如何自己编译生成Eclipse插件,如hadoop-eclipse-plugin-2.2.0.jar
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何自己编译生成Eclipse插件,如hadoop-eclipse-plugin-2.2.0.jar相关的知识,希望对你有一定的参考价值。
如何自己编译生成Eclipse插件,如hadoop-eclipse-plugin-2.2.0.jar
http://cxshun.iteye.com/blog/1876366
大数据是当今的一个热门话题,相信搞JAVA的我们当然不能错过了,尤其是hadoop这个大数据时代的宠儿是属于我们JAVA界的(核心是用JAVA写的)。
看到hadoop,相信一堆概念大家都听得不少了,什么MapReduce,这个就大概解释下:
Map:俗点说就是直接把数据打散,一份数据把它切分成多份小的数据进行处理,这个过程可以称之为Map。
Reduce:有打散当然要有聚合,把处理完的数据再重新合成一个,这个过程称之为Reduce。
这两个操作实际上就是hadoop的核心。
hadoop可以不用eclipse插件也可以运行,但当然,对于我们初学的,有个插件肯定好很多,我们可以集中精力先让它跑起来,然后再慢慢去深入研究。
hadoop貌似在0.20.0之后就不再提供eclipse插件的编译包了,而是直接提供一堆源码,具体原因就不清楚是啥了。但可能是考虑到eclipse版本的问题吧,各个开发者的偏好不一样,用的版本都不一样,与其自己编译不如给开发者,这样会更好。
但给了一堆源码给我们,对我们这些不怎么熟ant的人就是个难题了。我就在编译的时候遇到了一堆问题了,杯具得很。但好在GOOGLE大神在,在很多博客文章的帮助下,总算解决了那些问题(在这里感谢那些文章的作者,恕我不能一一列举)。
Hadoop2.x之后,已经发布了稳定的版本hadoop2.2.0.但是由于没有eclipse插件工具,辅助,开发调试相对起来,会稍显麻烦,特别是基于Java开发的工程师们,虽然写完MR任务后,也可以采用打成jar包的方式,上传调试,但是这种方式,也有点繁琐,不过网上也好像有一些,使用程序能够自动打包任务的程序,散仙没具体用过,在这里,就不多涉及了,有知道的朋友们,欢迎分享。
下面开始进入正题,散仙来详细介绍下,怎么编译hadoop2.x的eclipse插件,在这里首先,你得具备如下几个条件,Ant工具,hadoop2.2.0的压缩包,eclipse插件的压缩包(散仙在后面已经上传),散仙建议最好在Linux平台下进行编译,Windows可能效果不是太好,出一点小的问题都有可能导致编译失败。
废话不多说了,直接来看看步骤:
(以上步骤都假设你有hadoop代码,下载的包里面有带源码的,如果还没下载的,可以到这里下载,http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/,注意不要下载bin的那个,那个不带源代码。我这里用到的hadoop版本是2.2.0。
好不容易找到了Hadoop2.2.x的源码,自己编译了一下 引用原文:
https://github.com/winghc/hadoop2x-eclipse-plugin#how-to-build
我的环境:
1.git(下载需要,当然也可以下载压缩包,下载压缩包就不需要git了)
2.ant,并配置了环境变量(编译需要)
3.jdk1.7_51
4.centOS_6.5_32
5.当前目录/opt
6.eclipse主目录:/opt/eclipse,版本是 Kepler(插件最新支持到这个版本)ant编译时需要这个参数
7.hadoop主目录:/cluster/hadoop-2.2.0,ant编译时需要这个参数
第一步 从github将代码检出来
#也可以直接下载压缩包,然后解压
#压缩包的地址:https://github.com/winghc/hadoop2x-eclipse-plugin/archive/master.zip
git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git第二步 编译eclipse插件
