Spark RDD编程
Posted Thinkgamer_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD编程相关的知识,希望对你有一定的参考价值。
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
RDD的分区函数
目前Spark中实现的分区函数包括两种
-
HashPartitioner(哈希分区)
原理图:
-
RangePartitioner(区域分区)
partitioner这个属性只存在于< K,V>类型的RDD中,对于非< K,V >类型的partitioner的值就是None,partitioner函数即决定了RDD本身的分区数量,也可作为RDD shuffle输出中每个区分进行数据切割的依据。
scala> val rdd = sc.makeRDD(1 to 10,2).map(x=>(x,x))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:27
scala> rdd.partitioner
res0: Option[org.apache.spark.Partitioner] = None
scala> val group_rdd = rdd.groupByKey(new org.apache.spark.HashPartitioner(3))
group_rdd: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[2] at groupByKey at <console>:29
scala> group_rdd.partitioner
res1: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
scala> group_rdd.collect()
res4: Array[(Int, Iterable[Int])] = Array((6,CompactBuffer(6)), (3,CompactBuffer(3)), (9,CompactBuffer(9)), (4,CompactBuffer(4)), (1,CompactBuffer(1)), (7,CompactBuffer(7)), (10,CompactBuffer(10)), (8,CompactBuffer(8)), (5,CompactBuffer(5)), (2,CompactBuffer(2)))
**RDD的基本转换操作 **
1. repartition 和 coalesce
两者都是对rdd分区进行重新划分,repartition只是coalesce接口中shuffle为true的简易实现,这里我们讨论一下coalesce合并函数该如何设置shuffle参数,这里分三种情况(假设RDD有N个分区,需要重新划分为M个分区)
- 如果N < M
一般情况下N个分区有数据分布不均的情况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle的参数设置为true - 如果N > M(两者相差不大)
两者相差不大的情况下,就可以将N中的若干个分区合并未一个分区,最终合并未M个分区,这时可以将shuffle参数设置为false(在shuffle为false的情况下,设置M>N,coalesce是不起作用的),不进行shuffle过程,父RDD和子RDD之间是窄依赖关系。 - 如果N>>M(N远大于M的情况)
N,M相差悬殊的时候如果把shuffle参数设置为false,由于父子
RDD是窄依赖,他们同处在一个Stage中,就有可能造成Spark程序运行的并行度不高,从而影响性能。比如在M为1时,由于只有一个分区,所以只会有一个任务在运行,为了使coalesce之前的操作有更好的并行度,可以将shuffle参数设置为true。
scala> val rdd = sc.makeRDD(1 to 10,100)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at makeRDD at <console>:21
scala> rdd.partitions.size
res14: Int = 100
scala> val repartitionRDD = rdd.repartition(4)
repartitionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[30] at repartition at <console>:23
scala> repartitionRDD.partitions.size
res15: Int = 4
------------------------------------------------------------------------
scala> val coalesceRDD = rdd.coalesce(3)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[31] at coalesce at <console>:23
scala> coalesceRDD.partitions.size
res16: Int = 3
scala> val coalesceRDD = rdd.coalesce(1)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[34] at coalesce at <console>:23
scala> coalesceRDD.partitions.size
res17: Int = 1
scala> val coalesceRDD = rdd.coalesce(1,shuffle=true) #增加并行度
coalesceRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[38] at coalesce at <console>:23
res18: Int = 1
如果第二次分区的数目大于现有的分区数,不指定参数时,分区数不改变,也就是说在不进行洗牌的情况下,是无法将RDD的分区数目进行改变的
scala> val rdd = sc.makeRDD(1 to 1000,1000)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at makeRDD at <console>:21
scala> val coalesceRDD = rdd.coalesce(1)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[40] at coalesce at <console>:23
scala> coalesceRDD.partitions.size
res21: Int = 1
scala> val coalesceRDD = rdd.coalesce(100000)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[41] at coalesce at <console>:23
scala> coalesceRDD.partitions.size
res22: Int = 1000
scala> val coalesceRDD = rdd.coalesce(100000,shuffle=true)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[45] at coalesce at <console>:23
