Amazon关键词抓取
Posted TTyb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Amazon关键词抓取相关的知识,希望对你有一定的参考价值。
亚马逊的网址构造很简单,几乎算是静态的网页,花费3小时完美收工,不要在意细节!
在python3下利用xpath就可以完美解决
xpath的使用方法请见:
python之lxml(xpath)
入口图界面为:

抓取操作为:

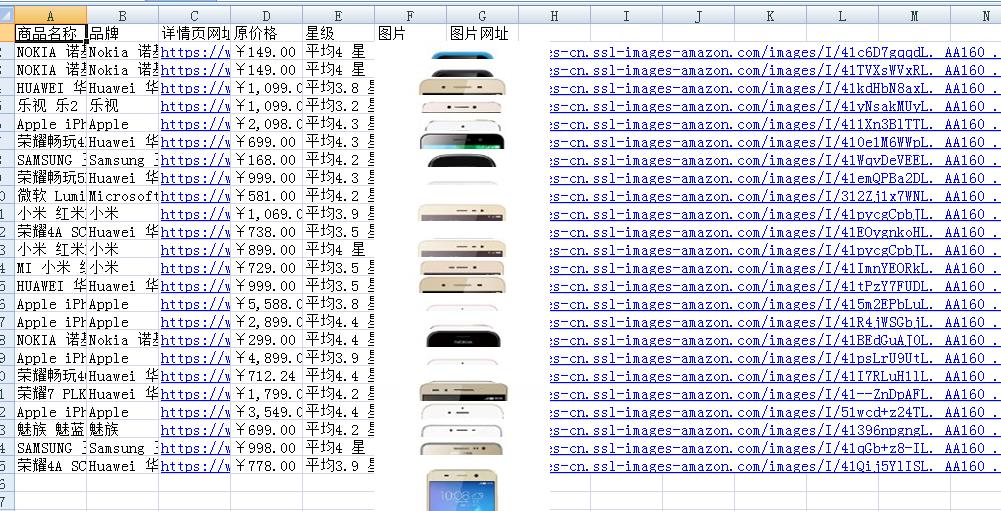
抓取的效果图如下:
图片:

excel:
1 \'\'\' 2 .======. 3 | INRI | 4 | | 5 | | 6 .========\' \'========. 7 | _ xxxx _ | 8 | /_;-.__ / _\\ _.-;_\\ | 9 | `-._`\'`_/\'`.-\' | 10 \'========.`\\ /`========\' 11 | | / | 12 |/-.( | 13 |\\_._\\ | 14 | \\ \\`;| 15 | > |/| 16 | / // | 17 | |// | 18 | \\(\\ | 19 | `` | 20 | | 21 | | 22 | | 23 | | 24 .======. 25 …………………………………………………………………………………… 26 27 !!!!! 28 \\\\ - - // 29 (-● ●-) 30 \\ (_) / 31 \\ u / 32 ┏oOOo-━━━━━━━━┓ 33 ┃ ┃ 34 ┃ 耶稣保佑! ┃ 35 ┃ 永无BUG!!!┃ 36 ┃ ┃ 37 ┗━━━━━━━━-oOOo┛ 38 39 …………………………………………………………………………………… 40 41 _oo0oo_ 42 088888880 43 88" . "88 44 (| -_- |) 45 0\\ = /0 46 ___/\'---\'\\___ 47 .\' \\\\\\\\| |// \'. 48 / \\\\\\\\||| : |||// \\\\ 49 /_ ||||| -:- |||||- \\\\ 50 | | \\\\\\\\\\\\ - /// | | 51 | \\_| \'\'\\---/\'\' |_/ | 52 \\ .-\\__ \'-\' __/-. / 53 ___\'. .\' /--.--\\ \'. .\'___ 54 ."" \'< \'.___\\_<|>_/___.\' >\' "". 55 | | : \'- \\\'.;\'\\ _ /\';.\'/ - \' : | | 56 \\ \\ \'_. \\_ __\\ /__ _/ .-\' / / 57 =====\'-.____\'.___ \\_____/___.-\'____.-\'===== 58 \'=---=\' 59 60 61 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 62 佛祖保佑 永无BUG 63 64 65 66 67 ┌─┐ ┌─┐ 68 ┌──┘ ┴───────┘ ┴──┐ 69 │ │ 70 │ ─── │ 71 │ ─┬┘ └┬─ │ 72 │ │ 73 │ ─┴─ │ 74 │ │ 75 └───┐ ┌───┘ 76 │ │ 77 │ │ 78 │ │ 79 │ └──────────────┐ 80 │ │ 81 │ ├─┐ 82 │ ┌─┘ 83 │ │ 84 └─┐ ┐ ┌───────┬──┐ ┌──┘ 85 │ ─┤ ─┤ │ ─┤ ─┤ 86 └──┴──┘ └──┴──┘ 87 神兽保佑 88 代码无BUG! 89 \'\'\' 90 # !/usr/bin/python3.4 91 # -*- coding: utf-8 -*- 92 93 # 前排烧香 94 # 永无BUG 95 96 import requests 97 import time 98 import random 99 import xlsxwriter 100 from lxml import etree 101 import urllib.parse 102 import urllib.request 103 104 def geturl(url): 105 # 制作头部 106 header = { 107 \'User-Agent\': \'Mozilla/5.0 (iPad; U; CPU OS 4_3_4 like Mac OS X; ja-jp) AppleWebKit/533.17.9 (Khtml, like Gecko) Version/5.0.2 Mobile/8K2 Safari/6533.18.5\', 108 \'Referer\': \'https://www.amazon.cn/\', 109 \'Host\': \'www.amazon.cn\', 110 \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\', 111 \'Accept-Encoding\': \'gzip, deflate, br\', 112 \'Accept-Language\': \'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3\', 113 \'Connection\': \'keep-alive\' 114 } 115 # get参数 116 res = requests.get(url=url, headers=header) 117 # (\'UTF-8\')(\'unicode_escape\')(\'gbk\',\'ignore\') 118 resdata = res.content 119 return resdata 120 121 def getimg(url): 122 # 制作头部 123 header = { 124 \'User-Agent\': \'Mozilla/5.0 (iPad; U; CPU OS 4_3_4 like Mac OS X; ja-jp) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8K2 Safari/6533.18.5\', 125 \'Referer\': \'https://www.amazon.cn/\', 