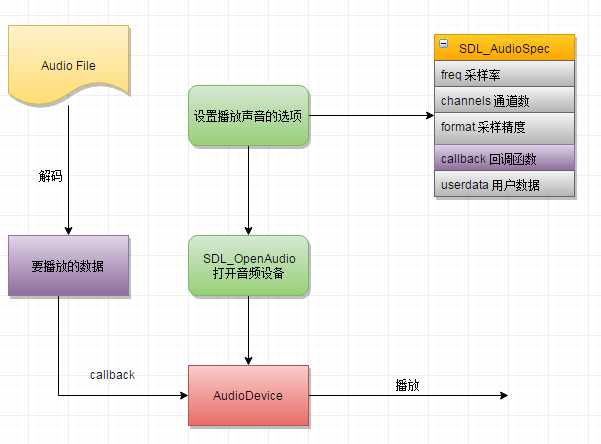
使用SDL播放声音前,首先要设置一些关于音频的选项:采样率,通道数,采样精度,然后还要指定一个回调函数callback以及用户数据(在播放时需要用到的数据指针)。播放音频的时候,SDL将调用回调函数将待播放的音频数据填充到一个特定的缓冲区中。
2.1 SDL_Audiospec
SDL中的结构体SDL_AudioSpec包含了关于音频的格式信息(采样率,通道数,采样精度)和回调函数以及用户数据指针,其声明如下:
typedef struct SDL_AudioSpec
{
int freq; /**< DSP frequency -- samples per second */
SDL_AudioFormat format; /**< Audio data format */
Uint8 channels; /**< Number of channels: 1 mono, 2 stereo */
Uint8 silence; /**< Audio buffer silence value (calculated) */
Uint16 samples; /**< Audio buffer size in samples (power of 2) */
Uint16 padding; /**< Necessary for some compile environments */
Uint32 size; /**< Audio buffer size in bytes (calculated) */
SDL_AudioCallback callback; /**< Callback that feeds the audio device (NULL to use SDL_QueueAudio()). */
void *userdata; /**< Userdata passed to callback (ignored for NULL callbacks). */
} SDL_AudioSpec; - freq 每秒钟发送给音频设备的sample frame的个数,通常是11025,220502,44100和48000。(sample frame = 样本精度 * 通道数)
- fromat 每个样本占用的空间大小及格式,例如 AUDIO_S16SYS,样本是有符号的16位整数,字节顺序(大端还是小端)和系统一样。更多的格式可参考SDL_AudioFormat。
- channels 通道数,在SDL2.0中支持1(mono),2(stereo),4(quad)和6(5.1)
- samples 缓冲区的大小( sample frame为单位)。
- silence 音频数据中表示静音的值是多少
- size 缓冲区的大小(字节为单位)
- callback 用来音频设备缓冲区的回调函数
- userdata 在回调函数中使用的数据指针
2.2 回调函数
callback用来取音频数据给音频设备,其声明如下:
void (SDLCALL * SDL_AudioCallback) (void *userdata, Uint8 * stream,int len) ;- userdata 就是SDL_AudioSpec结构体中的userdata字段
- stream 要填充的缓冲区
- len 缓冲区的大小
在回调函数内要首先初始化缓冲区stream,并且在回调函数返回结束后,缓冲区就不再可用了。对于多声道的音频数据在缓冲区中是交错存放的
- 双声道 LRLR
- 四声道 front-left / front-right / rear-left /rear-right
- 5.1 front-left / front-right / center / low-freq / rear-left / rear-right
2.3 打开音频设备
在设置后需要参数(填充好SDL_AudioSpec的各个字段)后,下面要做的就是打开音频设备。函数SDL_OpenAudioDevice用来打开声音设备,其声明如下:
SDL_OpenAudioDevice(const char *device,int iscapture,const SDL_AudioSpec *desired, SDL_AudioSpec *obtained,int allowed_changes); -
该函数需要的第一个参数是音频设备的名称,调用
SDL_GetAudioDeviceName根据设备的编号获取到设备的名称。下面这段代码用来输出所有的设备名称:int count = SDL_GetNumAudioDevices(0); for (int i = 0; i < count; i++) { cout << "Audio device " << i << " : " << SDL_GetAudioDeviceName(i, 0); } - iscapture 设为0,非0的值在当前SDL2版本还不支持
- desired 期望得到的音频输出格式
- obtained 实际的输出格式
- allowed_changes 期望和实际总是有差别,该参数用来指定 当期望和实际的不一样时,能不能够对某一些输出参数进行修改。
设为0,则不能修改。设为如下的值,则可对相应的参数修改:- SDL_AUDIO_ALLOW_FREQUENCY_CHANGE
- SDL_AUDIO_ALLOW_FORMAT_CHANGE
- SDL_AUDIO_ALLOW_CHANNELS_CHANGE
- SDL_AUDIO_ALLOW_ANY_CHANGE
调用 SDL_OpenAudioDevice打开音频设备后,就会为callback函数单独开启一个线程,不断的将音频发送的音频设备进行播放.
