(转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
Posted The Blog of Xiao Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道相关的知识,希望对你有一定的参考价值。
技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
近年来,随着深度学习的崛起,计算机视觉得到飞速发展。目标检测作为计算机视觉的基础算法,也搭上了深度学习的快车。基于Proposal的检测框架,从R-CNN到Faster R-CNN,算法性能越来越高,速度越来越快。另一方面,直接回归Bounding Box的框架,从YOLO到SSD,在保持速度优势的同时,性能也逐渐得到提升。“深度学习大讲堂”往期介绍过这方面的进展,在此不再赘述。
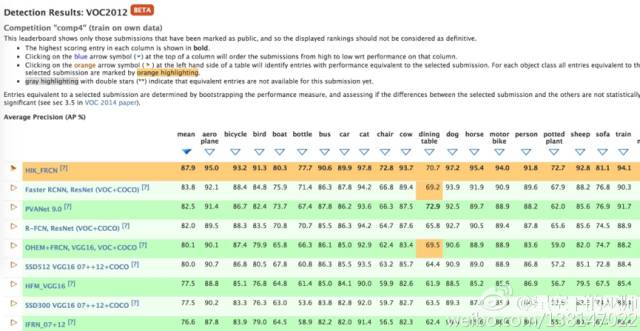
近期,我们在PASCAL VOC2012目标检测上提交的结果mAP性能达到87.9,刷新了世界记录,排名第一名,如下图所示:
1.寻找更优的网络结构
”Features matter.” 去年MSRA凭借ResNets [2]取得了多项任务性能上的突破。以ResNet-101为基准,有没有网络可以提供更优的特征?我们验证了以下几个网络。 a) 进一步增加网络深度。在12GB显存容量的限制下,101层的网络已经是极限。然而,如果把预训练模型的BN层参数融合进前一层卷积层,然后去掉BN层,则可以容纳ResNet-152。根据我们的实验,在ImageNet DET数据集上,去掉BN层的ResNet-152比保留BN层的ResNet-101还要差约1个点。这说明BN层的作用还是比较重要的。 b) BN层的训练策略。我们发现训练时如果更新BN层的参数,相比固定参数,性能会下降一大截。原因可能是Faster R-CNN训练时batch size只有1,batch之间的均值/方差变化太大,太不稳定。 c) MSRA和Facebook相继公开了自己训练的ResNets模型。后续MSRA又提出了Identity Mapping版本的ResNets [3]。我们验证发现,Identity Mapping版本的ResNet-101检测性能略优于MSRA的原始ResNet-101模型和Facebook的模型。
2. 改进RPN Proposal
在Faster R-CNN框架里面,RPN提取Proposal和FRCN对Proposal进行分类其实是2个独立的问题。针对RPN,我们做出了以下2处改进: a) 均衡正负Anchor比例。理想状态下,RPN 正负Anchor的比例是1:1。我们发现,在batch size比较大(256)的情况下,这个比例会非常悬殊。特别是目标数量比较少的图像,正的Anchor数量会非常少。这样训练出来的模型会偏向于背景类别,容易漏检。我们对这个比例做了限制,让负样本数量不超过正样本的1.5倍,发现Proposal的召回率可以提高5个点。 b) 级联RPN。受CRAFT [4]的启发,我们设计了自己的级联RPN。[4]中先得到标准的RPN Proposal,然后用一个分类性能更强的FRCN分支来改进Proposal质量。我们则是用了2个标准的RPN(图 1)。第一个RPN用滑窗得到的Proposal作为Anchor,第二个RPN用第一个RPN输出的Proposal作为新的Anchor位置。相比[4],我们的算法优势是实现简单,额外增加的计算量非常少。对于中大目标,可以明显提升Proposal位置的准确度。

3. 全局上下文建模
每个Proposal对应原始图像中的一个ROI区域。对这个ROI区域进行分类时, FRCN先把ROI映射到中间特征图上,然后在中间特征图上做裁剪(RoIPooling)。裁剪出来的小特征图输入到CNN分类器中。可以看到,CNN分类只使用了ROI区域内的局部特征。实际上,ROI周围的上下文信息对于判断这个ROI类别是很有帮助的。例如对一个乒乓球分类,很容易和光源混淆。如果知道周围有乒乓球拍、乒乓球台等目标,则更容易判断这是个乒乓球。 全局上下文建模是从整幅图像提取特征,然后和每个Proposal的局部特征相融合,用于分类。去年MSRA [2]使用全局上下文,得到了1个点的性能提升。然而他们没有发布具体的实现细节。我们实现的全局上下文网络结构如图 2所示。
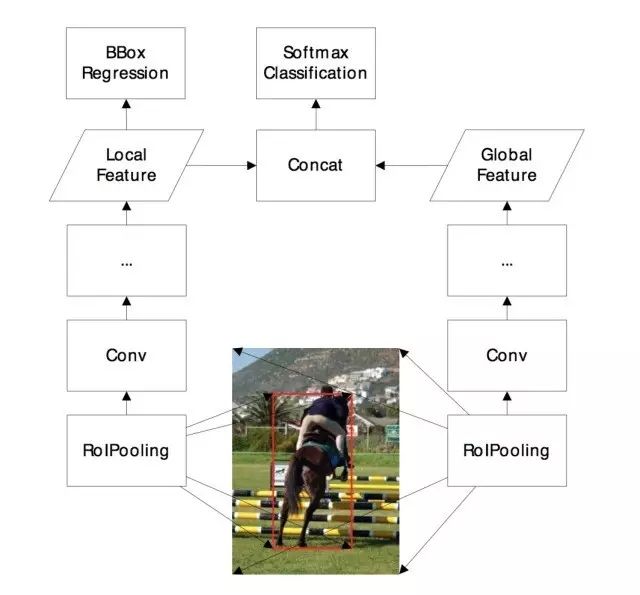
