一、URL
在http传输中、我们都是通过url来寻找网络资源的。但是你真的了解url吗?你知道url的构成是怎么样的吗?如果你知道,那好吧、恭喜你、可以跳过URL这一小节了。oh~~ if not ,请跟我一起来认识一下我们每天都要敲上几百次的URL吧!
首先说url(Uniform Resource Locator)的构成。URL是由三部分组成的,
传输协议+域名或IP地址+端口(缺损为80)+资源具体地址。如果要指定访问端口时需要用“
:”来隔开例如(http://www.baidu.com:80/index.
php)。
例如:http://www.baidu.com/index.php(传输协议为http,域名或IP是www.baidu.com,资源具体地址为index.php)。一般情况下浏览器已经帮我们做了很多事情、比如前面的传输协议、在没有指定特定资源路径时、默认加上"/"表示请求默认资源(即例子中的index.php)。因此默认情况下在你键入www.baidu.com的时候浏览器就自动为你加上了"http://"以及结尾的"/"。
如图:
二、资源请求(Request)
首先、在我们请求一个URL的时候我们想目标主机发送了些什么东西呢?这很简单、我们只需要通过浏览器的开发者工具就能看到、下面我们就以访问百度(www.baidu.com)为例子,看看我们在请求一个URL的时候、客户端向服务器发送了那些东西?Request消息结构又是怎么的呢?
如图(感谢share的朋友,让我省去了自己画图的时间^_^):Request的消息组成结构是这样的三部分,
第一部分就是图上的第一行、称为RequestLine(请求行)对应图中METHOD/ path所在行。
第二部分为RequestHeader(请求头)对应图中的Header-Name-1所在的区域。
第三部分为请求内容、就是途中的Optional request body部分。
第一行中、METHOD表示请求方式、常见的如:
| GET:向Web服务器请求一个资源
POST:向Web服务器发送资源
PUT:向Web服务器发送资源并存储在服务器上
DELETE:从Web服务器上删除一个资源
|
当请求方式为Get的时候请求的body部分为空此时有可能在URL中跟着参数、此时。参数将在RequestHeader区域中。在path - to - resource部分则是请求资源名称,比如URL(www.baidu.com/index.php)那么path - to - resource 将由index.php替换,最后的HTTP/Version-number表示请求使用的协议类型和版本。
在RequestLine中、我们向服务器申明了我们的请求方式(METHOD),请求资源(path - to - resource)以及协议类型和版本(HTTP/Version-number);
RequestHeader中有许多参数、比如下图、我们访问百度首页(www.baidu.com)时的Request信息:
从上面的请求中我们可以得知、我问是采用get的方式请求www.baidu.com(缺损端口80上的默认资源),请求协议是HTTP、版本是1.1、状态为长连接、并告诉服务器我们能接收解析gzip、deflate、sdch这三种压缩方式的数据、我们接收的语言为zh-CN,并且我们请求是携带了cookie信息。
下面我们需要了解一下这些常用的参数到底是什么意思、以及起什么作用。
| Host:表示请求服务器地址(域名/ip)。
Connection:表示是否需要持久连接、在HTTP 1.1的时候、默认进行的是长连接、也就是连接处于keepalive状态、其优点是、在资源包含多个元素是(比如web页面中的图片)将减少下载时间,当Connection为Keep-Alive时、表示在Keep-Alive时间内不会断开连接。而非KeepAlive模式时、请求之后都将会断开。
Accept:指定客户端能够接受的内容类型、按照先后顺序表示客户端接受的先后次序、如上图中的Accept:text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8.
