虚拟存储器——端到端地址翻译与多级页表
Posted 张飞online
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了虚拟存储器——端到端地址翻译与多级页表相关的知识,希望对你有一定的参考价值。
一、端到端地址翻译示例
上节我们刚把TLB开了个头,多说无益,还是具体来玩个实际例子吧,具体来做一个端到端(虚拟地址到物理地址)的地址翻译示例,来统筹下之前讲的知识点。先来做如下约定:
1、老规矩,存储器按字节寻址,访问也按一字节访问;
2、虚拟地址14位长(n=14),物理地址12位长(m=12),位数上点玩起来方便;
3、页面大小是64字节(P=64),也就是说(p=6)
4、TLB是四路组相联,总共16个条目;
5、L1 d-cache是物理寻址、直接映射的,行大小为4字节,总共有16个组。
这里得先贴出各个单元内的数据快照,以便分析,首先是TLB。
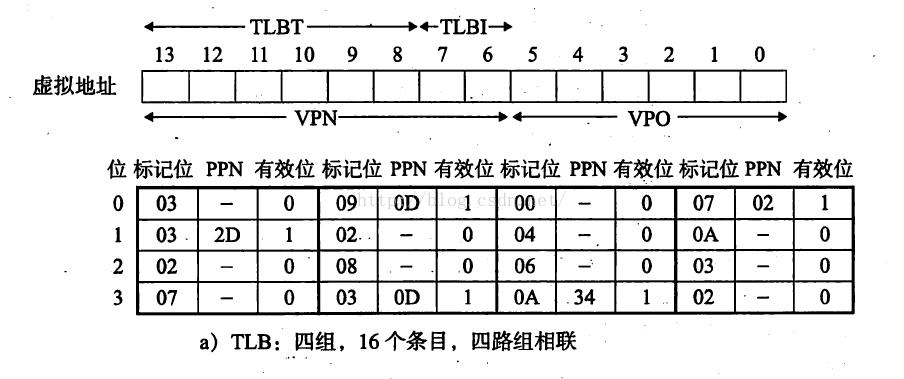
先看上面的图,要明确一点,引入TLB就是为了分级VPN的,而分解方式跟VPN的逻辑可能没有对应关系!由于页面大小64字节,p=6,因此VPO占用6位,既然是6位,再看虚拟地址是14位长,剩下VPN是8位,也就是说TLB需要处理2^8也就是256个VPN值。而TLB是四路组相联,从上到下0~3这四路,由VPN的低两位——TLBI来标识;而TLB的四组中每组有四个条目,要处理256个VPN,也就是说每组要对口处理64个VPN……注意到剩了6位给TLBT,他就是所谓的标记位,刚好能区分2^6=64个VPN,因此不管某个VPN被映射到哪一组,在同一组内是不会出现VPN重复歧义现象的,由TLBI确定组,再由TLBT确定标记位,于是8位VPN就这样通过6+2的方式被TLB分解和存储!