126 \'Host\': \'www.amazon.cn\', 127 \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\', 128 \'Accept-Encoding\': \'gzip, deflate, br\', 129 \'Accept-Language\': \'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3\', 130 \'Connection\': \'keep-alive\' 131 } 132 # get参数 133 res = requests.get(url=url, headers=header,stream=True) 134 # (\'UTF-8\')(\'unicode_escape\')(\'gbk\',\'ignore\') 135 resdata = res.iter_content(chunk_size=1024) 136 for chunk in resdata: 137 if chunk: 138 return chunk 139 140 def begin(): 141 taoyanbai = \'\'\' 142 ----------------------------------------- 143 | 欢迎使用亚马逊爬取系统 | 144 | 时间:2016年9月20日 | 145 | 出品:TTyb | 146 | 微信/QQ:420439007 | 147 ----------------------------------------- 148 \'\'\' 149 print(taoyanbai) 150 151 152 def timetochina(longtime, formats=\'{}天{}小时{}分钟{}秒\'): 153 day = 0 154 hour = 0 155 minutue = 0 156 second = 0 157 try: 158 if longtime > 60: 159 second = longtime % 60 160 minutue = longtime // 60 161 else: 162 second = longtime 163 if minutue > 60: 164 hour = minutue // 60 165 minutue = minutue % 60 166 if hour > 24: 167 day = hour // 24 168 hour = hour % 24 169 return formats.format(day, hour, minutue, second) 170 except: 171 raise Exception(\'时间非法\') 172 173 174 if __name__ == \'__main__\': 175 176 begin() 177 178 keyword = input("请输入关键词:") 179 try: 180 sort = int(input("相关度排序请按0,人气排序请按1,上架时间排序请按2,价格低到高排序请按3,价格高到低请按4,用户评分排序请按5(默认相关度排序):")) 181 if sort > 5 or sort <= 0: 182 sort = "" 183 elif sort == 1: 184 sort = "popularity-rank" 185 elif sort == 2: 186 sort = "date-desc-rank" 187 elif sort == 3: 188 sort = "price-asc-rank" 189 elif sort == 4: 190 sort = "price-desc-rank" 191 elif sort == 5: 192 sort = "review-rank" 193 except: 194 sort = "" 195 try: 196 pages = int(input("请输入抓取页数(默认5页):")) 197 except: 198 pages = 5 199 200 a = time.clock() 201 202 # 转成字符串 203 # %y 两位数的年份表示(00 - 99) 204 # %Y 四位数的年份表示(000 - 9999) 205 # %m 月份(01 - 12) 206 # %d 月内中的一天(0 - 31) 207 # %H 24小时制小时数(0 - 23) 208 # %I 12小时制小时数(01 - 12) 209 # %M 分钟数(00 = 59) 210 # %S 秒(00 - 59) 211 today = time.strftime(\'%Y%m%d%H%M\', time.localtime()) 212 # 创建一个Excel文件 213 workbook = xlsxwriter.Workbook(\'../excel/\' + today + \'.xlsx\') 214 # 创建一个工作表 215 worksheet = workbook.add_worksheet() 216 217 # 第一行参数 218 first = [\'商品名称\', \'品牌\', \'详情页网址\', \'原价格\', \'星级\', \'图片\',\'图片网址\'] 219 220 # 写入excel计数行 221 count = 1 222 223 # 下载图片计数 224 num = 0 225 226 # 构造时间戳 227 nowtime = int(time.time()) 228 229 for page in range(0,pages): 230 231 urldata = { 232 \'page\':page, 233 \'sort\':sort, 234 \'keywords\':keyword, 235 \'ie\':\'UTF-8\', 236 \'qid\':str(nowtime) 237 } 238 urldata = urllib.parse.urlencode(urldata) 239 url = "https://www.amazon.cn/s/ref=nb_sb_noss_1?