RDD的容错机制
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RDD的容错机制相关的知识,希望对你有一定的参考价值。
RDD的容错机制
RDD实现了基于Lineage的容错机制。RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage。在部分计算结果丢失时,只需要根据这个Lineage重算即可。
图1中,假如RDD2所在的计算作业先计算的话,那么计算完成后RDD1的结果就会被缓存起来。缓存起来的结果会被后续的计算使用。图中的示意是说RDD1的Partition2缓存丢失。如果现在计算RDD3所在的作业,那么它所依赖的Partition0、1、3和4的缓存都是可以使用的,无须再次计算。但是Partition2由于缓存丢失,需要从头开始计算,Spark会从RDD0的Partition2开始,重新开始计算。
内部实现上,DAG被Spark划分为不同的Stage,Stage之间的依赖关系可以认为就是Lineage。关于DAG的划分可以参阅第4章。
提到Lineage的容错机制,不得不提Tachyon。Tachyon包含两个维度的容错,一个是Tachyon集群的元数据的容错,它采用了类似于HDFS的Name Node的元数据容错机制,即将元数据保存到一个Image文件,并且保存了元数据变化的编辑日志(EditLog)。另外一个是Tachyon保存的数据的容错机制,这个机制类似于RDD的Lineage,Tachyon会保留生成文件数据的Lineage,在数据丢失时会通过这个Lineage来恢复数据。如果是Spark的数据,那么在数据丢失时Tachyon会启动Spark的Job来重算这部分内容。如果是Hadoop产生的数据,那么重新启动相应的Map Reduce Job就可以。现在Tachyon的容错机制的实现还处于开发阶段,并不推荐将这个机制应用于生产环境。不过,这并不影响Spark使用Tachyon。如果Spark保存到Tachyon的部分数据丢失,那么Spark会根据自有的容错机制来重算这部分数据。
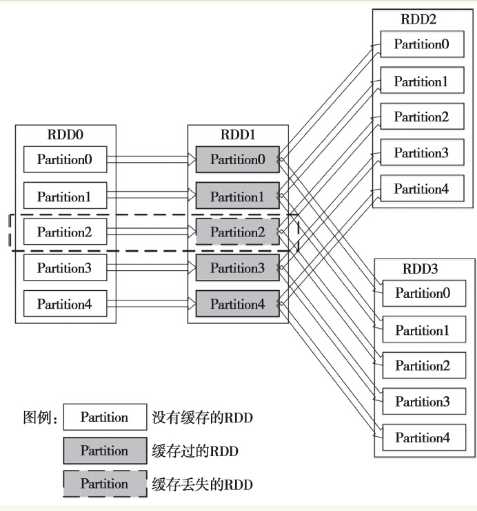
图1 RDD的部分缓存丢失的逻辑图
以上是关于RDD的容错机制的主要内容,如果未能解决你的问题,请参考以下文章
大数据框架对比:HadoopStormSamzaSpark和Flink--容错机制(ACK,RDD,基于log和状态快照),消息处理at least once,exactly once两个是关键