好,那假设现在CPU要读取虚拟地址0x03d4处的值会出现什么情况?我们先把0x03d4分解成VPN+VPO形式:
|
VPN(0x0F)
|
VPO(0x14)
|
实践发现,VPN和VPO的值与0x03d4已经完全没关系了,这是16进制表示法的弱点,虽然方便,但不如二进制来的直观。好了,接下来我们看看物理内存中页表的情况:
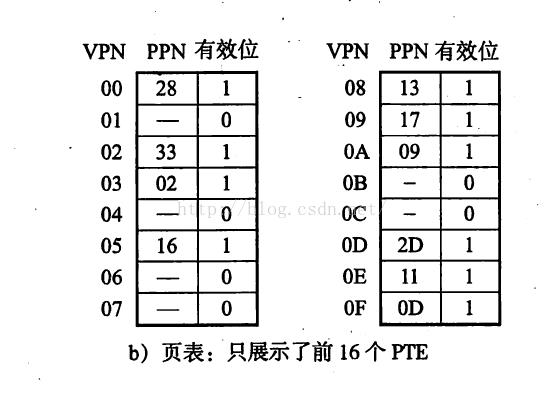
我们既然都知道物理地址是由PPN+PPO组成的,而PPO和VPO又是等价已知的,现在通过查看页表又晓得VPN的0x0F是对应的PPN是0D,那物理地址不已经出来了么等于0x0D14!如果你是CPU你这么做就傻X了,因为直接页表存储在物理内存中,直接访问内存会消耗大量的时间,MMU里明明有TLB缓存都不知道用么?好接下来看看VPN的0x0F是如何被TLB分解的:
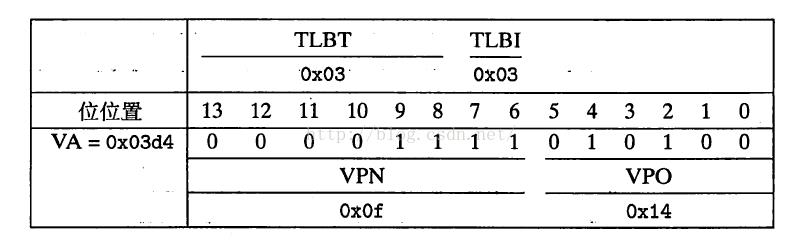
哇咔咔,还记得之前分析的TLBI两位和TLBT六位的结论么?忘了自己去看加粗字,现在用上了。两个量居然都是0x03,在看TLB的图,组索引TLBI的0x03刚好是第四排,而标记位TLBT的0x03刚好是该组第二个条目,并且其有效位是1,因此PPN顺利取出了0D!
如果TLB里没有怎么办?那就是TLB不命中,这时候才直接去物理内存中找PTE,就跟第一个想法一样的——奇慢!
好了,物理地址0x0D14到是获得了,你该不会想又跑到物理主存中去取值吧?别忘了这还有L1高速缓存呢:
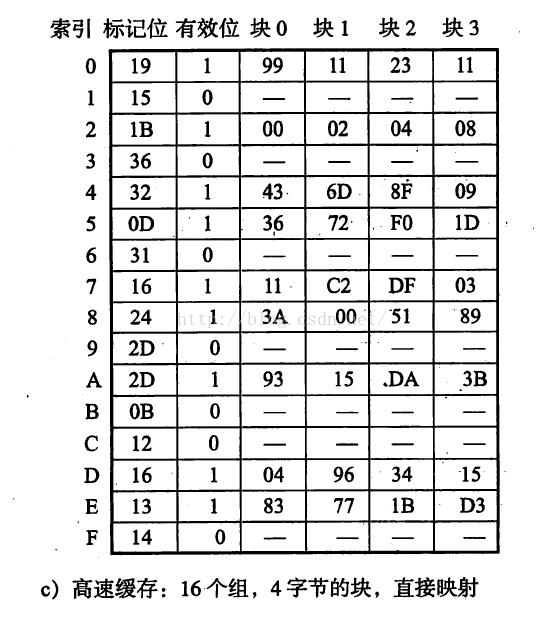
行大小为4字节,总共16个组,怎么看?当然还是得先从物理地址0x0D14开始看,别忘了,先按物理地址的格式来分解:
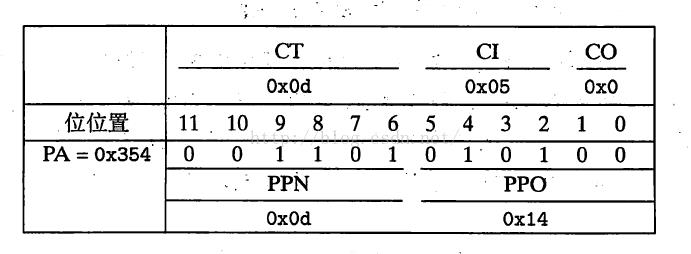
分解后发现,组索引CI的值是0x05,也就是L1缓存里索引5,这一行,其中标记位为0D,与物理地址中CT的值0x0D匹配;最后看偏移量OO是0x0,没有偏移,于是终于得到我们查询了半天的数值:0x36,于是MMU将其返回给CPU——注意,此例中完全没有物理内存的访问过程!