scala> coalesceRDD.partitions.size
res23: Int = 100000
2. randomSplit()和glom()
randomSplit是根绝weights权重将一个RDD切分成多个RDD,而glom函数是将RDD中每一个分区中类型为T的元素转换为数组[T],这样每一个分区就只有一个数组元素。
scala> val rdd = sc.makeRDD(1 to 10,3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[50] at makeRDD at <console>:21
scala> rdd.collect()
res26: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val glomRDD = rdd.glom()
glomRDD: org.apache.spark.rdd.RDD[Array[Int]] = MapPartitionsRDD[51] at glom at <console>:23
scala> glomRDD.collect()
res27: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6), Array(7, 8, 9, 10))
-------------------------------------------------------------------
scala> val rdd = sc.makeRDD(1 to 10,10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at makeRDD at <console>:21
scala> rdd.collect()
res32: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val splitRDD = rdd.randomSplit(Array(1.0,3.0,6.0))
splitRDD: Array[org.apache.spark.rdd.RDD[Int]] = Array(MapPartitionsRDD[57] at randomSplit at <console>:23, MapPartitionsRDD[58] at randomSplit at <console>:23, MapPartitionsRDD[59] at randomSplit at <console>:23)
scala> splitRDD(0).collect()
res33: Array[Int] = Array()
scala> splitRDD(1).collect()
res34: Array[Int] = Array(6)
scala> splitRDD(2).collect()
res36: Array[Int] = Array(1, 2, 3, 4, 5, 7, 8, 9, 10)
3. mapPartitions和mapPartitionsWithIndex
mapPartitions与map转换操作类似,只不过映射函数的输入参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器,该操作有一个参数perservesPartitioning指明mapPartitions是否保留父RDD的partitions的分区信息。mapPartitionWithIndex和mapPartitions功能类似,只是输入参数时多了一个分区的ID
scala> val rdd = sc.makeRDD(1 to 5,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at makeRDD at <console>:27
scala> val mapRDD = rdd.map(x=>(x,x))
mapRDD: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[5] at map at <console>:29
scala> val groupRDD = mapRDD.groupByKey(3)
groupRDD: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[6] at groupByKey at <console>:31
scala> val mapPartitionsRDD = groupRDD.mapPartitions(iter=>iter.filter(_._1>3))
mapPartitionsRDD: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = MapPartitionsRDD[7] at mapPartitions at <console>:33
scala> mapPartitionsRDD.collect()
res3: Array[(Int, Iterable[Int])] = Array((4,CompactBuffer(4)), (5,CompactBuffer(5)))
scala> mapPartitionsRDD.partitioner
res4: Option[org.apache.spark.Partitioner] = None
scala> val mapPartitionsRDD = groupRDD.mapPartitions(iterator => iterator.filter(_._1>3),true)
mapPartitionsRDD: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = MapPartitionsRDD[8] at mapPartitions at <console>:33
scala> mapPartitionsRDD.partitioner
res5: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
3. zip和zipPartitions
zip是将两个RDD组成key/value(键/值)形式的RDD,这里认为两个rdd的partitioner数量以及元素数量都相等。
zipPartitions是将多个RDD,按照partition组合成新的RDD,zipPartitions需要相互组合的RDD具有相同的分区数,但是对于每个分区中的元素数量是没有限制的
scala> val rdd = sc.makeRDD(1 to 5,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:27
scala> val mapRDD=rdd.map(x=>(x+1.0))
mapRDD: org.apache.spark.rdd.RDD[Double] = MapPartitionsRDD[1] at map at <console>:29
scala> val zipRDD = rdd.zip(mapRDD)
zipRDD: org.apache.spark.rdd.RDD[(Int, Double)] = ZippedPartitionsRDD2[2] at zip at <console>:31
scala> zipRDD.collect
res0: Array[(Int, Double)] = Array((1,2.0), (2,3.0), (3,4.0), (4,5.0), (5,6.0))