3. 数据队列
上面已经设定音频输出的格式,打开了音频设备,并且开启了传送音频数据的线程(callback函数),就等着FFmpeg解码的音频数据了。
在介绍音频数据的组织之前,先来看下在本文中音频的播放的整个流程,如下图所示: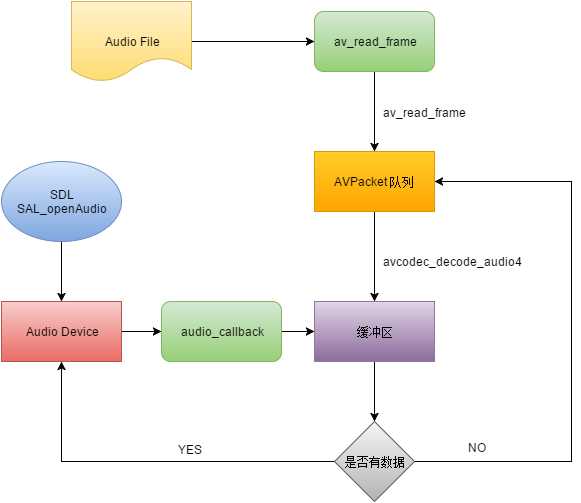
前期的准备工作,如打开音频文件,查找音频流,找到音频解码器等过程,和视频类似,这里不再赘述。
从上图可知,首先不再对从音频流中读取到的AvPacket进行解码,而是将其缓存到一个AVPacket队列中。当callback函数从缓冲区中
取数据发送到音频设备时,从AVPacket队列中取出Packet,解码后填充到缓冲区。
所以首先要做的就是创建一个AVPacket队列,可以使用FFmpeg中的AVPacketList作为队列的一个节点,队列的声明如下:
typedef struct PacketQueue
{
AVPacketList *first_pkt; // 队头
AVPacketList *last_pkt; // 队尾
int nb_packets; //包的个数
int size; // 占用空间的字节数
SDL_mutex* mutext; // 互斥信号量
SDL_cond* cond; // 条件变量
}PacketQueue; 注意,AVPacket队列实际会有两个线程访问:主线程和callback函数,所以这里声明了一个互斥信号量来保证对队列的正确读写,
以及一个条件变量进行线程的同步操作。
对队列的操作有下面两个方法:
-
packet_queue_put 向队尾插入一个Packet
在向队尾插入元素时要先进行lock操作,插入完成SDL_LockMutex(q->mutext); if (!q->last_pkt) // 队列为空,新插入元素为第一个元素 q->first_pkt = pktl; else // 插入队尾 q->last_pkt->next = pktl; q->last_pkt = pktl; q->nb_packets++; q->size += pkt->size; SDL_CondSignal(q->cond); SDL_UnlockMutex(q->mutext);SDL_CondSignal(q->cond)通知取数据的线程,已有新插入的数据。 -
packet_queue_get,取出队首Packet。由于向队列的插入数据实在主线程中完成的,而取数据则是在callback线程中进行的,所以有可能在
取数据的时候,队列为空。在packet_queue_get中有一个block参数,指定在无数据的时候是否阻塞线程等待。while (true) { pktl = q->first_pkt; if (pktl) { q->first_pkt = pktl->next; if (!q->first_pkt) q->last_pkt = nullptr; q->nb_packets--; q->size -= pktl->pkt.size; *pkt = pktl->pkt; av_free(pktl); ret = 1; break; } else if (!block) { ret = 0; break; } else { SDL_CondWait(q->cond, q->mutext); } }在队列无数据的时候,设定为阻塞等待则
SDL_CondWait(q->cond, q->mutext)等待,不然就直接返回。
4. 解码音频及其格式转换
已经准备好了Packet队列,下面要做的就是从 Audio File中取出Packet并填充到Packet Queue中,然后在callback函数中对Packet进行
解码,并将解码后的数据传送到音频设备播放。
4.1 插入Packet
packet_queue_init(&audioq);
SDL_PauseAudio(0);
AVPacket packet;
while (av_read_frame(pFormatCtx, &packet) >= 0)
{
if (packet.stream_index == audioStream)
packet_queue_put(&audioq, &packet);
else
av_free_packet(&packet);
} 首先初始化PacketQueue,SDL_PauseAudio是让音频设备开始播放,如果没有提供数据,则播放静音。接着一个while循环将,从音频
流中提取Packet,放入到队列中。插入到队列中的Packet没有被free,等到packet被解码后,才会被free掉。
4.2 取出Packet并解码
Packet已经放入到队列中,接下来就要在callback函数中,取出packet并解码传送到音频设备。
void audio_callback(void* userdata, Uint8* stream, int len)
{
AVCodecContext* aCodecCtx = (AVCodecContext*)userdata;
int len1, audio_size;
static uint8_t audio_buff[(MAX_AUDIO_FRAME_SIZE * 3) / 2];
static unsigned int audio_buf_size = 0;
static unsigned int audio_buf_index = 0;
SDL_memset(stream, 0, len);
while (len > 0)
{
if (audio_buf_index >= audio_buf_size)
{
audio_size = audio_decode_frame(aCodecCtx, audio_buff, sizeof(audio_buff));
if (audio_size < 0)
{
audio_buf_size = 1024;
memset(audio_buff, 0, audio_buf_size);
}
else
audio_buf_size = audio_size;
audio_buf_index = 0;
}
len1 = audio_buf_size - audio_buf_index;
if (len1 > len)
len1 = len;
