redis源码分析----字典dict
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码分析----字典dict相关的知识,希望对你有一定的参考价值。
1. dict的特点
字典dict采用hash表作为底层的存储结构。
1. hash表的长度保持为2的N次方,最大长度为LONG_MAX。
2. hash表采用链式法来解决hash值冲突。
3. dict数据结构中保存了两个hash表指针,用于实现rehash的过程。
4. 为了防止大数据量情况下rehash过程过分耗时,dict采用渐进式rehash,将rehash的过程分散到每一个增删改查的操作中,从而分摊耗时。
2. dict的定义
1 //hash表元素 2 typedef struct dictEntry { 3 void *key; 4 union { 5 void *val; 6 uint64_t u64; 7 int64_t s64; 8 double d; 9 } v; 10 struct dictEntry *next; // 链接指针 11 } dictEntry; 12 13 /* 14 * 自定义的函数,用于实现深度赋值,删除和自定义比较等 15 */ 16 typedef struct dictType { 17 unsigned int (*hashFunction)(const void *key); 18 void *(*keyDup)(void *privdata, const void *key); 19 void *(*valDup)(void *privdata, const void *obj); 20 int (*keyCompare)(void *privdata, const void *key1, const void *key2); 21 void (*keyDestructor)(void *privdata, void *key); 22 void (*valDestructor)(void *privdata, void *obj); 23 } dictType; 24 25 /* This is our hash table structure. Every dictionary has two of this as we 26 * implement incremental rehashing, for the old to the new table. */ 27 typedef struct dictht { 28 dictEntry **table; 29 unsigned long size; // table长度 30 unsigned long sizemask; // 长度mask,值为size-1 31 unsigned long used; // 当前保存了多少个元素 32 } dictht; 33 34 // hash表,其中有两个dictht结构,用于实现rehashing 35 typedef struct dict { 36 dictType *type; // 自定义操作 37 void *privdata; 38 dictht ht[2]; 39 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ 40 unsigned long iterators; /* number of iterators currently running */ 41 } dict;
dict结构图
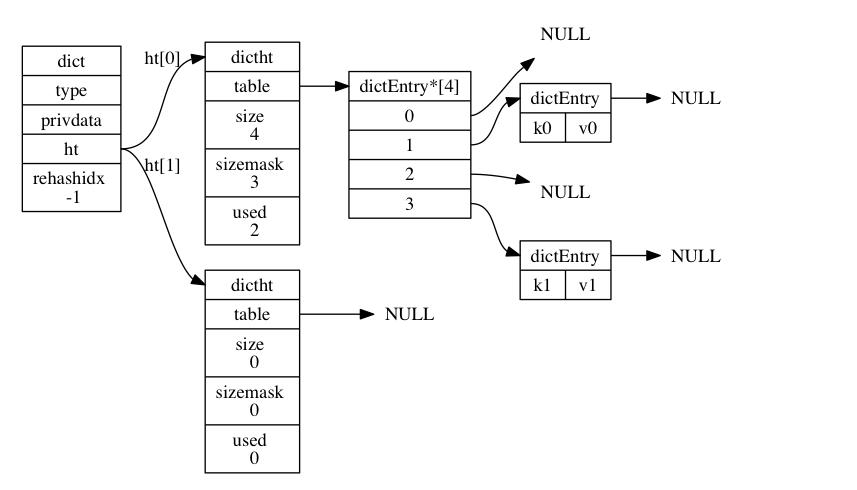
3. dict创建
1 /* Create a new hash table */ 2 dict *dictCreate(dictType *type, 3 void *privDataPtr) 4 { 5 dict *d = zmalloc(sizeof(*d)); 6 7 _dictInit(d,type,privDataPtr); 8 return d; 9 } 10 11 /* Initialize the hash table */ 12 int _dictInit(dict *d, dictType *type, 13 void *privDataPtr) 14 { 15 _dictReset(&d->ht[0]); 16 _dictReset(&d->ht[1]); 17 d->type = type; 18 d->privdata = privDataPtr; 19 d->rehashidx = -1; 20 d->iterators = 0; 21 return DICT_OK; 22 }
4. dict插入新元素
字典增加新元素使用函数dictAdd,内部首先调用dictAddRaw根据key在合适的位置插入新的Entry,然后再设置value。
1 /* Add an element to the target hash table */ 2 int dictAdd(dict *d, void *key, void *val) 3 { 4 // 增加新的key 5 dictEntry *entry = dictAddRaw(d,key); 6 7 if (!entry) return DICT_ERR; 8 // 设置value 9 dictSetVal(d, entry, val); 10 return DICT_OK; 11 }
dictAddRaw的流程总共分为4步,其中比较重要的是step2和step3,step2用于获取key在hash表的下标,如果正在rehash过程中,则这个下标是ht[1]中的,否则就是在ht[0]中,相应的step3选择相应的ht来插入Entry
1 dictEntry *dictAddRaw(dict *d, void *key) 2 { 3 int index; 4 dictEntry *entry; 5 dictht *ht; 6 7 // step1 : 如果当前正在rehash,则执行一次rehash 8 if (dictIsRehashing(d)) _dictRehashStep(d); 9 10 /* Get the index of the new element, or -1 if 11 * the element already exists. */ 12 // step2 : 获取key在hash表的下标 13 if ((index = _dictKeyIndex(d, key)) == -1) 14 return NULL; 15 16 /* Allocate the memory and store the new entry. 17 * Insert the element in top, with the assumption that in a database 18 * system it is more likely that recently added entries are accessed 19 * more frequently. */ 20 // step3 : 如果当前正在渐进式hash的过程中,则使用ht[1],将新元素加到队列头 21 ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; 22 entry = zmalloc(sizeof(*entry)); 23 entry->next = ht->table[index]; 24 ht->table[index] = entry; 25 ht->used++; 26 27 /* Set the hash entry fields. */ 28 // step4 : 设置key,这里要决定是否需要为key重新分配内存 29 dictSetKey(d, entry, key); 30 return entry; 31 }
