kafka总结
Posted taek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka总结相关的知识,希望对你有一定的参考价值。
参考 http://zqhxuyuan.github.io/2016/01/14/2016-01-14-Kafka-ISR/
http://zqhxuyuan.github.io/2016/01/13/2016-01-13-Kafka-Picture/
http://jianbeike.blogspot.com.au/2016/04/kafka.html
http://zqhxuyuan.github.io/2016/01/14/2016-01-14-Kafka-ISR/
http://www.oschina.net/translate/kafka-replication?print
http://www.jianshu.com/p/3f24d4b53f7f
https://www.iteblog.com/archives/1805
http://www.cnblogs.com/fxjwind/p/4972244.html
http://www.jasongj.com/2015/04/24/KafkaColumn2/
//kafka安装
http://yanliu.org/2015/08/31/kafka%E9%9B%86%E7%BE%A4%E9%85%8D%E7%BD%AE/
http://bbs.kekeyun.com/thread-101-1-1.html
http://blog.csdn.net/lizhitao/article/details/45066437
分布式系统 的优点 就是 将原本一台服务器受到的压力,分散到不同服务器上去
HW表示的是所有ISR中的节点都已经复制完的消息的offset.也是消费者所能获取到的消息的最大offset,所以叫做high watermark.
注意Leader Partition保存了ISR信息.所以可以看到maybeIncrementLeaderHW()是在appendToLocalLog()内一起执行的
任何Replication的LEO发生变化 (ISR中的followers有任何一个节点LEO改变,看看所有ISR是否都复制了,然后更新HW)
private def maybeIncrementLeaderHW(leaderReplica: Replica): Boolean = {
// 所有inSync副本中最小的LEO(因为每个follower的LEO都可能不一样), 表示的是最新的hw
val allLogEndOffsets = inSyncReplicas.map(_.logEndOffset)
val newHighWatermark = allLogEndOffsets.min(new LogOffsetMetadata.OffsetOrdering)
// Leader本身的hw, 是旧的
val oldHighWatermark = leaderReplica.highWatermark // 是一个LogOffsetMetadata
if(oldHighWatermark.precedes(newHighWatermark)) { // 比较Leader的messageOffset是否小于ISR的
leaderReplica.highWatermark = newHighWatermark // Leader小于ISR, 更新Leader为ISR中最小的
true
}else false // Returns true if the HW was incremented, and false otherwise.
}
delay operation complete http://zqhxuyuan.github.io/2016/01/14/2016-01-14-Kafka-ISR/
触发条件(延迟请求以及增加HW)中关于ISR的部分都是环环相扣的:
- leader有新消息写到本地日志(生产者写新数据) –> A.2 –> DelayedFetch
- leader replication的LEO发生变化(追加了新消息) –> C.2 –> HW
- follower向Leader发起fetch请求(ISR的follower会和Leader保持同步) –> B.2 –> DelayedProduce
- follower所在replication的LEO发生变化(拉取了新消息到本地) –> C.2 –> HW
- 所有replication的LEO发生变化,Leader的HW也会变化(成功提交了消息) –> C
- http://zqhxuyuan.github.io/2016/01/14/2016-01-14-Kafka-ISR/.2 –> HW
- consumer读取至多Leader的HW,HW变化了,解锁consumer –> A.1 –> DelayedFetch
- producer等待ISR都同步成功,导致HW变化,就可以返回响应 –> B.1 –> DelayedProduce
