深入理解计算机系统02ISA 与内存模型
Posted 萤火之森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解计算机系统02ISA 与内存模型相关的知识,希望对你有一定的参考价值。
第二篇:认识ISA(Instruction Set Architecture)
重要概念:
- 【ISA】
- 【IA-32】:Intel把32位x86架构的名称x86-32改称为IA-32,一种身边很常见的ISA
- 【内存模型】
- 【过程调用】
•ISA(Instruction Set Architecture)位于软件和硬件之间
•硬件的功能通过ISA提供出来
•软件通过ISA规定的"指令"使用硬件
•ISA规定了:
–可执行的指令的集合,包括指令格式、操作种类以及每种操作对应的操作数的相应规定;
–指令可以接受的操作数的类型;
–操作数所能存放的寄存器组的结构,包括每个寄存器的名称、编号、长度和用途;
–操作数所能存放的存储空间的大小和编址方式;
–操作数在存储空间存放时按照大端还是小端方式存放;
–指令获取操作数的方式,即寻址方式;
–指令执行过程的控制方式,包括程序计数器、条件码定义等。
IA-32 规定的几个方面:
『IA-32是CISC 复杂指令集』
- IA-32支持的数据结构类型和格式
- IA-32的寄存器组织
- IA-32的标志寄存器
- IA-32的寻址方式
- 浮点寄存器栈和多媒体扩展寄存器组
- IA-32 常用指令类型
》 程序的转换与机器级表示
了解高级语言与汇编语言、
汇编语言与机器语言之间的关系
掌握有关指令格式、
操作数类型、
寻址方式、
操作类型等内容
了解高级语言源程序中的语句与机器级代码之间的对应关系
了解复杂数据类型(数组、结构等)的机器级实现
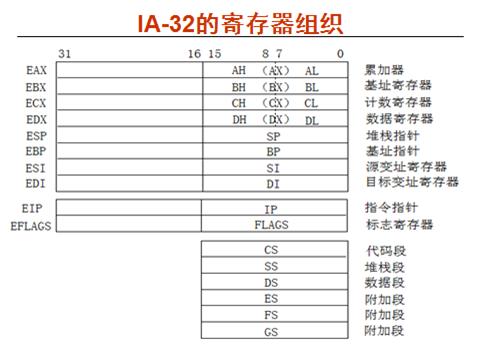
0. IA-32寄存器模型
》 理解计算机是如何工作的
程序由指令组成
程序在执行前:
数据和指令事先存放在存储器中,每条指令和每个数据都有地址,指令按序存放,指令由OP、ADDR字段组成,程序起始地址置PC
(原材料和菜谱都放在厨房外的架子上, 每个架子有编号。妈妈从第5个架上指定菜谱开始做)
开始执行程序:
第一步:根据PC取指令(从5号架上取菜谱)
第二步:指令译码(看菜谱)
第三步:取操作数(从架上或盘中取原材料)
第四步:指令执行(洗、切、炒等具体操作)
第五步:回写结果(装盘或直接送桌)
第六步:修改PC的值(算出下一菜谱所在架子号6=5+1)
继续执行下一条指令(继续做下一道菜)

》☆ 内存模型
作者注:
『不同语言有不同的内存模型。只有掌握了内存模型,才算是真正具有了对程序的时间和空间效率进行分析的基本能力。
如编译性语言C、C++,对它们的分析要结合编译出的汇编语言,同时也要注意操作系统和编译器对内存管理的影响。
至于操作系统和编译器对内存模型产生了何种影响,还需要进一步学习。』
Process virtual address space.
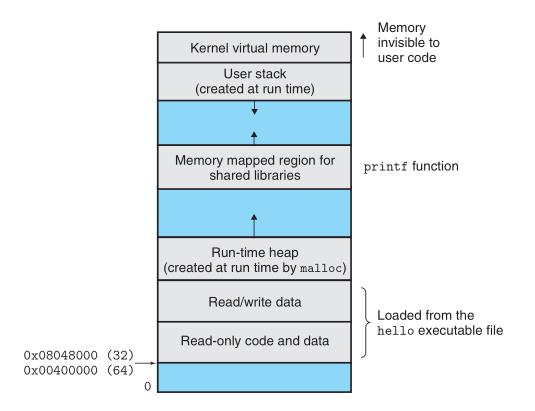
【图片摘自 CSAPP 3rd】

. Heap.The code and data areas are followed immediately by the run-time heap. Unlike the code and data areas, which are fixed in size once the process begins running, the heap expands and contracts dynamically at run time as a result of calls to C standard library routines such as malloc and free.
堆,用于存放程序动态创建的数据。
. Shared libraries.Near the middle of the address space is an area that holds the code and data for shared libraries such as the C standard library and the math library. The notion of a shared library is a powerful but somewhat difficult concept.
共享存储区:
静态存储区:存放共享数据
. Stack. At the top of the user\'s virtual address space is the user stack that the compiler uses to implement function calls. Like the heap, the user stack expands and contracts dynamically during the execution of the program. In particular, each time we call a function, the stack grows. Each time we return from a function, it contracts.
栈:用于程序调用过程中的数据存储,局部变量。
. Kernel virtual memory. The kernel is the part of the operating system that is always resident in memory. The top region of the address space is reserved for the kernel. Application programs are not allowed to read or write the contents of this area or to directly call functions defined in the kernel code.
核心虚拟存储区:操作系统专用存储区。