_dictKeyIndex用来返回key所在的hash表的下标,它首先会检查是否需要扩展hash表(执行Expand操作)。_dictKeyIndex是一个内部函数,不应该被外部直接调用。
1 /* Returns the index of a free slot that can be populated with 2 * a hash entry for the given ‘key‘. 3 * If the key already exists, -1 is returned. 4 * 5 * Note that if we are in the process of rehashing the hash table, the 6 * index is always returned in the context of the second (new) hash table. */ 7 /** 8 * 获取key在字典的下标,如果key已经存在,则返回-1 9 */ 10 static int _dictKeyIndex(dict *d, const void *key) 11 { 12 unsigned int h, idx, table; 13 dictEntry *he; 14 15 /* Expand the hash table if needed */ 16 // step1 : 检查是否需要扩展hash表,并开始执行扩展操作 17 if (_dictExpandIfNeeded(d) == DICT_ERR) 18 return -1; 19 /* Compute the key hash value */ 20 h = dictHashKey(d, key); 21 // step2 : 获取index 22 for (table = 0; table <= 1; table++) { 23 idx = h & d->ht[table].sizemask; 24 /* Search if this slot does not already contain the given key */ 25 he = d->ht[table].table[idx]; 26 while(he) { 27 if (dictCompareKeys(d, key, he->key)) 28 return -1; 29 he = he->next; 30 } 31 // 如果字典没有执行rehash操作,则直接返回ht[0]中的下标 32 if (!dictIsRehashing(d)) break; 33 } 34 return idx; 35 }
_dictExpandIfNeeded 会判断当前是否需要扩展字典dict并在需要的时候执行扩展操作,它也是一个内部函数,红色的代码标明了扩展的条件:
1. 如果dict_can_resize被设置并且 used/size >= 1,则扩展dict,并且扩展的长度为used * 2;
2. 如果 used / size > dict_force_resize_ratio,则强制扩展操作 (dict_force_resize_ratio值为5)。
1 /* Expand the hash table if needed */ 2 /** 3 * 检查当前是否需要扩展hash表 4 */ 5 static int _dictExpandIfNeeded(dict *d) 6 { 7 /* Incremental rehashing already in progress. Return. */ 8 // step1 : 检查当前是否已经在进行渐进式rehash,如果是则返回OK 9 if (dictIsRehashing(d)) return DICT_OK; 10 11 /* If the hash table is empty expand it to the initial size. */ 12 // step2 : 如果当前hash表是空的,则直接扩展为初始大小 13 if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); 14 15 /* If we reached the 1:1 ratio, and we are allowed to resize the hash 16 * table (global setting) or we should avoid it but the ratio between 17 * elements/buckets is over the "safe" threshold, we resize doubling 18 * the number of buckets. */ 19 if (d->ht[0].used >= d->ht[0].size && 20 (dict_can_resize || 21 d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) 22 { 23 return dictExpand(d, d->ht[0].used*2); 24 } 25 return DICT_OK; 26 }
dictExpand函数执行扩展操作,如果是扩展空的hash表,则直接扩展,如果ht[0]不为空,则开启渐进式rehash过程
1 /* Expand or create the hash table */ 2 int dictExpand(dict *d, unsigned long size) 3 { 4 dictht n; /* the new hash table */ 5 // step1 : 计算真实长度,真实长度为第一个大于等于size的2的次方 6 unsigned long realsize = _dictNextPower(size); 7 8 /* the size is invalid if it is smaller than the number of 9 * elements already inside the hash table */ 10 if (dictIsRehashing(d) || d->ht[0].used > size) 11 return DICT_ERR; 12 13 /* Rehashing to the same table size is not useful. */ 14 if (realsize == d->ht[0].size) return DICT_ERR; 15 16 /* Allocate the new