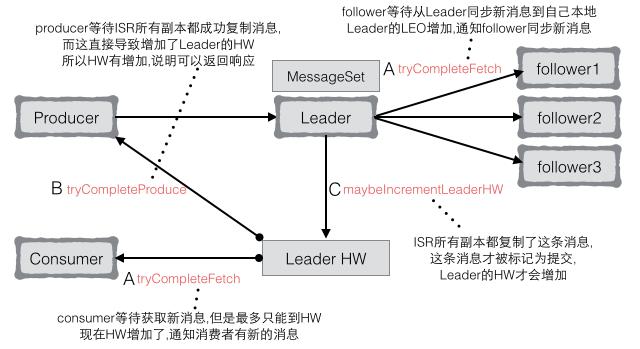
- Partition副本由Leader和follower组成,只有ISR列表中的副本是仅仅跟着Leader的
- Leader管理了ISR列表,只有ISR列表中的所有副本都复制了消息,才能认为这条消息是提交的
- Leader和follower副本都叫做Replica,同一个Partition的不同副本分布在不同Broker上
- Replica很重要的两个信息是HighWatermark(HW)和LogEndOffset(LEO)
- 只有Leader Partition负责客户端的读写,follower从Leader同步数据
- 所有Replica都会对HW做checkpoint,Leader会在follower的拉取请求时广播HW给follower
生产者生产数据后,相应broker会感知到offset的变化,然后通知它的follower,同时返回leader的HW, follower会主动向leader拉取数据,但每个follower所在的机器性能不同,可能拉取数据的个数也不一样,导致各个的LEO也不一样,为了分区对应的broker中的
数据一致,leader挑选follower返回的各自LEO中,选择最小的offset,做为HW,并更新,并通知生产者。
消费者只能消费处于HW以下的数据,因为以下的数据,在follower各个机器中都存在,可理解为数据是一致的
关于leader的选举原理
每一个分区对应的broker中,都只能有一个leader和若干个follower,
kafka没有采用 少数服从多数 分布式的选举方法,而是自己实现了一个 ISR (in sync replication) ISR中的follower都是在速度上能跟得上leader的broker
kafka集群第一次使用的时候,里面是没有数据的,
随机选一个broker作为leader,余下的broker放到ISR中, 同时启动一个线程,专门检查对应的follower,看他们在规定时间内是否fetch数据(默认1s),如果不符合这个条件,就将此follower踢出ISR
当leader宕机后,从ISR中挑选一个做为新leader,但如何挑选新的leader?
关于leader的选举方法
在kafka 0.8之前,在创建一个topic时,相应broker里面是没有数据的,那么随机找一个broker做为leader,余下的放到ISR中
每个分区中的follower所在的机器 ,都要/broker/ids/[0,1,2]做一个watch ,这样当/broker/ids/中的某个leader宕机后,zookeeper能通知相应follower,但这样zookeeper的负载很重
比如说100台broker,有2000个分区,每个分区有3个备份,那么在zookeeper中要安放2000*3=6000个watch,zookeeper本身也是集群,负载过重
kafka从0.8开始,不再采用上面的方法,在所有broker中选举出一个controller, 这个controler将决定各个分区中leader的选举
同时 在/broker/ids 做watch,/broker/topics 也做watch
在创建topic时,controler 在 /broker/ids 中读取broker id 列表,针对每一个分区,在所有的broker 中选取一个做为leader,余下的作为ISR,因为此时刚创建完topic,也没有数据
同时将leader 以及 ISR写到 /broker/topic/[topic_name]/partions/0/state 中去, 其内容大概为 leader 为 brokerA , ISR为[brokerB, brokerC, brokerD],
同时告诉相应的broker,因为有些broker是leader,有些broker是follower,要做一些初始化的工作
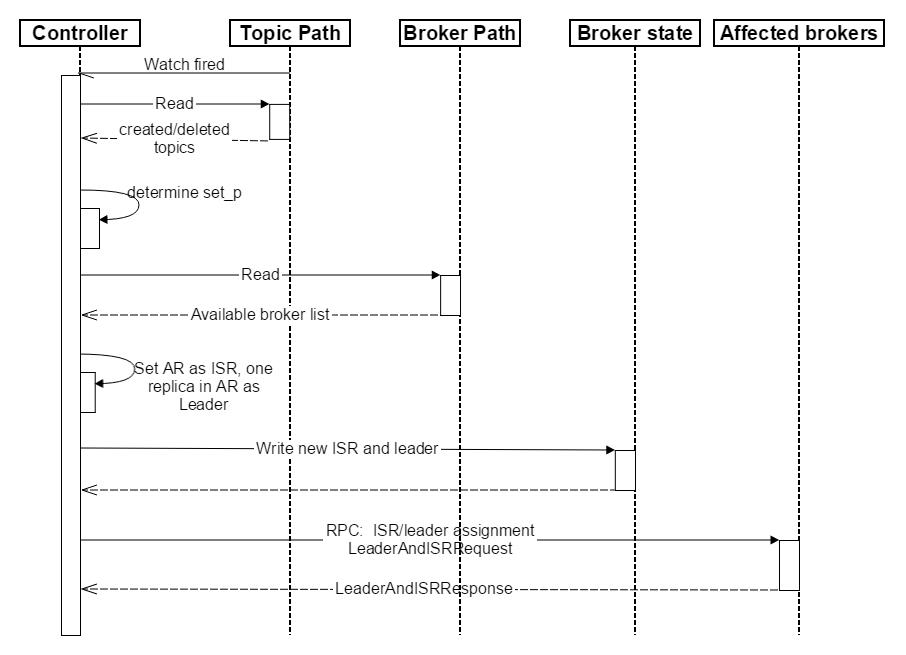
详见 http://jianbeike.blogspot.com.au/2016/04/kafka.html
makeLeader过程点评
leader的作用除了接收produce和consume请求,还有一点就是管理ISR以及highwatermark。而makeLeader过程就是为了开启leader的这些功能准备的,首先它要根据topic-partition创建(如果没有)message log目录,然后将自己的endlogoffset作为highwatermark,开启定期检测isr follower是否脱离isr(长时间未发fetch或者落后leaderlogendoffset太多)。
makeFollower过程点评
makeFollower的过程比makeLeader的过程要复杂,刚才说了,leader管理ISR和highwatermark(可以看概念说明那节),那么highwatermark对于Follower可见吗?当然Follower发送fetch请求时会将自身endlogoffset带过去,而返回结果中会有leader返回的
highwatermark。
为什么要有highwatermark?
