HDFS读写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读写相关的知识,希望对你有一定的参考价值。

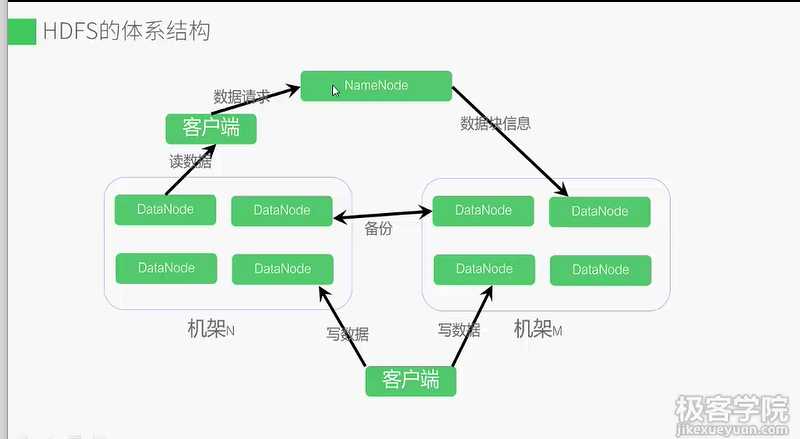
Master-slaver结构,namenode是中心服务器维护着文件系统树和整个树内的文件目录,
负责整个数据集群的管理。datanode分布在不同的机架上,在客户端和namenode的调度下
存储并检索数据块,并且定期向namenode发送所存储的块的列表。客户端通过datanode和namenode
的交互访问文件系统。联系namenode获取文件的元数据,真正的IO操作直接和datanode交互。
数据块在不同的datanode上备份以应对节点故障。默认每个数据块都保存三个副本,其中两个副本存在不同
机架两个不同节点上,另一个副本存在不同机架的节点上。

默认数据块大小64M
元数据指文件和目录的属性信息。
镜像文件中记录修改时间,访问时间,数据块大小,组成一个文件的数据块存储位置
目录中镜像文件包含修改时间,访问控制权限。
日志文件记录HDFS 所有跟新操作
namenode启动时,合并镜像文件和日志文件。把内存中的元数据跟新到最新状态。
i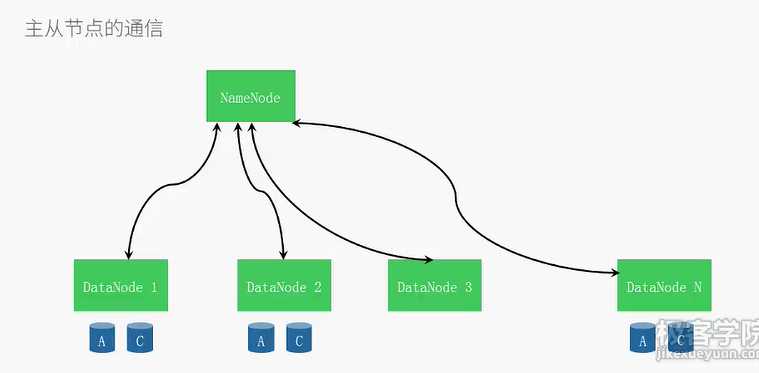
每3sdatanode向namenode发送心跳,显示自己存活,每10次心跳发送一次数据块报告,‘
包含自己存储的数据块信息通过这些信息,namenode能重建元数据,并确保每个数据块有足够的副本。
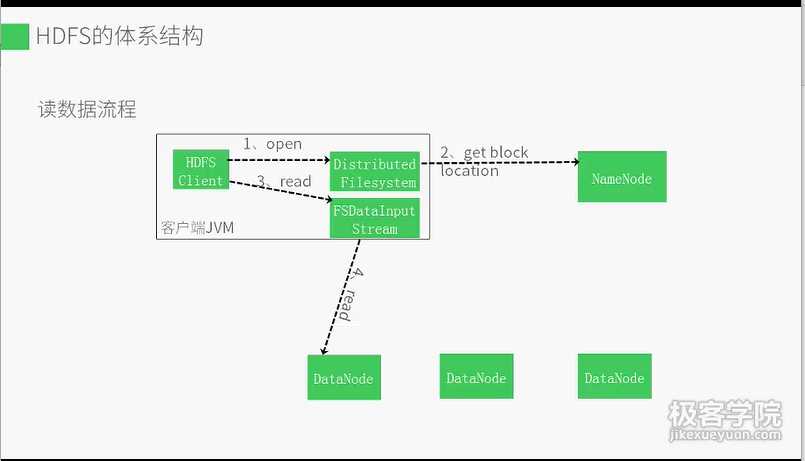
1客户端打开分布式文件系统
2分布式文件系统通过远程过程调用访问namenode,
读到数据块信息,datanode地址
3客户端通过文件系统输入输出流读数据
4向距离最近的datanode读取数据
5出错则向副本发起连接,并记录,以后不再连接
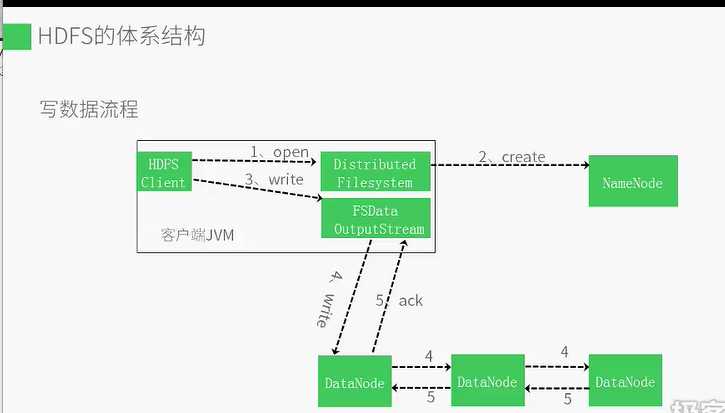
1客户端打开分布式文件系统
2分布式文件系统通过远程过程调用访问namenode
3namenode首先确认文件不存在,然后创建一个新的文件
4客户端通过文件系统输入输出流写入数据
5FSDataOutputStream将数据分成块写入队列
6DataStreamer处理数据队列,根据数据队列,要求namenode分配适合的datanode来存储数据副本,每个数据块默认赋值三块
7然后将数据发送给第一个datanode,第一个datanode将数据发送给第二个datanode,第二个datanode将数据块发送个第三个datanode
8数据写好后,向FSDataOutputStream发送ACK,FSDataOutputStream调用close向namenode通知写入完成,
以上是关于HDFS读写的主要内容,如果未能解决你的问题,请参考以下文章