windows中根据进程PID查找进程对象过程深入分析
Posted 太初有道,道与神同在,道就是神……
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了windows中根据进程PID查找进程对象过程深入分析相关的知识,希望对你有一定的参考价值。
这里windows和Linxu系列的PID 管理方式有所不同,windows中进程的PID和句柄没有本质区别,根据句柄索引对象和根据PID或者TID查找进程或者线程的步骤也是一样的。
句柄是针对进程而言,也就是句柄一定所属于某个进程,为某个进程私有的资源。句柄的分配来自于进程私有的句柄表。而进程PID和线程TID和句柄的分配原理是一样的,但是来源就不同了。进程PID来源于系统中一张全局的句柄表PSpcidtable。从级别上来说Pspcidtable和进程对象eprcess中的objecttable是一样的,都是HANDLE_TABLE类型,只是两者指向的句柄表不同。还有一个区别就是进程内的句柄表项中所指的对象是对象头,要找到对象体还需要加偏移,而pspcidtable中的句柄项直接指向对象体。
换句话说,系统分配句柄和进程或者线程ID的源头都是源自于句柄表。细心的人可能会发现进程ID其实都是4的倍数。这里的原因在之前的文章中已经分析过,这里不再赘述,今天主要结合WRK源代码分析下句柄表的工作模式以及通过句柄或者进程PID来查找相应对象的过程。
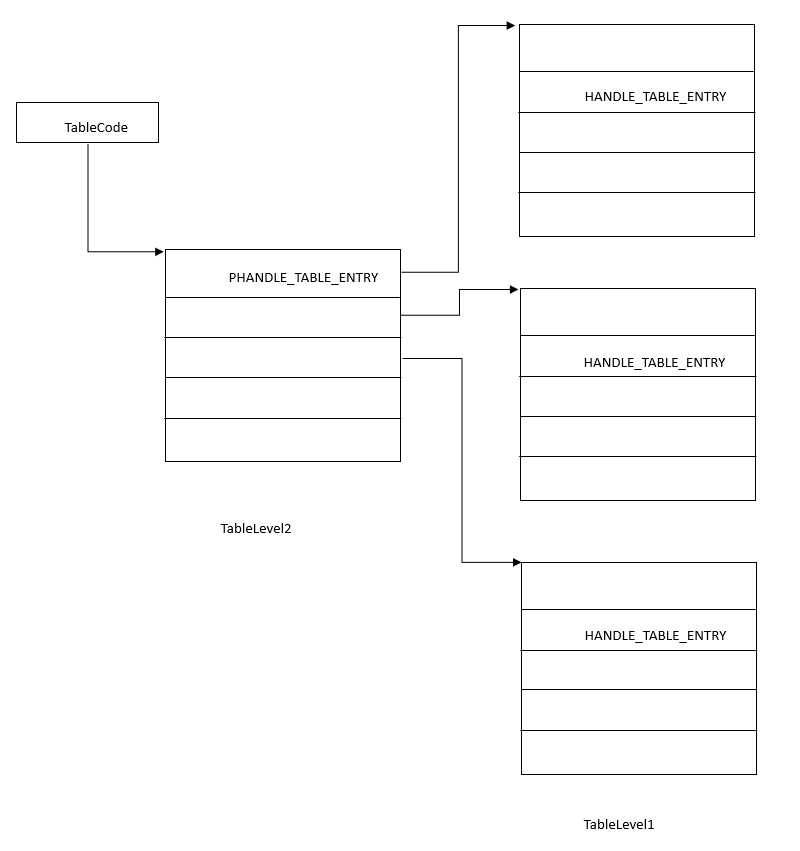
句柄表有三种:
- 单层句柄表
- 两层句柄表
- 三层句柄表
初始状态下,在进程创建之初,只有单层句柄表,随着进程打开文件数的增加,句柄表慢慢扩张,待单张句柄表无法容纳进程拥有的句柄数的时候,系统就扩张句柄表为两层句柄表,句柄表的单位就是一个页面即4KB,句柄表项都是_HANDLE_TABLE_ENTRY类型,每一个占用8个字节,所以一个页面可以存放2^12/2^3=512个句柄项,今天我们主要以两层句柄表为例说明问题。两层句柄表的架构如下:
在两层句柄表下,需要有一个页面在存放句柄表页面的地址,这点类似于系统中的页表基址,不过这里要简单的多。TableLevel2表示具体句柄表的索引表,其中的每一项都指向一张具体的表。所以这里可以存放4096/4=1024项,所以二级句柄表供可以存放1024*512个句柄。
前面又所说过,句柄索引是以4递增的,那么每个句柄表的“长度”即从数字的层面上来看为512*4,而这里每个句柄或者PID都可以认为是给定的长度。那么要判断这个长度的终点落在那个句柄表并找到对应的句柄值就需要做一下工作:
1、找到句柄表在TableLevel2中的索引。
2、找到句柄项在句柄表中的偏移。
要确定终点落在哪一个句柄表中,判断索引值包含几个句柄表的长度即可,对句柄表的长度取整。假设句柄表的长度是 length = 512 * 4 ,对应到TableLevel2上就是length对应sizeof(PHANDLE_VALUE_INC)即4个字节。从全局的角度来看实际上是在TableLevel2层每个字节对应i = length/sizeof(PHANDLE_VALUE_INC),用索引值index/i即为索引值在level2中对应的字节。
要确定句柄值具体在某一张句柄表中的偏移就比较容易了,让index % length即可。
有了上面的介绍,下面我们看下windows中是如何根据PID查找到具体的进程对象的呢?
我们从PsLookupProcessByProcessId函数入手,这是内核中的一个导出函数,可以根据进程ID找到具体的EProcess对象
NTSTATUS PsLookupProcessByProcessId( __in HANDLE ProcessId, __deref_out PEPROCESS *Process ) /*++ Routine Description: This function accepts the process id of a process and returns a referenced pointer to the process. Arguments: ProcessId - Specifies the Process ID of the process. Process - Returns a referenced pointer to the process specified by the process id. Return Value: STATUS_SUCCESS - A process was located based on the contents of the process id. STATUS_INVALID_PARAMETER - The process was not found. --*/ { PHANDLE_TABLE_ENTRY CidEntry; PEPROCESS lProcess; PETHREAD CurrentThread; NTSTATUS Status; PAGED_CODE(); Status = STATUS_INVALID_PARAMETER; CurrentThread = PsGetCurrentThread (); KeEnterCriticalRegionThread (&CurrentThread->Tcb); CidEntry = ExMapHandleToPointer(PspCidTable, ProcessId); if (CidEntry != NULL) { lProcess = (PEPROCESS)CidEntry->Object; if (lProcess->Pcb.Header.Type == ProcessObject && lProcess->GrantedAccess != 0) { if (ObReferenceObjectSafe(lProcess)) { *Process = lProcess; Status = STATUS_SUCCESS; } } ExUnlockHandleTableEntry(PspCidTable, CidEntry); } KeLeaveCriticalRegionThread (&CurrentThread->Tcb); return Status; } //此函数中最关键的一步是根据ExMapHandleToPointer函数获取到了进程PID对应的HANDLE_TABLE_ENTRY结构,进入此函数看下: NTKERNELAPI PHANDLE_TABLE_ENTRY ExMapHandleToPointer ( __in PHANDLE_TABLE HandleTable, __in HANDLE Handle ) /*++ Routine Description: This function maps a handle to a pointer to a handle table entry. If the map operation is successful then the handle table entry is locked when we return. Arguments: HandleTable - Supplies a pointer to a handle table. Handle - Supplies the handle to be mapped to a handle entry. Return Value: If the handle was successfully mapped to a pointer to a handle entry, then the address of the handle table entry is returned as the function value with the entry locked. Otherwise, a value of NULL is returned. --*/ { EXHANDLE LocalHandle; PHANDLE_TABLE_ENTRY HandleTableEntry; PAGED_CODE(); LocalHandle.GenericHandleOverlay = Handle; if ((LocalHandle.Index & (LOWLEVEL_COUNT - 1)) == 0) { return NULL; } // // Translate the input handle to a handle table entry and make // sure it is a valid handle. // HandleTableEntry = ExpLookupHandleTableEntry( HandleTable, LocalHandle ); if ((HandleTableEntry == NULL) || !ExpLockHandleTableEntry( HandleTable, HandleTableEntry)) { // // If we are debugging handle operations then save away the details // if (HandleTable->DebugInfo != NULL) { ExpUpdateDebugInfo(HandleTable, PsGetCurrentThread (), Handle, HANDLE_TRACE_DB_BADREF); } return NULL; } // // Return the locked valid handle table entry // return HandleTableEntry; }
此函数做一些简单变量的初始化后,就调用了ExpLookupHandleTableEntry函数,参数是进程对应的句柄表结构HandleTable和PID对应的handle
PHANDLE_TABLE_ENTRY ExpLookupHandleTableEntry ( IN PHANDLE_TABLE HandleTable, IN EXHANDLE tHandle ) /*++ Routine Description: This routine looks up and returns the table entry for the specified handle value. Arguments: HandleTable - Supplies the handle table being queried tHandle - Supplies the handle value being queried Return Value: Returns a pointer to the corresponding table entry for the input handle. Or NULL if the handle value is invalid (i.e., too large for the tables current allocation. --*/ { ULONG_PTR i,j,k; ULONG_PTR CapturedTable; ULONG TableLevel; PHANDLE_TABLE_ENTRY Entry = NULL; EXHANDLE Handle; PUCHAR TableLevel1; PUCHAR TableLevel2; PUCHAR TableLevel3; ULONG_PTR MaxHandle; PAGED_CODE(); // // Extract the handle index // Handle = tHandle; Handle.TagBits = 0; MaxHandle = *(volatile ULONG *) &HandleTable->NextHandleNeedingPool;//取下一页的起始索引,在一层句柄表的情况下,这里作为最大索引限制 // // See if this can be a valid handle given the table levels. // if (Handle.Value >= MaxHandle) { return NULL; } // // Now fetch the table address and level bits. We must preserve the // ordering here. // CapturedTable = *(volatile ULONG_PTR *) &HandleTable->TableCode;//获取句柄表的最高层页面的地址。 // // we need to capture the current table. This routine is lock free // so another thread may change the table at HandleTable->TableCode // TableLevel = (ULONG)(CapturedTable & LEVEL_CODE_MASK);//取句柄表级数 CapturedTable = CapturedTable - TableLevel;//这里是为何???? // // The lookup code depends on number of levels we have // switch (TableLevel) { case 0: // // We have a simple index into the array, for a single level // handle table // TableLevel1 = (PUCHAR) CapturedTable; // // The index for this level is already scaled by a factor of 4. Take advantage of this // //注意这里tablelevel1已经不是PHANDLE_TABLE_ENTRY类型而是puchar类型,即相当于一个uchar类型的指针,那么把tablelevel1作为数组地址取值,一个元素就占用一个字节 //因为PID 本身是作为4增长,而一个表项是占用8字节,所以只需要让PID *2即可 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[Handle.Value * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; case 1: // // we have a 2 level handle table. We need to get the upper index // and lower index into the array // TableLevel2 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC);//这里取i为实际的PID 在某个句柄表中的偏移 Handle.Value -= i;//然后用值减去这个偏移,得到的应该是整数个句柄表的最后一位PID j = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY));//用value除以一个句柄表容纳的 TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; case 2: // // We have here a three level handle table. // TableLevel3 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC); Handle.Value -= i; k = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY)); j = k % (MIDLEVEL_COUNT * sizeof (PHANDLE_TABLE_ENTRY)); k -= j; k /= MIDLEVEL_COUNT; TableLevel2 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel3[k]; TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j]; Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break; default : _assume (0); } return Entry; }
这里MaxHandle = *(volatile ULONG *) &HandleTable->NextHandleNeedingPool;是取当前进程句柄表中的下次扩展时候用到的首个句柄索引,也就是现有的句柄索引肯定都要小于此值,那么根据这个来判断句柄值是否合法。
然后 CapturedTable = *(volatile ULONG_PTR *) &HandleTable->TableCode获取最高层索引表的地址。前面也提到了句柄表有单层,双层,三层。
TableLevel = (ULONG)(CapturedTable & LEVEL_CODE_MASK);就是取TableCode最后两位,即句柄表的级数
CapturedTable = CapturedTable - TableLevel;这里目的尚不明确!!