__mk_zh_CN=亚马逊网站&" + urldata 240 241 html = geturl(url).decode(\'Utf-8\', \'ignore\') 242 #file = open("../data/html.txt","wb") 243 #file.write(html) 244 #file.close() 245 246 #file = open("../data/html.txt","rb") 247 #html = file.read().decode(\'Utf-8\', \'ignore\') 248 #print(html) 249 250 # xpath解析需要的东西 251 contents = etree.HTML(html) 252 253 # 找到商品名称 254 titles = contents.xpath(\'//a[@class="a-link-normal s-access-detail-page a-text-normal"]/@title\') 255 arr_title = [] 256 for title in titles: 257 arr_title.append(title) 258 259 # 找到品牌 260 brands = contents.xpath(\'//div[@class="a-row a-spacing-mini"][1]/div/span/text()\') 261 arr_brand = [] 262 for brand in brands: 263 if "更多购买选择" in brand: 264 pass 265 else: 266 arr_brand.append(brand) 267 268 # 找到详情页网址 269 detailurls = contents.xpath(\'//a[@class="a-link-normal s-access-detail-page a-text-normal"]/@href\') 270 arr_detailurl = [] 271 for detailurl in detailurls: 272 arr_detailurl.append(urllib.parse.unquote(detailurl)) 273 #print(detailurl) 274 #print(len(arr_detailurl)) 275 276 # 得到原价格 277 # 这里是忽略了新品价格、非新品价格 278 prices = contents.xpath(\'//div[@class="a-row a-spacing-none"][1]/a/span[1]/text()\') 279 arr_price = [] 280 for price in prices: 281 arr_price.append(price) 282 283 # 得到星级 284 grades = contents.xpath(\'//span[@class="a-icon-alt"]/text()\') 285 arr_grade = [] 286 for grade in grades: 287 if "平均" in grade: 288 arr_grade.append(grade) 289 #print(grade) 290 else: 291 pass 292 if arr_grade: 293 arr_grade.pop() 294 #print(len(arr_grades)) 295 296 # 得到图片 297 imgurls = contents.xpath(\'//a[@class="a-link-normal a-text-normal"]/img/@src\') 298 arr_img = [] 299 300 for imgurl in imgurls: 301 file = open("../jpg/" + str(num) + ".jpg","wb") 302 pic = urllib.request.urlopen(imgurl) 303 file.write(pic.read()) 304 file.close() 305 # 每一次下载都暂停1-3秒 306 imgtime = random.randint(1, 3) 307 print("下载图片暂停" + str(imgtime) + "秒") 308 time.sleep(imgtime) 309 arr_img.append(imgurl) 310 num = num + 1 311 #print(imgurl) 312 #print(len(arr_img)) 313 314 # 写入excel 315 # 写入第一行 316 for i in range(0, len(first)): 317 worksheet.write(0, i, first[i]) 318 319 # 写入其他数据 320 for j in range(0,len(arr_title)): 321 worksheet.write(count,0,arr_title[j]) 322 worksheet.write(count, 1, arr_brand[j]) 323 worksheet.write(count, 2, arr_detailurl[j]) 324 try: 325 worksheet.write(count, 3, arr_price[j]) 326 except Exception as err: 327 print(err) 328 worksheet.write(count, 3, "") 329 worksheet.write(count, 4, arr_grade[j]) 330 worksheet.insert_image(count, 5, "../jpg/" + str(count - 1) + ".jpg") 331 worksheet.write(count, 6, arr_img[j]) 332 count = count + 1 333 334 # 每一次下载都暂停5-10秒 335 loadtime = random.randint(5, 10) 336 print("抓取网页暂停" + str(loadtime) + "秒") 337 time.sleep(loadtime) 338 339 workbook.close() 340 b = time.clock() 341 print(\'运行时间:\' + timetochina(b - a)) 342 input(\'请关闭窗口\')
以上是关于Amazon关键词抓取的主要内容,如果未能解决你的问题,请参考以下文章