week2 词频统计第一次更新
Posted 于淼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了week2 词频统计第一次更新相关的知识,希望对你有一定的参考价值。
词频统计:
对每个功能预计时间:
| 功能 | 预计(min) | 实际(min) |
| 数据流读入 | 20 | 40 |
| 正则规范字符串 | 15 | 20 |
| 排序 | 30 | 45 |
| 输出 | 20 | 30 |
| 其他 | 25 |
词频统计psp
| 日期 | 类型 | 任务 | 开始时间 | 结束时间 | 被打断时间 | 实际 | 计划 |
| 9.11 | 分析需求 | 看词频统计spec | 10:30 | 10:50 | 5 | 15 | 10 |
| 9.12 | 具体设计 |
设计词频分析流程包括 (读入文件流、去掉文章中非单词、按词频value降序排列、输出) |
10:00 | 11:00 | 10 | 50 | 40 |
| 9.12 | 具体编码 |
阅读上次代码,加入排序以及测试 (当前完成从控制台输入文件名称) |
15:00 | 18:00 | 20 | 160 | 120 |
| 9.12 | 代码复审 | 写博客,边写边看 分段上传 | 22:40 | 23:17 | 7 | 30 | 40 |
对比分析原因:首先以前对代码的练习不够,不能熟练编码。
对于数据流部分,多出来的时间是浪费在类型转换上,string类型与文件流之间的转换花费了很长时间。
对于正则表达式不熟悉,这样的东西总是记不住,浪费了时间。
sort方法是后学习的,原来只会用c++来理解,转换成Java花费了时间。
功能1:小文件输入键盘在控制台下输入命令。
在控制台输入文件名:使用scanner获取控制台数据
System.out.println("请输入要统计的文件路径");
Scanner sc = new Scanner(System.in);
String road = sc.nextLine();
FileInputStream fis = new FileInputStream(road);// 要读的文件路径
InputStreamReader isr = new InputStreamReader(fis);// 字符流
BufferedReader infile = new BufferedReader(isr); // 缓冲
从读取的txt文件中获取单词,使用正则,将非单词的部分转换成空格
String words[];
file = file.toLowerCase();
//正则将非字母,符号等用空格代替
file = file.replaceAll("[^A-Za-z]", " ");
file = file.replaceAll("\\\\s+", " ");
words = file.split("\\\\s+");
将获取的键值对存入hashmap
for (int i = 0; i < words.length; i++) {
String key = words[i];
if (map.get(key) != null) {
int value = ((Integer) map.get(key)).intValue();
value++;
map.put(key, new Integer(value));
} else {
map.put(key, new Integer(1));
}
}
对单词按词频(即键值对的value)进行降序排列。重写Collection类中的sort方法,完成降序。
List<Map.Entry<String,Integer>> list =new ArrayList<Map.Entry<String,Integer>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Entry<String, Integer> arg0, Entry<String, Integer> arg1) {
// TODO Auto-generated method stub
return arg1.getValue().compareTo(arg0.getValue());
}
});
对完成排序的键值对进行输出。使用util.Map包下的Entry对hashMap进行遍历输出
for(Map.Entry<String, Integer>mapping:list){
System.out.println(mapping.getKey()+","+mapping.getValue());
}
运行结果:


功能2. 支持命令行输入英文作品的文件名
>wf gone_with_the_wand
total 1234567 words
部分代码如下:
System.out.println("请输入要统计的文件名称");
Scanner sc = new Scanner(System.in);
String road = "E:\\\\artical\\\\";
road+=sc.nextLine();
road+=".txt";
将文件位置在代码中进行拼接,运行结果如下


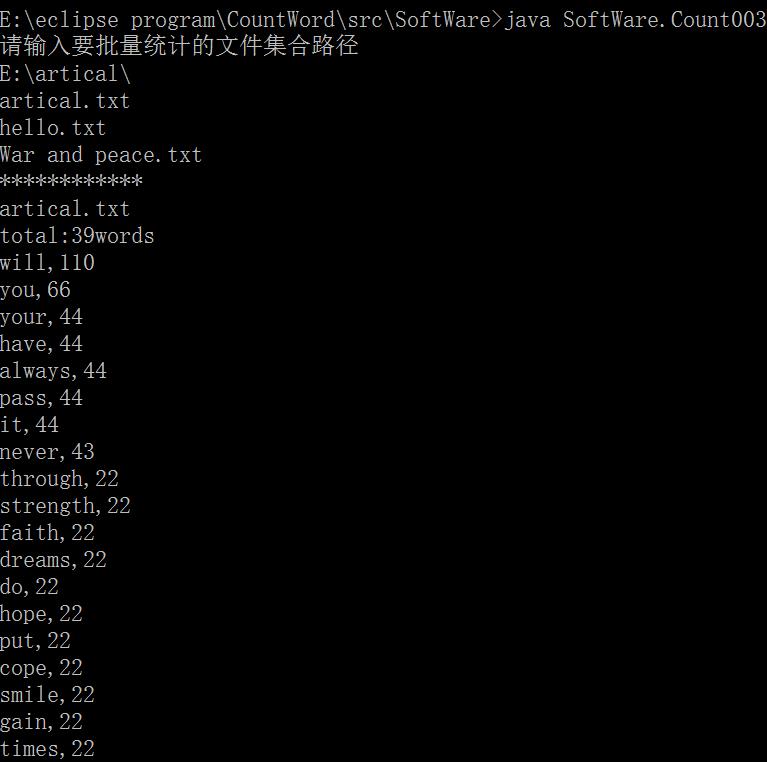
功能3. 支持命令行输入存储有英文作品文件的目录名,批量统计。
读入目录名,循环遍历每个txt文件,部分代码如下
System.out.println("请输入要批量统计的文件集合路径");
Scanner sc = new Scanner(System.in);
String road = sc.nextLine();
//批量文件
File f= new File(road);
File lis[]=f.listFiles();
for(int w=0;w<lis.length;w++){
String fileName=lis[w].getName();
System.out.println(fileName);
}
System.out.println("************");
for(int w=0;w<lis.length;w++){
String fileName=lis[w].getName();
System.out.println(fileName);
FileInputStream fis = new FileInputStream(lis[w]);
运行结果部分截图如下:
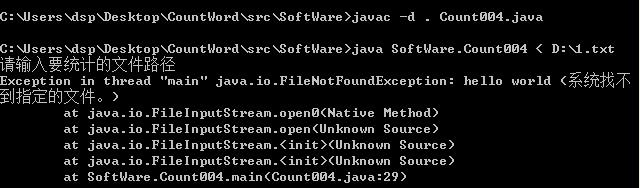
功能4. 从控制台读入英文单篇作品
在控制台可以输入英文文章名字或者文章内容
if(args.length==0){
Scanner in= new Scanner(System.in);
FileWriter fr = new FileWriter(new File("E:\\\\artical\\\\restlt.txt"));
while(in.hasNext()){
fr.write(in.nextLine()+"\\r\\n");
}
fr.close();
in.close();
}
以上代码将要识别的txt文件先写到result.txt文件中。< 为重定向对标准输入的控制
git: git://git.coding.net/yumiaomiao/WordCount.git
以上是关于week2 词频统计第一次更新的主要内容,如果未能解决你的问题,请参考以下文章