然后就开始了一个switch选择,就是根据具体的层数来做具体的工作。单层情况下很简单,直接取数组的相应表项即可。这里我们重点分析下case 1的情况即两层句柄表的情况。
TableLevel2 = (PUCHAR) CapturedTable; i = Handle.Value % (LOWLEVEL_COUNT * HANDLE_VALUE_INC);//这里取i为实际的PID 在某个句柄表中的偏移 Handle.Value -= i;//然后用值减去这个偏移,得到的应该是整数个句柄表的最后一位PID j = Handle.Value / ((LOWLEVEL_COUNT * HANDLE_VALUE_INC) / sizeof (PHANDLE_TABLE_ENTRY));//用value除以一个句柄表容纳的 TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址 Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)]; break;
这里TableLevel2就指向句柄索引表且是PUCHAR类型,这种类型有一个好处就是按单字节增长。
i就是取得PID值终点所在的句柄表中的偏移。
下面让Handle.value-i就是去掉偏移后,那么剩下的应该就是整数个句柄表的长度即n*512*4
然后根据前面我们的分析,j就是hanle.value在TableLevel2中对应的字节数。
TableLevel1 = (PUCHAR) *(PHANDLE_TABLE_ENTRY *) &TableLevel2[j];//这里就取二级句柄表的地址
由于数组从0开始,那么TableLevel2[j]表示整数个句柄表的下一个句柄表对应的地址起始处,为什么这么说呢?因为TableLevel2是Puchar类型,TableLevel2[j]只能取一个字节,所以这里做了&操作取出地址,然后转化成
PHANDLE_TABLE_ENTRY *,之后再取值就可以取出句柄表的地址,然后再次转化成PUCHAR.
到此已经找到了句柄索引对应的句柄表的起始地址,下面就该按照偏移找到具体的句柄表项了。
Entry = (PHANDLE_TABLE_ENTRY) &TableLevel1[i * (sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)];
现在TableLevel1已经指向了具体的句柄表,一个HANDLE_TABLE_ENTRY 8个字节,而句柄值是按照4递增,也即是平均来看,句柄索引距离1对应sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC)=2字节
那么i自然就对应于i*sizeof (HANDLE_TABLE_ENTRY) / HANDLE_VALUE_INC),注意这里并不是从0开始的,因为对底层句柄表的索引0有其他的用途,所以这里我们也不用-1.找到HANDLE_TABLE_ENTRY的起始地址后,转化成PHANDLE_TABLE_ENTRY即可。。
这样就找到了HANDLE_TABLE_ENTRY,然后HANDLE_TABLE_ENTRY的第一项就是一个指向对应对象的指针,直接取出即找到对应的对象。
lProcess = (PEPROCESS)CidEntry->Object;
注意:
这里entry->object是直接取到了对象体,但是在普通的句柄情况下,这里只能取到对象头,最后根据相应的偏移取到对象体,关于对象参考另一篇文章!还有前面红色字体那个地方,笔者的确不晓得什么意思,知道的老师们还请多多指点!
三层句柄表和两层原理类似,只是多了一此索引,这里就不重复分析。只是这里开发者的想法的确是难懂,笔者描述的也不知道是否清楚,但是我实在是不能想到更好的办法去描述!!
以上是关于windows中根据进程PID查找进程对象过程深入分析的主要内容,如果未能解决你的问题,请参考以下文章