scala> val rdd1=sc.makeRDD(Array("1","2","3","4","5","6"),2)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[6] at makeRDD at <console>:21
scala> val zipPartitionsRDD = rdd.zipPartitions(rdd1)((i:Iterator[Int],s:Iterator[String])=>{Iterator(i.toArray.size,s.toArray.size)})
zipPartitionsRDD: org.apache.spark.rdd.RDD[Int] = ZippedPartitionsRDD2[7] at zipPartitions at <console>:25
scala> zipPartitionsRDD.collect()
res3: Array[Int] = Array(2, 3, 3, 3)
##4. zipWithIndex和zinWithUniqueId
zipWithIndex是将RDD中的元素和这个元素的ID组合成键/值对,比如说第一个分区的第一个元素是0,第一个分区的第二个元素是1,依次类推
zipWithUniqueID是将RDD中的元素和一个唯一ID组合成键/值对,假设RDD共有N个分区,那么第一个分区的第一个元素唯一ID是1,第一个分区的第二个元素就是1+N,第一个分区的第三个元素就是1+2N,依次类推
scala> val rdd = sc.makeRDD(1 to 6,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:21
scala> val zipWithIndex = rdd.zipWithIndex()
zipWithIndex: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[1] at zipWithIndex at <console>:23
scala> zipWithIndex.collect()
res0: Array[(Int, Long)] = Array((1,0), (2,1), (3,2), (4,3), (5,4), (6,5))
scala> val zipWithUniqueID = rdd.zipWithUniqueId()
zipWithUniqueID: org.apache.spark.rdd.RDD[(Int, Long)] = MapPartitionsRDD[2] at zipWithUniqueId at <console>:23
scala> zipWithUniqueID.collect()
res1: Array[(Int, Long)] = Array((1,0), (2,2), (3,4), (4,1), (5,3), (6,5))
**控制操作 **
在Spark中对RDD持久化操作时一项非常重要的功能,可以将RDD持久化在不同层次的存储介质中,以便后续的操作能够重复使用
- checkpoint
将RDD持久化在HDFS上,与persist的一个区别是会切断此RDD之前的依赖关系,而persist依然保留着RDD的依赖关系。
checkpoint的主要作用
1、如果一个spark程序会很长时间驻留运行(如spark streaming 一般会7*2小时运行),过长的依赖将会占用很多系统资源,那么定期的将RDD进行checkpoint操作,能够有效节省系统资源
2、维护过长的依赖关系还会出现一些小问题,如果Spark在运行过程中出现节点失败的情况,那么RDD进行容错重算的成本会非常高
scala> val rdd = sc.makeRDD(1 to 4,1)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[60] at makeRDD at <console>:21
scala> val flatMapRDD = rdd.flatMap(x=>Seq(x,x))
flatMapRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[61] at flatMap at <console>:23
scala> sc.setCheckpointDir("temp")
16/09/14 10:56:08 WARN spark.SparkContext: Checkpoint directory must be non-local if Spark is running on a cluster: temp
scala> flatMapRDD.checkpoint()
scala> flatMapRDD.dependencies.head.rdd
res40: org.apache.spark.rdd.RDD[_] = ParallelCollectionRDD[60] at makeRDD at <console>:21
scala> flatMapRDD.collect()
res41: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4)
scala> flatMapRDD.dependencies.head.rdd
res42: org.apache.spark.rdd.RDD[_] = ReliableCheckpointRDD[62] at collect at <console>:26
在hdfs上查看具体信息

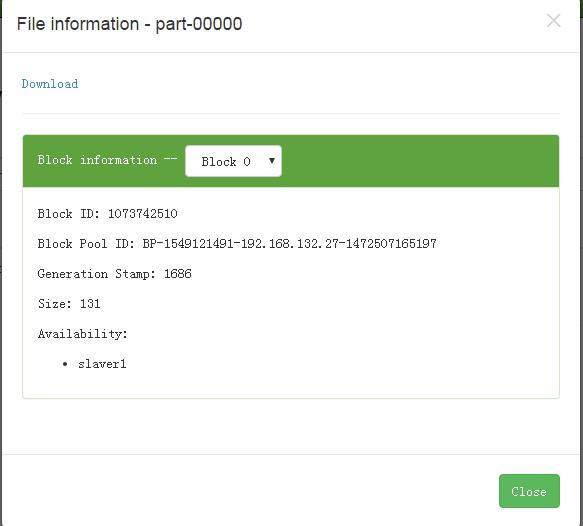
-
persist
使用和checkpoint类似,这里不做演示,可参考 Spark RDD编程(一)
**行动操作 **
这里我们不具体列出使用案例,在Spark RDD编程(一)中已经详细说明,这里只做一个回顾与总结
-
集合标量行动操作
函数名称 | 功能
-------- | —
first | 返回rdd中的第一个元素
count | 返回RDD中元素的个数
reduce | 对rdd中的元素进行二元运算,返回计算结果
collect()/toArray() |以集合形式返回RDD的元素
take(num:Int) |将RDD作为集合,返回集合中[0,num-1]下标的元素
top(num:Int)|按照默认的或者是指定的排序规则,返回前num个元素
takeOrdered(num:Int) |以与top相反的排序规则,返回前num个元素
aggregate |比较麻烦参考Spark RDD编程(一)
fold |是aggregate的便利接口
lookup(Key:K):Seq[v] |针对(K,V)类型的RDD行动操作,对于给定的键值,返回与此键值相对应的所有值
-
存储行动操作
函数名称 | 功能
-------- | —
saveAsTextFile() | 保存到hdfs
saveAsObjectFile() |用于将RDD中的元素序列化成对象,存储到文件中。对于HDFS,默认采用SequenceFile保存。
saveAsHadoopFile()| 保存为hadoop的一种格式,比如说TextFileOutputFormat,SequenceFileOutputFormat,OutputFormat…
saveAsHadoopDataset()|保存到数据库如hbase,mongodb,Cassandra
END!

以上是关于Spark RDD编程的主要内容,如果未能解决你的问题,请参考以下文章