Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Posted klitech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)相关的知识,希望对你有一定的参考价值。
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法。其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动。通过柯西施瓦兹公式可以证明梯度反方向是下降最快的方向。
经典的梯度下降法利用下式更新参量,其中J(θ)是关于参量θ的损失函数,梯度下降法通过不断更新θ来最小化损失函数。当损失函数只有一个global minimal时梯度下降法一定会收敛于最小值(在学习率不是很大的情况下)
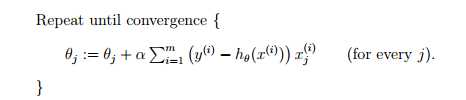
上式的梯度是基于所有数据的,如果数据量比较大时,这就会导致每次更新参量时都需要计算整个数据集而使计算量很大。
因此梯度下降法又衍生出一下其他形式,随机梯度下降法就是其中之一。顾名思义,所谓随机就是随便选取一个或一组数据去代替整个数据集来更新参数,这样计算量就会大大减少。很多文章中的随机梯度下降都只随机选取一个数据作为参考,因此有时也称为online-GD,当随机选取一组数据时又称mini-batch GD,其实本质上应该都是SGD(我是这么理解的。。),其参数更新如下。
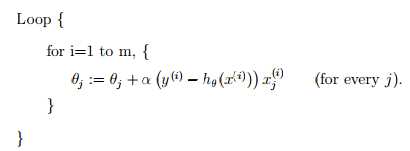
随机选取的方式有几种包括:
1,随机随机排列数据后,迭代更新参量直至收敛
2,每次迭代时都进行数据随机排列
3,每次迭代时从数据中随机选取一个数据

这是Quora上一个关于GD与SGD的比较好的回答
以上是关于Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)的主要内容,如果未能解决你的问题,请参考以下文章