答:看上图,假设某个topic-partition(比如topic1的partition0)的replicalist分配在4台机器上,A,B,C,D,produce端设置的ack为1,也就是只要leader 接收处理message成功就返回成功,那么这时replica list的endlogoffset会出现分化。
A作为leader肯定是endlogoffset最高,B紧随其后,C机器由于配置比较低,同步较慢,D机器配置最低,已经被A移除了ISR。
假设这个时候某几个机器出现故障,比如A,C宕机,这时B会成为leader,假如没有highwatermark,在A重启时的时候会做makeFollower操作,在宕机时log文件之后直接追加message,而假如B机器的endlogoffset已经达到A的endlogoffset,会产生数据不一致的情况,所以使用highwatermark来避免这种情况。
在A 做makeFollower操作时,将log文件truncate到highwatermark位置,以防止发生数据不一致情况发生。
还有一种情形会导致数据不一致,那就是uncleanleader election,ABC机器都宕机的情况,D机器已经启动,controller会将D作为leader,很明显即便有了highwatermark,也会发生数据不一致,同样消息数据也会丢失。目前kafka 0.8.1.1的版本,没有将unclean election 开关开放给用户,所以这块要做好监控
因为checkpoint记录的是所有Partition的hw offset. 当follower失败时,checkpoint中关于这个Partition的HW就不会再更新了.
而这个时候存储的HW信息和follower partition replica的offset并不一定是一致的. 比如这个follower获取消息比较快,
但是ISR中有其他follower复制消息比较慢,这样Leader并不会很快地更新HW,这个快的follower的hw也不会更新(leader广播hw给follower)
这种情况下,这个follower日志的offset是比hw要大的.所以在它恢复之后,要将比hw多的部分截掉,然后继续从leader拉取消息(跟平时一样).
实际上,ISR中的每个follower日志的offset一定是比hw大的.因为只有ISR中所有follower都复制完消息,leader才会增加hw.
也就是说有可能有些follower复制完了,而有些follower还没有复制完,那么hw是不会增加的,复制完的follower的offset就比hw要大.