#经过第一步后,在/opt目录下会有hadoop2x-eclipse-plugin文件夹
cd hadoop2x-eclipse-plugin/src/contrib/eclipse-pluginant jar-Dversion=2.2.0-Declipse.home=/opt/eclipse -Dhadoop.home=/cluster/hadoop-2.2.0
#说明:ant编译过程中有一步会卡住一段时间,没有任何输出,但是别慌,那是在从网上下载依赖包,大概20几兆,但是下载速度有点慢,需要耐心等待(看人品,运气不好的话要2个小时左右,运气好30分钟左右)
第三步 安装eclipse插件
#经过第二步后,会产生插件的jar包,在目录:/opt/hadoop2x-eclipse-plugin/build/contrib/eclipse-plugin
cd/opt/hadoop2x-eclipse-plugin/build/contrib/eclipse-plugin
#将jar包拷贝到eclipe的plugins目录下cp hadoop-eclipse-plugin-2.2.0.jar /opt/eclipse/plugins
第四步 启动Eclipse(需带参数启动),写个shell脚本
vi /opt/eclipse/EclipseWithHadoop
#录入以下内容
#!/bin/bash
/opt/eclipse/eclipse -clean -consolelog -debug#保存退出
#赋予执行权限
chmod111EclipseWithHadoop
#链接到桌面
ln /opt/eclipse/EclipseWithHadoop /root/desktop/Eclipse第五步 启动Eclipse
在桌面双击Eclipse,启动Eclipse
具体如何使用这个插件,这里就不描述了,就我使用的情况来看,这个插件还有待完善,会出一些错误,但是不影响使用,可以像开发普通的java 项目一样开发hadoop mapreduce项目,开发,调试运行的步骤和普通java project一样
运行的时候直接,run as java application
调试的时候直接,debug as java application(当然要设置断点)
版本二:
具体的步骤如下:
|
序号 |
描述 |
|
1 |
确保你的ant已经安装完成,并输入ant -version测试可以正常工作 |
|
2 |
进入到eclipse插件包的eclipse-plugin的根目录下,散仙的路径是/root/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin |
|
3 |
执行命令ant jar -Dversion=2.2.0 -Declipse.home=/root/eclipse -Dhadoop.home=/root/hadoop-2.2.0。注意这两个路径,分别是eclipse的根路径,和hadoop2.2.0的根路径 |
|
4 |
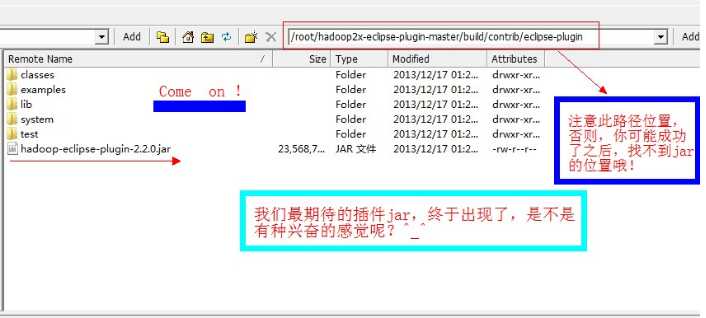
最终的生成jar的路径在,/root/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin目录下 |
|
5 |
OK,至此已经成功完成,把此插件拷贝eclipse的插件目录下,重新启动eclipse即可。 |
下面附上几张过程截图:
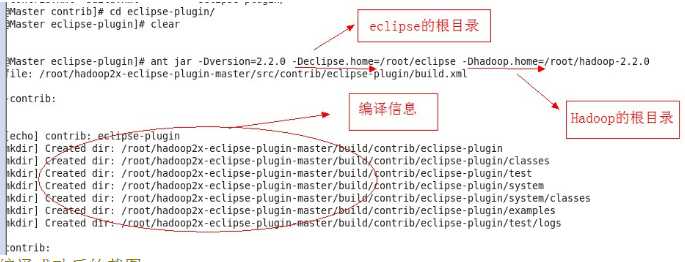
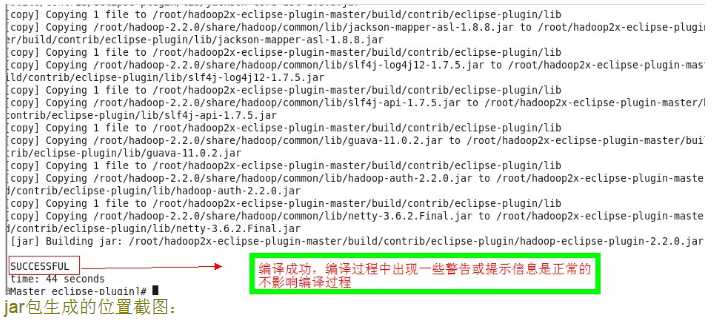
编译成功后的截图:
jar包生成的位置截图:
至此,我们的生成插件的过程,就讲解完毕了,其实搞起来是非常简单的,这个相比1.x的eclipse插件的编译过程,要简单很多了。
以上是关于如何自己编译生成Eclipse插件,如hadoop-eclipse-plugin-2.2.0.jar的主要内容,如果未能解决你的问题,请参考以下文章