二、多级页表
在解释多级页表之前,先来梳理下概念,免得后面的内容看晕:
1、页表:缓存了很多页面信息(有效位+物理页号)的表;
2、各页面信息分别由页表中每个PTE记录,
3、页面:就是对应虚拟存储器(磁盘空间)中各空间
4、页号(PN):MMU根据虚拟页号VPN索引页表对应的具体PTE,从中提取出其中的物理页号PPN,一般都是数组直接对应关系
好了,既然概念解释清楚了,那么页表大小页面大小应该不会再搞混了吧:页面大小对应虚拟存储器每个分页大小,而PET的大小就是存储一条对应地址翻译信息所占用的空间大小,那么页表大小就是该页表内所有PTE大小的总和。
我们再来回忆下,一个32位系统,有2^32个地址,每个地址标识一个字节的数据,那么地址能访问到的数据就涵盖了2^32字节,也就是(2^2)*(2^10)*(2^10)*(2^10)B数据,也就是4GB数据。
如果我们每个页面的大小是4kB,那么4GB的数据就被分割成1M个页面(注意单位是”个“不是字节,说的页面个数呢!这里按2^10进阶),好,如果我们又知道每个PTE占是4字节大小,也就是说页表中处理每个页面都需要占用4B,处理1M个页面的页表自然就要在物理内存中占用4MB的空间……教材上确实没分析得这么明显,我如此讲解应该立马知道,4MB驻留空间是肿么得来了吧!天~4MB大小的页表,检索起来效率一定很低,如何才能把页表缩小呢?(注意不是在讨论页表里每一项页面所映射的4kB空间)
好了好了,忘掉刚才得出的4MB结论,因为现在有另一个假设也是4MB,那就是,如果我们把4GB总的虚拟存储器空间,分成一份份4MB大小,那就会分出1k份出来,也就是1024份空间。如果我们有一个专门的页表(I),其中刚好有1024个PTE,就刚好能标识这1024份空间。但是呢,总觉得这1024个4MB空间每个都太大了,难以精确定位,于是我们想到在单级页表中,原始页面大小本来就是4KB(就是一个页面能缓存的空间大小),也就是每份4MB空间可以被1024个单级原始页面映射,于是我们可以为每份空间都设立另一种专门的页表(II),其中也刚好有1024个PTE,就刚好标识那些映射4MB的1024个原始页面。而且既然(I)中每个PTE对应一份4MB空间,而每份空间又对应一个(II),那么(I)中每一个PTE就可以和某一个(II)建立联系,于是多级页表的概念产生了!
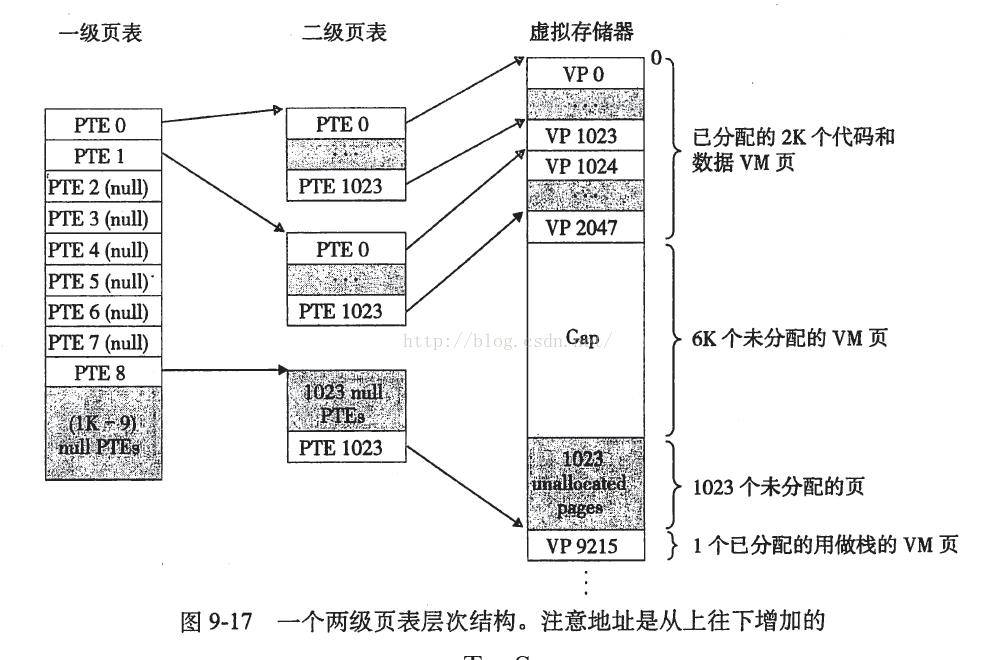