hash table and initialize all pointers to NULL */ 17 // step2 分配新的hash表结构并初始化 18 n.size = realsize; 19 n.sizemask = realsize-1; 20 //分配桶(bucket)数组 21 n.table = zcalloc(realsize*sizeof(dictEntry*)); 22 n.used = 0; 23 24 /* Is this the first initialization? If so it‘s not really a rehashing 25 * we just set the first hash table so that it can accept keys. */ 26 // step3 : 判断是初始化ht[0]还是执行rehash过程 27 if (d->ht[0].table == NULL) { 28 d->ht[0] = n; 29 return DICT_OK; 30 } 31 32 /* Prepare a second hash table for incremental rehashing */ 33 d->ht[1] = n; 34 d->rehashidx = 0; 35 return DICT_OK; 36 }
5. 删除元素
从dict中删除元素,注意如果在rehash的过程中,需要判断是否从ht[1]中删除
1 /* Search and remove an element */ 2 static int dictGenericDelete(dict *d, const void *key, int nofree) 3 { 4 unsigned int h, idx; 5 dictEntry *he, *prevHe; 6 int table; 7 8 if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */ 9 if (dictIsRehashing(d)) _dictRehashStep(d); 10 h = dictHashKey(d, key); 11 12 for (table = 0; table <= 1; table++) { 13 // step1 : 获取key在hash表中的index 14 idx = h & d->ht[table].sizemask; 15 he = d->ht[table].table[idx]; 16 prevHe = NULL; 17 while(he) { 18 // step2 : 比较key值,如果相同,则从链表中移除,然后释放 19 if (dictCompareKeys(d, key, he->key)) { 20 /* Unlink the element from the list */ 21 if (prevHe) 22 prevHe->next = he->next; 23 else 24 d->ht[table].table[idx] = he->next; 25 if (!nofree) { 26 dictFreeKey(d, he); 27 dictFreeVal(d, he); 28 } 29 zfree(he); 30 d->ht[table].used--; 31 return DICT_OK; 32 } 33 prevHe = he; 34 he = he->next; 35 } 36 if (!dictIsRehashing(d)) break; 37 } 38 return DICT_ERR; /* not found */ 39 } 40 41 int dictDelete(dict *ht, const void *key) { 42 return dictGenericDelete(ht,key,0); 43 } 44 45 int dictDeleteNoFree(dict *ht, const void *key) { 46 return dictGenericDelete(ht,key,1); 47 }
6. rehash过程
前面说到dict使用渐进式rehash方式,就是将rehash的过程平摊到每一个增删查改的操作中,在这些操作中,都可以看到这样两条语句: if (dictIsRehashing(d)) _dictRehashStep(d);
1 /* This function performs just a step of rehashing, and only if there are 2 * no safe iterators bound to our hash table. When we have iterators in the 3 * middle of a rehashing we can‘t mess with the two hash tables otherwise 4 * some element can be missed or duplicated. 5 * 6 * This function is called by common lookup or update operations in the 7 * dictionary so that the hash table automatically migrates from H1 to H2 8 * while it is actively used. */ 9 static void _dictRehashStep(dict *d) { 10 if (d->iterators == 0) dictRehash(d,1); 11 }
dictRehash是真正执行rehash过程的函数
1 int dictRehash(dict *d, int n) { 2 int empty_visits = n*10; /* Max number of empty buckets to visit. */ 3 if (!dictIsRehashing(d)) return 0; 4 5 while(n-- && d->ht[0].used != 0) { 6 dictEntry *de, *nextde; 7 8 /* Note that rehashidx can‘t overflow as we are sure there are more 9 * elements because ht[0].used != 0 */ 10 assert(d->ht[0].size > (unsigned long)d->rehashidx); 11 // step1 : 跳过连续为空的index,最多访问empty_visits个空index 12 while(d->ht[0].table[d->rehashidx] == NULL) { 13 d->rehashidx++; 14 if (--empty_visits == 0) return 1; 15 } 16 // step2 : 找到一个不为空的index,然后将该bucked里面所有的key移动到新的hash表中 17 de = d->ht[0].table[d->rehashidx]; 18 /* Move