停止对这些成为follower的partition的拉取线程,把这些partition的Log截断到highWaterMark的位置,并启动对那些成为leader的partition的拉取线程
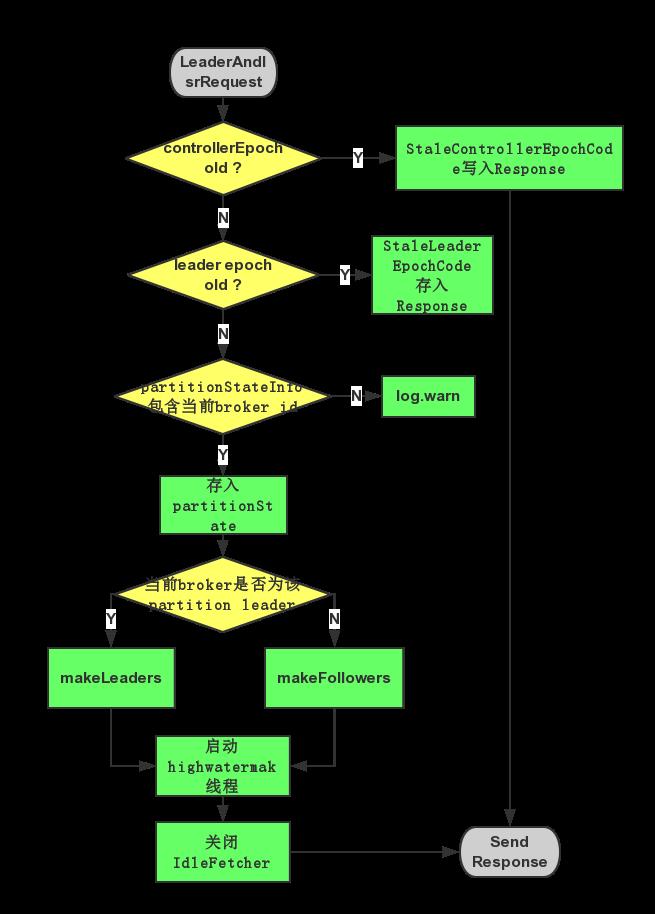
当 broker 宕机时,controller在/broker/ids做的watch也会触发 详见
跟创建 topic一样,遍历/broker/topic/[topic_name]/partition/0/state ,在ISR中选择一个活着的broker,如果没有,就在所有的备份broker中找一个,
然后再将新的 leadre, ISP 写到上面路径去,同时通知相关broker,做好makeLeader,makeFollower工作
producers
producer发送消息。
producer 可以直接发送到broker对应的leader partition中,不需要经历任何一个中介的转发。为实现这个特性,每个broker都可以响应producer的请求,并返回topic的一些元信息,这些元信息包括哪些机器是存活的,topic的你leader partition都在哪。现阶段哪些leader partition 是可以直接访问的?
如果访问的不是leader partition 怎么搞? 而且我看是可以指定多个进行访问的。
producer 和 partition 。
producer 可以控制以什么样的将消息推送到客户端。实现方法包括随机,实现一类随机负载均衡的算法,或者指定一些分区算法。kafka 提供了用户自定义分区的方法,用户可以为每一个消息指定一个partitionkey,通过这个key来实现一些hash 分区算法。
http://www.aichengxu.com/view/4683767
副本获取器线程,主要定义了以下几个方法:
1. handlePartitionsWithErrors:处理有错误(leader已经发生编程)的分区,当前什么都不做因为controller会应对这些变更
2. handleOffsetOutOfRange:处理一个位移越界的分区返回新的获取位移值(fetch offset),具体逻辑如下:
获取给定topic分区在该broker上的副本
获取该分区leader的结束位移值,如果leader的结束位移值比该副本的结束位移还小的话,先判断一下是否启用了unclean leader选举。若没有启用,直接报错;否则就将follower副本的位移直接截取成leader的结束位移
若follower位移比leader的还小,直接截取所有位移并设置leader的初始位移处开始读取leader
如果启用了unclean leader选举,那么就有可能出现这样的情景:一个follower宕机了,而同时leader还在不停地写入消息。当这个follower重启回来的时候它需要完整地追上leader的进度。就在这个过程中,ISR中所有的副本都宕掉了。那么此时这个follower就会被unclean leader选举为新的leader,然后它开始写入从客户端发来的消息。之后旧的leader恢复,成为了一个follower,它会发现当前leader的最新位移居然比自己的还要小。这种情况下,只能截断自己的位移使之与当前leader的最新位移保持一致然后继续处理。
3. processPartitionData:处理获取到的数据。主要逻辑就是将给定的response数据解析出来并更新到该broker上的副本对象中,比如获取到的消息集合以及更新高水位值
Replicated Logs
Kafka的partition可以看成是一个replicated log, 每个replica就是这个replicated log其中的一个log。多个replica是为了容忍机器故障,因此同一个partition的不同replica需要被分配到不同的broker上。所以,对于一个partition,broker id即可唯一代表一个replica,也被当作replica id。
为了一致性,Kafka在同一个partition的replicas中选出一个作为leader,由它接受client的所有读写请求,而其它的replica作为follower,从leader处拉取数据,leader作为唯一的"source of truth"。在有些情况下,follower会truncate自己的log(这个log和以下的log都是指"replicated log"这个概念里的log),然后重新从leader处抓取数据,以求与leader一致(下面会讲到)。
leader和follower的角色区分,也主要是ReplicaManager来实现。具体地讲
- leader
- leader会接受client的读取请求和写入请求。
- leader需要接受follwer抓取message的请求,返回message给follower
- leader需要维护ISR(in-sync replicas)列表。“保持同步”的含义有些复杂,0.9之前版本对这个概念的定义与0.9不同,详情参见KIP-16 - Automated Replica Lag Tuning。0.9版本,broker的参数replica.lag.time.max.ms用来指定ISR的定义,如果leader在这么长时间没收到follower的拉取请求,或者在这么长时间内,follower没有fetch到leader的log end offset,就会被leader从ISR中移除。ISR是个很重要的指标,controller选取partition的leader replica时会使用它,因此leader选取ISR后会把结果记到Zookeeper上。
