常见机器学习算法原理+实践系列3(PCA)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见机器学习算法原理+实践系列3(PCA)相关的知识,希望对你有一定的参考价值。
PCA主成份分析
PCA(Principal Component Analysis)主要是为了做数据降维,数据从原来的坐标系转换到登录新的坐标系,新坐标系的选择是由数据本身决定的,第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差,该过程一直重复,重复次数为原始数据中特征的数据。通常情况下,大部分方差都包含在前面的几个新坐标轴中,所以一般情况下我们选择前面几个贡献值较大的(90%以上)就是主成份了。
通过这种降维技术,它能将大量相关变量转化为一组很少的相关变量,这些无关变量称为主成份,比如原始的特征为x1,x2,……xk,通过一些新坐标轴的投影之后,第一主成份可能变成了pc1=a1*x1+a2*x2+……+ak*xk类似的,它是k个特征的加权组合,对初始数据集的方差解析性最大。
PCA有如下几个步骤:
1,原始矩阵A去除平均值(求出每个特征原始的平均值,原始矩阵减去这个平均值之后生成一个新矩阵B,也就是特征中心化)
2,计算协方差矩阵C(两两特征之间的协方差,构成一个矩阵)
3,计算协方差矩阵C的特征值和特征向量(为了求出最大的方差方向,也就是特征向量)
4,将特征值按照大到小排序,保留前面topN个特征向量V(如累计方差贡献值超过90%)
5,将原始数据转换到上述N个特征向量构建的新空间中,B*V
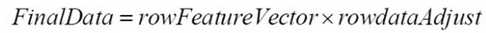
如果要恢复回原来的矩阵A,利用以下公式(精度有一些损失是正常的):
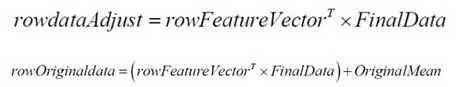
下面演示python中利用numpy来实现pac的案例:

下面是redEigVects输出的样子:

那么显然TOPN=3的主成份分别为:
PCA1 = 0.36*x1-0.08*x2+0.85*x3+0.35*x4
PCA2 = -0.65*x1-0.72*x2+0.17*x3+0.07*x3+0.07*x4
PCA3=-0.58*x1+0.59*x2+0.07*x3+0.54*x4
以上是关于常见机器学习算法原理+实践系列3(PCA)的主要内容,如果未能解决你的问题,请参考以下文章
常见机器学习算法原理+实践系列5(KNN分类+Keans聚类)