Hirbernate第三次试题分析
Posted Beyondづ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hirbernate第三次试题分析相关的知识,希望对你有一定的参考价值。
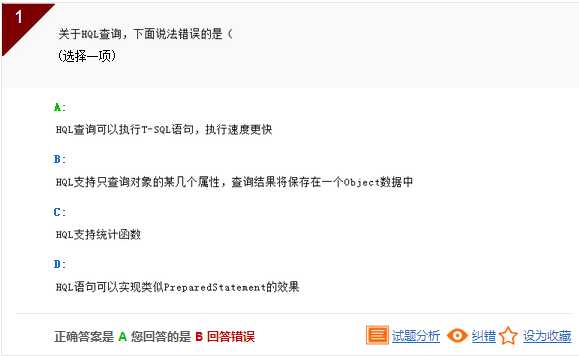
解析:HQL语句可以执行T-SQL语句,但执行步骤较复杂,需引入jar包等各种配置。
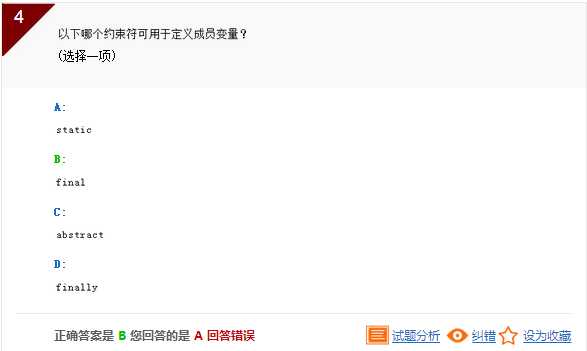
解析:final修饰的成员变量必须由程序员显式地指定初始值。 static一般用于修饰全局变量
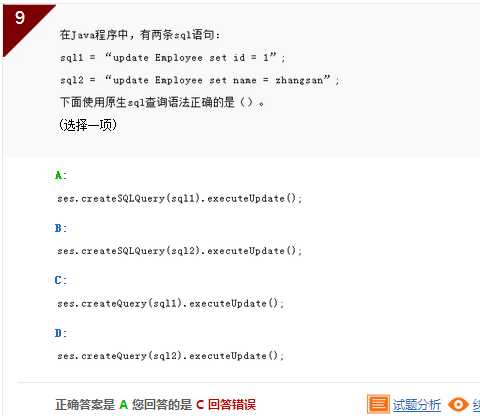
解析:Hibernate-原生SQL查询和命名查询中的使用原生SQL查询语句的命名查询的概念,还有Hibernate使用原生语句的语法。原生SQL语句中,字符串的输入要使用单引号引起来。创建查询要使用createQuery的方法。所以BCD都不正确,只有A正确。
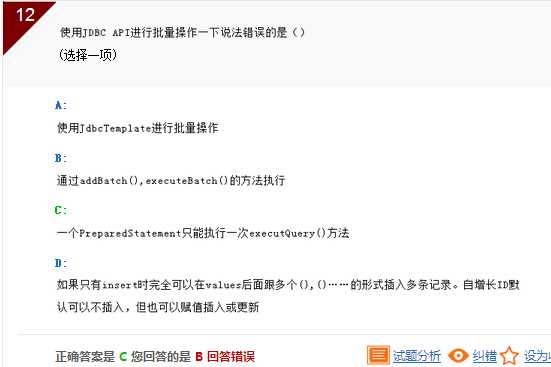
解析:一个PreparedStatement 可以执行多次executQuery方法,仅供参考。

解析:A使用HQL处理海量数据性能极低,不能采用这种方式。
B.JDBC API性能最好,最适合处理海量数据。
C.如果一次性flush,Hibernate会将操作的对象全部放到自身的内部缓存,将会造成内存溢出,所以也不能采用这种方式。
D.如果分为多次flush,可及时将缓存清除,也不失为一种办法。 所以答案选BD

解析:hibernate中{l.*}表示的是查询引用实体的属性。*号表示查询该实体类的所有属性
解析:请大神指教,评论一番,理解甚微。
解析:DAO层会及时清除缓存,即每插入一定量的数据后及时把它们从内部缓存中清除掉,释放占用的内存。

解析:总感觉有些坑,大神有意可以指教一番。
解析:命名查询通过在映射文件中配置<query>(对应HQL语句)或者<sql-query>(对应原生SQL语句)。使用session.getNamedQuery()方法获取执行命名查询的对象,其中填写内容则为上述标签中name属性的值。

解析:addEntity()方法将SQL表的别名和实体类联系起来,并且确定查询结果集的形态。不是追加实例,A错。 因为 createSQLQuery中的cat和addEntity中的cat必须要一样,D错。
解析:D表明的有点不太恰当。

解析:原生sql不可跨越数据库
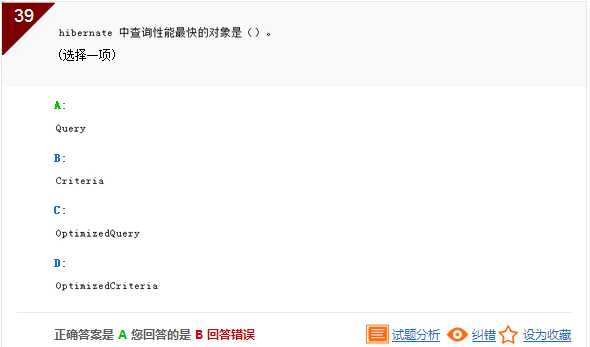
解析:Criteria在运行时动态生成查询语句,角度不同,考虑性能的话还是Query较快。

解析:引以为鉴

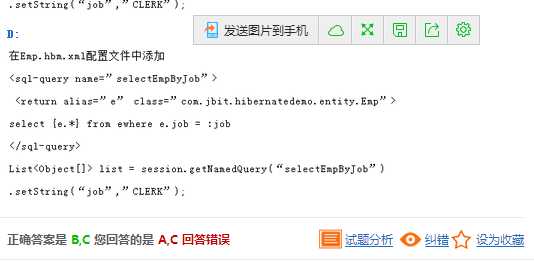
解析:A中应注意的是原生SQL在不绑定持久类的类型时的返回结果被封装为对象数组而不是实体类对象,因此A不正确。选项B的list使用了正确的泛型,并能查询出正确的结果。C是命名查询的主要方式,使用return标签绑定持久类并使用别名引用实体,因此查询出的结果被封装为实体类对象,是正确的。D的错误在于查询的结果被封装为实体类对象而不是对象数组。因此正确答案为BC
总结:点点滴滴,记忆犹新,坚持到底!!!
以上是关于Hirbernate第三次试题分析的主要内容,如果未能解决你的问题,请参考以下文章