- leader需要维护high watermark。high watermark以下的消息就是所有ISR列表里的replica都已经读取的消息(注意,并不是所有replica都一定有这些消息,而只是ISR里的那些才肯定会有)。因此leader会根据follower拉取数据时提供的offset和ISR列表,决定HW,并且在返回给follower的请求中附带最新的HW。
- follower
- follower需要不停地去leader处拉取最新的log
- follower需要根据leader在fetch reponse中提供的HW,更新自己本地保存的leader的HW信息。在它过行leader或follower转变时,会用到这个HW。
HW与LEO
HW、ISR以及leader对于partition这个多副本系统算是一种元数据。ISR和leader确要在controller和所有replica之间保持一致,HW需要在leader和follower之间保持一致,因为在leader转换的时候,HW是安全线。
下面明确一下high watermark和log end offset在源码里的意义
HW high watermark offset的数据小于被认为是commit的,注意,offset为high watermark的message并不是commit的。
LEO log end offset 这个replica的log里最后一条消息的下一条消息的offset
这些数据根据实际需求,以不同的方式在Kafka中传递:
- HW。随着follower的拉取进度的即时变化,HW是随时在变化的。follower总是向leader请求自己已有messages的下一个offset开始的数据,因此当follower发出了一个fetch request,要求offset为A以上的数据,leader就知道了这个follower的log end offset至少为A。此时就可以统计下ISR里的所有replica的LEO是否已经大于了HW,如果是的话,就提高HW。同时,leader在fetch本地消息给follower时,也会在返回给follower的reponse里附带自己的HW。这样follower也就知道了leader处的HW(但是在实现中,follower获取的只是读leader本地log时的HW,并不能保证是最新的HW)。但是leader和follower的HW是不同步的,follower处记的HW可能会落后于leader。
- ISR以及leader。 在需要选举leader的场景下,leader和ISR是由controller决定的。在选出leader以后,ISR是leader决定。如果谁是leader和ISR只存在于ZK上,那么每个broker都需要在Zookeeper上监听它host的每个partition的leader和ISR的变化,这样效率比较低。如果不放在Zookeeper上,那么当controller fail以后,需要从所有broker上重新获得这些信息,考虑到这个过程中可能出现的问题,也不靠谱。所以leader和ISR的信息存在于Zookeeper上,但是在变更leader时,controller会先在Zookeeper上做出变更,然后再发送LeaderAndIsrRequest给相关的broker。这样可以在一个LeaderAndIsrRequest里包括这个broker上有变动的所有partition,即batch一批变更新信息给broker,更有效率。另外,在leader变更ISR时,会先在Zookeeper上做出变更,然后再修改本地内存中的ISR。
Hight Watermark Checkpoint
以外,由于HW是随时变化的,如果即时更新到Zookeeper,会带来效率的问题。而HW是如此重要,因此需要持久化,ReplicaManager就启动了单独的线程定期把所有的partition的HW的值记到文件中,即做highwatermark-checkpoint。
Epoch
除了leader,ISR之外,在replica系统中还有其它三个对于一致性有重要作用的参数:controller epoch、leader epoch和zookeeper version。
- controller epoch: 当新的controller开始工作后,旧的controller可能还在工作,这时就会有两个自认为是的controller,那么broker该听哪个的呢?cpmtroller epoch是一个整数,记在Zookeeper的/controller_epoch path的数据中,当新的controller当选后,它更新Zookeeper中的这个数据,把这个整数的值+1,并且以每个命令中都附带上controller epoch。这样broker收到一个controller的命令后,就与自己内存中保存的controller epoch比较,如果命令中的值小于内存中的值,就代表是旧的controller的命令,如果大于内存中的值,就更新内存中的controller epoch为新值,并且执行命令。
- leader epoch: 对于同一个controller,也存在它的LeaderAndIsrRequest以错误的顺序到达broker的可能,这样broker就可以在检查controller的epoch之后,再检查leader epoch,以确认该执行哪个命令。