》过程调用的机器级表示:
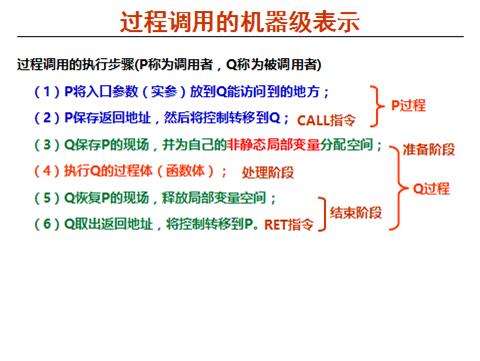

每次递归调用都会增加一个栈帧,所以空间开销很大。
》IA-32的寄存器使用约定
调用者保存寄存器:EAX、EDX、ECX
当过程P调用过程Q时,Q可以直接使用这三个寄存器,不用将它们的值保存到栈中。如果P在从Q返回后还要用这三个寄存器的话,P应在转到Q之前先保存,并在从Q返回后先恢复它们的值再使用。
被调用者保存寄存器:EBX、ESI、EDI
Q必须先将它们的值保存到栈中再使用它们,并在返回P之前恢复它们的值。
EBP和ESP分别是帧指针寄存器和栈指针寄存器,分别用来指向当前栈帧的底部和顶部。
》过程调用中两种传递参数的方式:
1. 按值传递
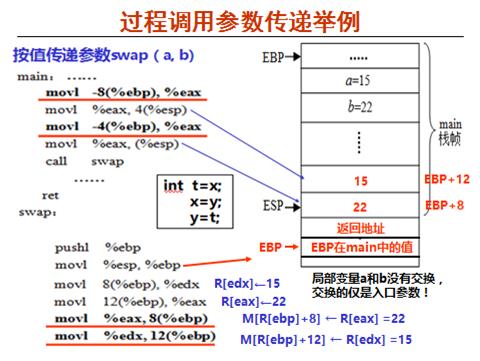
2. 按地址传递
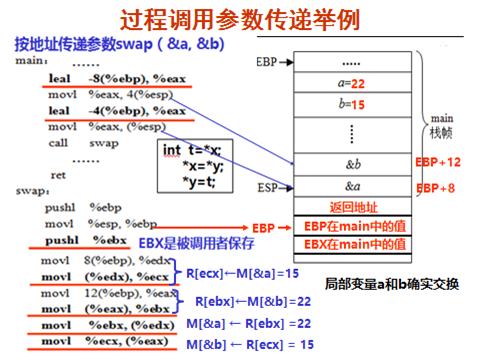
》数组的分配和访问:
1. 分配到静态区
全局变量、静态数据
2. 分配在栈中,通过EBP来定位
局部变量、入口参数
》栈桢:
push %ebp
mov %esp,%ebp
每次跳转都会执行两跳语句构成栈底(在高地址)。ebp存放的是原ebp值
》 有时间可以去学习一下程序如何对应机器指令,即编译成汇编语言的过程。
》 数据的访问:

其中2、4没有访存操作,明白指针在提高执行效率时的厉害之处了吧。
》 数据的对齐
机器字长为固定的32位或64位。数据按字节编址,每一次访问可能会跨越地址。
对齐的目的是:减少访存次数,提高时间和空间效率。(毕竟数据总线每次读好多个字节呢!)
> 数据的对齐
x86-64中各类型数据遵循一定的对齐规则,而且更严格
x86-64中存储器访问接口被设计成按8字节或16字节为单位进行存取,其对齐规则是,任何K字节宽的基本数据类型和指针类型数据的起始地址一定是K的倍数
例如int类型占用4个字节,地址只能在0,4,8等位置上。
> 对齐方式:
#pragma pack(n)
•为编译器指定结构体或类内部的成员变量的对齐方式。
•当自然边界(如int型按4字节、short型按2字节、float按4字节)比n大时,按n字节对齐。
•缺省或#pragma pack() ,按自然边界对齐。
__attribute__((aligned(m)))
•为编译器指定一个结构体或类或联合体或一个单独的变量(对象)的对齐方式。
•按m字节对齐(m必须是2的幂次方),且其占用空间大小也是m的整数倍,以保证在申请连续存储空间时各元素也按m字节对齐。
__attribute__((packed))
l不按边界对齐,称为紧凑方式。
不同操作系统对齐策略可能有所不同。导致不同的结构声明顺序的内存利用效率不同。
Windosws策略:
Linux策略:
{
待补充~~
}

Ps:学习完这些就可以为后边的缓冲区溢出做好准备了。
我来总结一下:
从以上内容可以看出来,人们做了大量工作去减少访存次数,提高系统的时间和空间效率。因为相比访问寄存器,访问存储器的开销还是很大的。
注意在软件方面同样可以采取很多有效的措施减少访存次数。
各种各样的寻址方式也都是为了适应高级语言中的数据类型产生的访存需要。
转载请注明出处:http://www.cnblogs.com/learn-to-rock/p/5876337.html
以上是关于深入理解计算机系统02ISA 与内存模型的主要内容,如果未能解决你的问题,请参考以下文章