我们发现,对于图中的全局上下文网络分支,训练时如果采用随机初始化,性能提升非常有限。如果用预训练的参数初始化,在ImageNet DET验证集上可以得到超过3个点的性能提升。对于ResNets,RoIPooling后面的conv5有9层卷积。而Faster R-CNN finetune时一般初始学习速率又会设得比较小(0.001)。这就导致从头训练这9层卷积比较困难。因此,这里预训练显得尤为重要。另外,[2]还把全局上下文特征同时用于分类和Bounding Box回归。我们发现全局上下文特征对于Bounding Box回归没有帮助,只对分类有帮助。
4. 训练技巧
a) 平衡采样。很多数据集存在样本不均衡的问题,有些类别特别多,有些类别特别少。训练模型时,从一个图像列表中依次读取样本训练。这样的话,小类样本参与训练的机会就比大类少。训练出来的模型会偏向于大类,即大类性能好,小类性能差。平衡采样策略就是把样本按类别分组,每个类别生成一个样本列表。训练过程中先随机选择1个或几个类别,然后从各个类别所对应的样本列表中随机选择样本。这样可以保证每个类别参与训练的机会比较均衡。在PASCAL VOC数据集上,使用平衡采样性能可以提升约0.7个点。 b) 难例挖掘(OHEM [5])。使用了难例挖掘后,收敛更快,训练更稳定。在ImageNet DET数据集上,性能可以提升1个多点。 c) 多尺度训练。使用多尺度训练的话,可以让参与训练的目标大小分布更加均衡,使模型对目标大小具有一定的鲁棒性。
5. 预测技巧
预测阶段,我们用了多尺度预测,水平翻转,和检测框投票。这些策略的具体实现在很多文献中都有描述。这里我们可以分享一下多个检测结果的融合策略。当使用多尺度预测,水平翻转,还有多模型Ensemble时,对于同一张测试图像,我们会得到好几组结果。对于这些结果,最直观的融合方式就是把所有的检测框放在一起,然后用非极大值抑制(NMS)处理一下。但是我们发现另一种方式效果更好,就是把RPN和FRCN分开来做。先对RPN做多尺度、水平翻转、多模型的融合,得到一组固定的Proposal之后,再对FRCN进行多尺度、水平翻转、多模型的融合。RPN的融合用NMS更好,FRCN的融合用对Proposal的置信度和Bounding Box位置取平均值的方式更好。 总结
本文总结了我们做出的一些Faster R-CNN改进技巧,并分享了算法实现过程中遇到的细节问题。正如谚语所言,”The devil is in the details.” 希望我们的这些算法细节对同行以及相关的算法爱好者们提供一定的帮助和指引。我们抛砖引玉,期待同行们也可以分享自己的经验。
参考文献
[1] Ren,Shaoqing, et al. "Faster R-CNN: Towards real-time object detection withregion proposal networks." Advances in neural information processingsystems. 2015.
[2] He,Kaiming, et al. "Deep residual learning for image recognition." arXivpreprint arXiv:1512.03385 (2015).
[3] He,Kaiming, et al. "Identity mappings in deep residual networks." arXivpreprint arXiv:1603.05027 (2016).
[4] Yang,Bin, et al. "Craft objects from images." arXiv preprint arXiv:1604.03239(2016).
[5] Shrivastava,Abhinav, Abhinav Gupta, and Ross Girshick. "Training region-based objectdetectors with online hard example mining." arXiv preprintarXiv:1604.03540 (2016).
该文章属于“深度学习大讲堂”原创,如需要转载,请联系loveholicguoguo。
作者简介
 钟巧勇
钟巧勇本科毕业于南京大学,博士毕业于中科院上海生科院计算生物学研究所。2014年加入海康威视研究院,现任高级研究员。主要从事深度学习,计算机视觉方面的算法研究工作,研究方向是基于深度学习的目标检测。海康威视研究院招贤纳士,欢迎投简历至:
以上是关于(转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道的主要内容,如果未能解决你的问题,请参考以下文章