- zkVersion 对于在zookeeper path中存储的controller epoch, leaderAndIsr信息进行更新时,始终都得进行条件更新,以避免产生竞态。比如,在controller读取Zookeeper上的leaderAndIsr信息后,更新leaderAndIsr信息前,如果leader更改了ISR的信息,而controller以更改前的ISR进行leader选举的话,就可能会产生异常状态;或者在controller更新完leaderAndIsr之后,旧的leader又去更新zk上的这个数据,也会使集群不一致。所以,就需要zkVersion来进行条件变更。controller和replica在内存中存储上一次状态更新时读取到的zkVersion,当它依据此状态做出决定时,需要带上这个zkVersion做条件更新,以保证根据旧状态做出的更新不会生效。这种条件更新是使用的kafka.utils.ZkUtils的conditionalUpdatePersistentPath方法。
由这三个版本号共同作用,Kafka基本都保证对于leader, ISR, controller的认知在各个broker间不会出现大问题(但是还会有bug和潜在的问题导致认知不一致)。
update MetadataCache
此外,当broker收到UpdateMetadataRequest时,它会把这个request交给ReplicaManager处理,而ReplicaManager在确定UpdateMetadataRequest的controller epoch有效之后,就会交由MetadataCache来处理。之所以不直接收MetadataCache处理,可能是ReplicaManager处会保存controller epoch, 不过MetadataCache内部也可能获取controller epoch,只是没有做为单独的一个field保存起来。这样做显得有些混乱,不知道是什么原因。
The Producer
负载均衡
1)producer可以自定义发送到哪个partition的路由规则。默认路由规则:hash(key)%numPartitions,如果key为null则随机选择一个partition。
2)自定义路由:如果key是一个user id,可以把同一个user的消息发送到同一个partition,这时consumer就可以从同一个partition读取同一个user的消息。
异步批量发送
批量发送:配置不多于固定消息数目一起发送并且等待时间小于一个固定延迟的数据。
The Consumer
consumer控制消息的读取。
Push vs Pull
1)producer push data to broker,consumer pull data from broker
2)consumer pull的优点:consumer自己控制消息的读取速度和数量。
3)consumer pull的缺点:如果broker没有数据,则可能要pull多次忙等待,Kafka可以配置consumer long pull一直等到有数据。
Consumer Position
1)大部分消息系统由broker记录哪些消息被消费了,但Kafka不是。
2)Kafka由consumer控制消息的消费,consumer甚至可以回到一个old offset的位置再次消费消息。
Message Delivery Semantics
三种:
At most once—Messages may be lost but are never redelivered.
At least once—Messages are never lost but may be redelivered.
Exactly once—this is what people actually want, each message is delivered once and only once.
Producer:有个”acks“配置可以控制接收的leader的在什么情况下就回应producer消息写入成功。
Consumer:
* 读取消息,写log,处理消息。如果处理消息失败,log已经写入,则无法再次处理失败的消息,对应”At most once“。
* 读取消息,处理消息,写log。如果消息处理成功,写log失败,则消息会被处理两次,对应”At least once“。
* 读取消息,同时处理消息并把result和log同时写入。这样保证result和log同时更新或同时失败,对应”Exactly once“。
Kafka默认保证at-least-once delivery,容许用户实现at-most-once语义,exactly-once的实现取决于目的存储系统,kafka提供了读取offset,实现也没有问题。
ü controllerEpoch
为了防止先发的请求后到来导致broker数据不一致,所以使用版本管理数据,每次更换controller,epoch加1,所以broker永远只响应本次请求中epoch>=上次请求epoch的请求。
ü leaderEpoch
为了防止先发的请求后到来导致broker数据不一致,所以使用版本管理数据,每次选主更换leader,epoch加1,所以broker永远只响应本次请求中epoch>=上次请求epoch的请求
以上是关于kafka总结的主要内容,如果未能解决你的问题,请参考以下文章