memcpy(stream, (uint8_t*)(audio_buff + audio_buf_index), audio_buf_size);
len -= len1;
stream += len1;
audio_buf_index += len1;
}
} 在callback函数中,设置了一个静态的数据缓冲区 static uint8_t audio_buff[(MAX_AUDIO_FRAME_SIZE * 3) / 2],callback函数每次向音频设备传送数据时,首先检测静态缓存区中是否有数据,有则直接复制到stream中memcpy(stream, (uint8_t*)(audio_buff + audio_buf_index), audio_buf_size);;否则调用audio_decode_frame函数,从Packet 队列中取出Packet,将解码后的数据填充到静态缓冲区,然后再传送到音频设备。
4.3 解码数据并进行格式转换
在callback函数中调用audio_decode_frame函数,解码Packet队列中的Packet。audio_decode_frame声明如下:
int audio_decode_frame(AVCodecContext* aCodecCtx, uint8_t* audio_buf, int buf_size) audio_buf是callback函数中定义的静态缓存空间,该函数将解码后的数据填充到该空间。
int got_frame = 0;
len1 = avcodec_decode_audio4(aCodecCtx, &frame, &got_frame, &pkt);
if (len1 < 0) // 出错,跳过
{
audio_pkt_size = 0;
break;
}
audio_pkt_data += len1;
audio_pkt_size -= len1;
data_size = 0;
if (got_frame)
{
data_size = av_samples_get_buffer_size(nullptr, aCodecCtx->channels, frame.nb_samples, aCodecCtx->sample_fmt, 1);
assert(data_size <= buf_size);
memcpy(audio_buf, frame.data[0], data_size);
} 得到解码后的数据后,还有一个问题就是,输入的音频格式可能和SDL打开的音频设备所支持的格式不一致,所以在将数据放入到callback的静态缓冲区前,需要做一个数据格式的转换。
首先创建一个SwrContext,并设定好转换参数,并初始化该SwrContext。
SwrContext* swr_ctx = nullptr;
if (swr_ctx)
{
swr_free(&swr_ctx);
swr_ctx = nullptr;
}
swr_ctx = swr_alloc_set_opts(nullptr, wanted_frame.channel_layout, (AVSampleFormat)wanted_frame.format, wanted_frame.sample_rate,
frame.channel_layout, (AVSampleFormat)frame.format, frame.sample_rate, 0, nullptr);
if (!swr_ctx || swr_init(swr_ctx) < 0)
{
cout << "swr_init failed:" << endl;
break;
}设定的swr选项有三个:数据布局channel_layout,样本的精度format和每秒的sample个数sample_rate,需要设定转换前后的这三个参数。
int dst_nb_samples = av_rescale_rnd(swr_get_delay(swr_ctx, frame.sample_rate) + frame.nb_samples,
wanted_frame.sample_rate, wanted_frame.format, AVRounding(1));
int len2 = swr_convert(swr_ctx, &audio_buf, dst_nb_samples,
(const uint8_t**)frame.data, frame.nb_samples);参数设定好后,在进行转换前,还需要计算出转换后的sample的个数,上面代码中的dst_nb_samples。然后调用swr_convert就完成了输入的音频到输出音频格式的转换
5 总结
本文主要参考dranger tutorial的播放音频教程,对使用FFmpeg + SDL播放音频做了个总结。主要以下内容:
- 关于音频的一些基础知识:采样率,通道,比特率等
- SDL2播放音频的流程
- 使用Packet队列,FFmpeg解码
在FFmpeg解码,然后发送给音频设备的时候要进行音频格式的转换,不然在播放的时候有可能有杂音。
接下来打算对AVPacket这个结构体进行个分析,在总结的时候发现AVPacket中的数据缓存管理还是有点复杂的。而且,在本文代码中使用的av_dup_packet和av_packet_free已经废弃了。
/**
* Free a packet.
*
* @deprecated Use av_packet_unref
*
* @param pkt packet to free
*/
attribute_deprecated
void av_free_packet(AVPacket *pkt);
/**
* @warning This is a hack - the packet memory allocation stuff is broken. The
* packet is allocated if it was not really allocated.
*
* @deprecated Use av_packet_ref
*/
attribute_deprecated
int av_dup_packet(AVPacket *pkt); 本文代码FFmpeg3.cpp
以上是关于FFmpeg学习3:播放音频的主要内容,如果未能解决你的问题,请参考以下文章