all the keys in this bucket from the old to the new hash HT */ 19 while(de) { 20 unsigned int h; 21 22 nextde = de->next; 23 /* Get the index in the new hash table */ 24 // 计算下标 25 h = dictHashKey(d, de->key) & d->ht[1].sizemask; 26 de->next = d->ht[1].table[h]; 27 d->ht[1].table[h] = de; 28 d->ht[0].used--; 29 d->ht[1].used++; 30 de = nextde; 31 } 32 // step3 : 将原来的bucket指针置为NULL 33 d->ht[0].table[d->rehashidx] = NULL; 34 d->rehashidx++; 35 } 36 37 // step3 : 如果已经移动完了所有的,则释放ht[0] 38 /* Check if we already rehashed the whole table... */ 39 if (d->ht[0].used == 0) { 40 zfree(d->ht[0].table); 41 d->ht[0] = d->ht[1]; 42 _dictReset(&d->ht[1]); 43 d->rehashidx = -1; 44 return 0; 45 } 46 47 /* More to rehash... */ 48 return 1; 49 }
7. hash函数
dict中使用的hash函数有3种:
1. Thomas Wang‘s 32bit整数hash函数。
2. MurmurHash2 hash函数
3. 大小写敏感的hash函数,基于djb hash。
1 /* -------------------------- hash functions -------------------------------- */ 2 3 /* Thomas Wang‘s 32 bit Mix Function */ 4 unsigned int dictIntHashFunction(unsigned int key) 5 { 6 key += ~(key << 15); 7 key ^= (key >> 10); 8 key += (key << 3); 9 key ^= (key >> 6); 10 key += ~(key << 11); 11 key ^= (key >> 16); 12 return key; 13 } 14 15 static uint32_t dict_hash_function_seed = 5381; 16 17 void dictSetHashFunctionSeed(uint32_t seed) { 18 dict_hash_function_seed = seed; 19 } 20 21 uint32_t dictGetHashFunctionSeed(void) { 22 return dict_hash_function_seed; 23 } 24 25 /* MurmurHash2, by Austin Appleby 26 * Note - This code makes a few assumptions about how your machine behaves - 27 * 1. We can read a 4-byte value from any address without crashing 28 * 2. sizeof(int) == 4 29 * 30 * And it has a few limitations - 31 * 32 * 1. It will not work incrementally. 33 * 2. It will not produce the same results on little-endian and big-endian 34 * machines. 35 */ 36 unsigned int dictGenHashFunction(const void *key, int len) { 37 /* ‘m‘ and ‘r‘ are mixing constants generated offline. 38 They‘re not really ‘magic‘, they just happen to work well. */ 39 uint32_t seed = dict_hash_function_seed; 40 const uint32_t m = 0x5bd1e995; 41 const int r = 24; 42 43 /* Initialize the hash to a ‘random‘ value */ 44 uint32_t h = seed ^ len; 45 46 /* Mix 4 bytes at a time into the hash */ 47 const unsigned char *data = (const unsigned char *)key; 48 49 while(len >= 4) { 50 uint32_t k = *(uint32_t*)data; 51 52 k *= m; 53 k ^= k >> r; 54 k *= m; 55 56 h *= m; 57 h ^= k; 58 59 data += 4; 60 len -= 4; 61 } 62 63 /* Handle the last few bytes of the input array */ 64 switch(len) { 65 case 3: h ^= data[2] << 16; 66 case 2: h ^= data[1] << 8; 67 case 1: h ^= data[0]; h *= m; 68 }; 69 70 /* Do a few final mixes of the hash to ensure the last few 71 * bytes are well-incorporated. */ 72 h ^= h >> 13; 73 h *= m; 74 h ^= h >> 15; 75 76 return (unsigned int)h; 77 } 78 79 /* And a case insensitive hash function (based on djb hash) */ 80 unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { 81 unsigned int hash = (unsigned int)dict_hash_function_seed; 82 83 while (len--) 84 hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */ 85 return hash; 86 }
以上是关于redis源码分析----字典dict的主要内容,如果未能解决你的问题,请参考以下文章