第二周:词频统计改进
Posted yuanyuancheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二周:词频统计改进相关的知识,希望对你有一定的参考价值。
需求:
1.在控制台输入命令;
2.输入必须是在硬盘上已经存在的路径或者是文件;
3.输入的是目录名就把目录统计出来;
4.输入时文件就把文件里面的单词统计出来.
分析:
1.读取文件使用BufferedReader类按行读取;
2.定义一个正则表达式过滤字符串符号;
3.创建hashmap;
4.使用StringTokenizer来分词;
5.把分的单词加入haspmap存储的键值对;
6,遍历HashMap输出结果;
7.让用户在控制台输入一个路径;
8.对用户输入的路径进行判断如果是目录就遍历目录,在统计里面的单词;
9.否则就是文件,就遍历文件,在使用Collections.sort()方法排序在统计文件里面的单词.
具体代码实现:
1.判断输入的是否是目录,是目录遍历并统计。
1 File file = new File(url);//创建File对象 2 if(file.isDirectory()){ //判断file 对象是否是目录 3 String[] names = file.list();//获取目录下的所有文件的文件名 4 for (String name : names) { 5 System.out.println(name); 6 if(!hashMap.containsKey(name)){ //判断hashMap里面是否有该单词 7 hashMap.put(name, new Integer(1)); 8 //如果没有 把word的值当作键 ,key值记作一次 9 10 }else{ 11 int k=hashMap.get(name).intValue()+1; //如果有 把word的值当作键 ,key值在原来基础上在加一次 12 hashMap.put(name, new Integer(k)); 13 14 } 15 for(String key : hashMap.keySet()){ 16 //打印单词 以及单词的 个数 17 System.out.println(key + ":\t"+ hashMap.get(key)); 18 } 19 20 21 } 22 23 24 }
2.如果输入的是文件,就读取文件里面的单词。
//当时文件的时候统计文件里面的单词 else{ BufferedReader br=new BufferedReader(new FileReader(url)); String value; while((value=br.readLine())!=null){ //读取文本,读一行,直到读完为止 value=value.replaceAll(fregex, " "); //用空格 代替文本中的一些特殊符号 //使用StringTokenizer来分词(StringTokenizer用来分隔String的应用类) StringTokenizer tokenizer = new StringTokenizer(value); while(tokenizer.hasMoreTokens()){ String word=tokenizer.nextToken(); if(!hashMap.containsKey(word)){ //判断hashMap里面是否有该单词 hashMap.put(word, new Integer(1)); //如果没有 把word的值当作键 ,key值记作一次 }else{ int k=hashMap.get(word).intValue()+1; //如果有 把word的值当作键 ,key值在原来基础上在加一次 hashMap.put(word, new Integer(k)); } } }
3.统计单词并排序。
ArrayList<Map.Entry<String, Integer>> Com = new ArrayList<Map.Entry<String, Integer>>(hashMap.entrySet()); //使用Collections 工具类 里面的sort方法进行排序 Collections.sort(Com, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return (o2.getValue() - o1.getValue()); }; }); System.out.println("Total :" + hashMap.size()); //遍历HashMap,输出结果 int count = 50; for (Map.Entry<String, Integer>comp : Com) { if (count-- < 0) break; System.out.println(comp.getKey() + ":\t" + comp.getValue()); } } }
4.在控制台输入命令。
/** * 控制台下输入命令 * 可以是目录或者是文件 * */ public static String scan(){ Scanner sc = new Scanner(System.in); System.out.print("请输入目录或者文件:"); String text = sc.next(); return text; } }
运行结果:
1.读取目录。
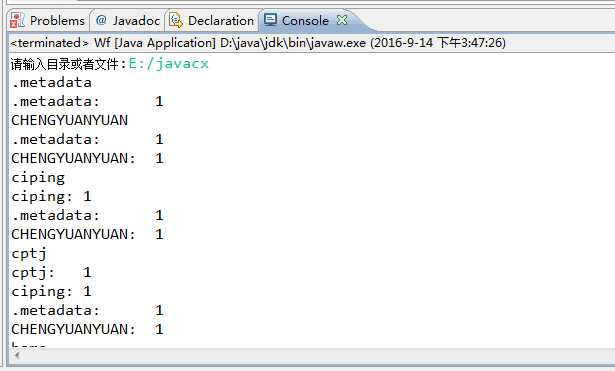
2.读取目录中的文件。
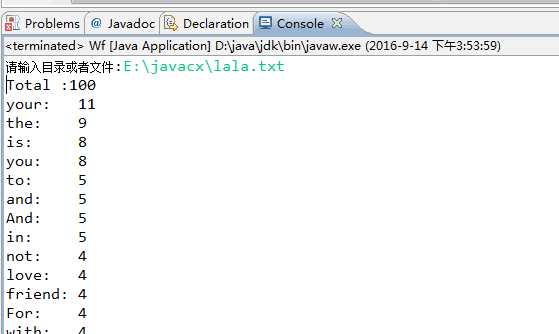
以上是关于第二周:词频统计改进的主要内容,如果未能解决你的问题,请参考以下文章