先不管最左边那些乱七八糟的虚存分配,先看从VP0~VP2047这2k个页(注意是页不是字节!),我们发现,每一个页VPx都被二级页表中的一个PTE所对应,而一个完整的二级表有1024个PTE分别对应1024个VP,而我们又知道一个VP页面是4KB大小(就是原始页面,我自创的描述词),1024个VP就是4MB大小,也就说每个二级页表都对应4MB大小的数据!好了,再看一级页表,它每个PTE对应的又是一个二级页表,也就是说,一级页表每个PTE都对应4MB大小的数据,那么总共1024个PTE的一级页表,刚好可以完整对应4GB大小的空间!
好了,为啥要整二级页表呢?最起码有三点好处。其一,如果一级页表的PTE为空,那就不存在二级页表,能节省大量潜在的空间;其二,只有一级页表需要一直保存在物理内存中,二级页表则不然,只有经常使用的需要保存在物理内存——还是为了节省空间^^,其三,也就是上面提过的问题,这样每个页表都只有1024个PTE,而每个PTE只占用4B大小,因此每个页表就只占用4kB空间了!——空间空间还是为了空间!
插一句,上面说的如此设计每个页表只占4kB,和我们说的单级页表中每个原始页面只占4kB,概念上完全是两回事,但如此设计却显得优雅。页表和页面的概念在这里灰常灰常容易搞混!切记不要搞混!万万不能搞混!重要的事情说三遍!!!
节省空间固然好,但如何在页表中查找PTE呢?比如我的页面大小是4KB,回忆下上节虚拟地址的结构是VPN+VPO,其中VPO是页面偏移,要满足4KB偏移大小,VPO就需要12位(2^12=1k*4),那么VPN就剩下32-12=20位可用,10位刚好可表示1024个值,于是我用10位去标识一级页表中1024个PTE,再用10位去标识每个一级页表PTE中存储的二级页表中的1024个PTE,于是这样划分的虚拟地址就能将上图的页表层次结构全部标识清楚:
| VPN1(10) | VPN2(10) | VPO(12) |
事实上,现代OS都是用多级页表结构,哪里才止2级,以便尽可能只缓存有用的信息。
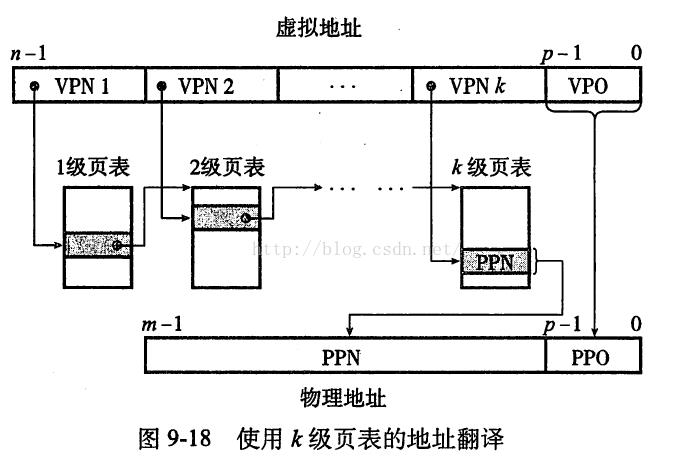
有没有瞬间觉得虚拟地址被玩坏的感觉?k级虚拟地址对应k级页表,多么高大上又朴实无华简易的思想!
以上是关于虚拟存储器——端到端地址翻译与多级页表的主要内容,如果未能解决你的问题,请参考以下文章