User-Agent:表示请求的客户端浏览器详细信息、通过这些信息服务器可以判断当前客户端口浏览器类别。
DNT:DO NOT TRACK 的缩写、要求服务器不要跟踪记录用户信息。为1时表示开启、0时表示关闭。主流浏览器都支持这些、在chrome,firefox中你可以在设置中找到这个设置项。
Accept-Encoding:浏览器能处理的编码、非字符编码而是指资源压缩方法(是否支持压缩、支持那种类型的压缩gzip,deflate等)。
Accept-Language:客户端申明自己所能接收的语言、比如gb2312 utf-8 等、语言和字符集的关系是、语言中包含了字符。
Cookie:浏览器在请求时如果本地存在请求服务器的资源的Cookie信息时、则在Request的时候将会带上这对Cookie信息、帮助服务器识别是否是历史访问人员(网站的请记住我功能就是采用这种方式实现的。将用户的信息通过respoonse时回写到客户端的cookie中。当用户第二次再访问时首先检查访问者是否携带了有效的cookie来做不同的UI呈现或者免登录之类的),cookie内容由服务器程序自行协定、主要格式为name(cookie名称),value(cookie名称对应的值)[Name-Value采用键值对的方式存储],Domain(域名地址),Path(资源路径,用于控制cookie的有效访问范围),Max-Age(有效期、单位为秒,超过这个时间则过期失效。)。对了。其实session也是通过cookie存储的。只不过cookie存储session的时候存储的是一个seesionid。而session实际是存储在服务器进程中的。
更具体的本文将不再阐述、请参照这个地址对查请求头参数核查地址或者这个。
总结:方法就是为了告诉服务器需要做什么。
|
值得注意的是、报文的流向始终是流向下游的(以请求点为起点、想下游流动、如果是客户端发起请求则请求报文流向是[客户端,代理1,代理2.,····服务器],响应报文反之。)
三、服务器响应(Response)
在我们发起一个请求时、被请求的服务器一定会给我们返回一点什么(假设与服务器取得连接)?返回的是什么呢?如果请求成功,将返回我们请求的结果、请求失败将返回错误信息、以及请求的处理状态等等。客户端就是通过服务器返回的请求的状态来判断请求的结果,因此再讲请求响应的时候我们必须先了解响应的状态。
响应状态码用于表示服务器对请求的各种不同处理结果和状态,他是一个三维的十进制数。响应状态码可以归类为5种,使用最高位为1到5来进行分类,如下:
| (1)100-199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
(2)200-299:表示成功接收请求并完成整个处理过程。
(3)300-399:未完成请求,客户需要进一步细化请求,例如请求的资源已经移动到一个新的地址。
(4)400-499:客户端的请求错误。
(5)500-599:服务端出现错误。
|
关于状态值,点击这里有官方的解释。
同样、首先我们还是来看看协议头结构,如下图、和Request是一样的。同样是三部分
第一部分就是图上的第一行、称为ResponseLine(请求行)对应图中METHOD/ path所在行。
第二部分为ResponsetHeader(请求头)对应图中的Header-Name-1所在的区域。
第三部分为请求内容、就是途中的Optional request body部分。
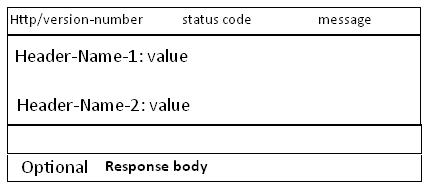
HTTP/version-number就是协议版本 而status code就是上面描述的状态码。message就是返回状态消息。
同样以访问百度首页为例子,我们得到的Response信息如下图
从图上可以知道、我们请求的www.baidu.com响应了一个状态码(status code)为:200 message为:ok。响应内容(Content-Type对应的值)类型为"text/html;"编码方式为utf-8,响应类容编码(Content-Encoding)的传输编码方式(非字符编码方式而是压缩方式如 chunked, deflate, gzip)为chunked。以及回写的Cookie信息等。
其中各种实体对象的意思与解释请
猛戳这里就不再赘述了。我将在后续博文中详细阐述有关状态码和实体对象的作用。
总结一下这篇博文:
首先我们从新认识了一下URL,它的组成与结构。
其次我们回顾探究了我们在访问一个资源时、我们告诉并携带了那些信息给服务器。及Request结构组成和内容。
最后我们反过来探究了、我们的请求被响应之后、服务器回传给我们了哪些信息、及Response的结构和内容。
下一篇我们将深入的学习status code——状态码。以及每个不同状态码对应的什么意思、状态码对我们开发人员有什么作用和意义。
最后更新一张请求报文和响应报文的对比图,图片来自《HTTP权威指南》
有兴趣的可以猛戳→→→→Web_Sniffer-------这里你可以任意的输入有效域名。就能很清楚的看到Request和Response的信息。
http://blog.csdn.net/zhll3377/article/details/7748086






