分布式缓存组件Hazelcast
Posted 超人汪小建(seaboat)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式缓存组件Hazelcast相关的知识,希望对你有一定的参考价值。
Hazelcast是一个Java的开源分布式内存实现,它具有以下特性:
- 提供java.util.{Queue, Set, List, Map}的分布式实现
- 提供java.util.concurrent.ExecutorService的分布式实现
- 提供java.util.concurrency.locks.Lock的分布式实现
- 提供用于发布/订阅的分布式Topic(主题)
- 通过JCA与J2EE容器集成和事务支持
- 提供用于一对多关系的分布式MultiMap
- 提供分布式事件和监听器的实现
- 提供集群应用和集群成员机制
- 支持动态HTTP Session集群
- 通过JMX监控和管理集群
- 为Hibernate提供二级缓存Provider
- 提供动态集群机制
- 提供动态分区和备份机制
- 支持动态故障恢复
- 简单通过jar包集成
- 运行速度快.
- 体积小
Hazelcast体系结构图
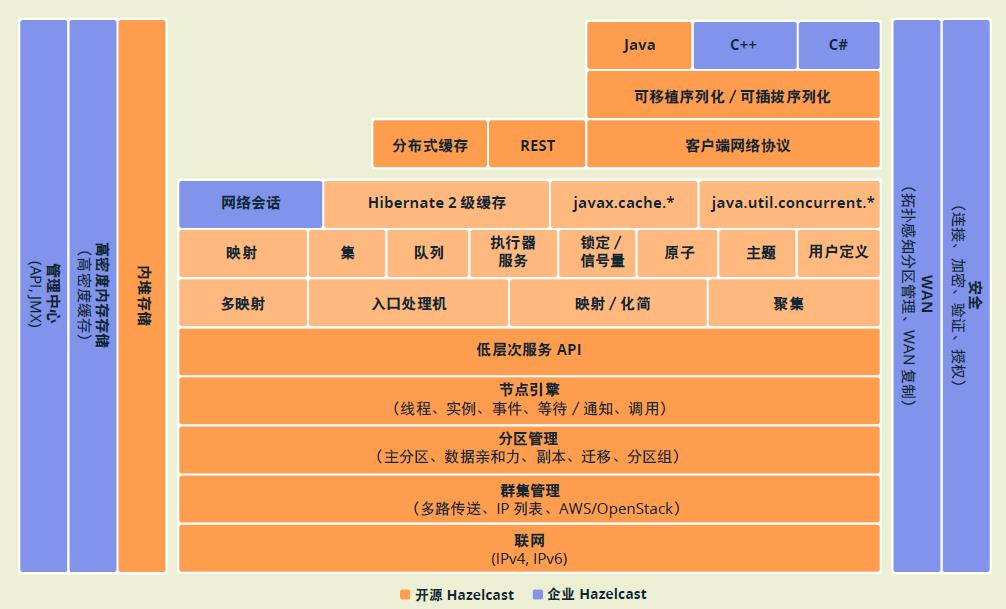
hazelcast拓扑
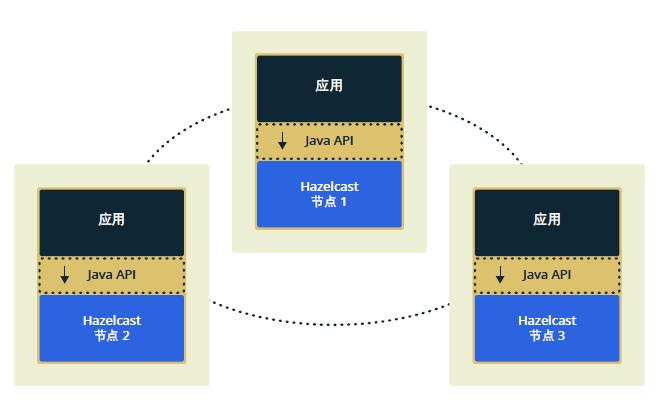
hazelcast拓扑结构可用于分布式集群。支持两种操作模式。采用”嵌入成员”模式时,含有应用代码的JVM直接加入Hazelcast群集,采用”客户端外加成员”模式时,备用JVM(可能在相同或不同的主机上)负责加入Hazelcast群集。这两种拓扑方法如下图所示:
嵌入模式:
客户端外加成员模式:
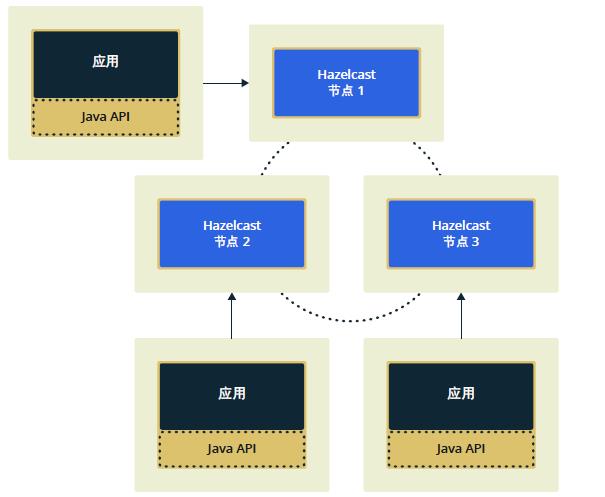
在多数情况下,可以采用客户端外加成员拓扑方法,因为就群集机制而言,它提供更大弹性 - 成员 JVM 可被拆卸和重新启动,不会对整体应用程序产生任何影响,因为 Hazelcast 客户端将只需重新连接到群集的另一个成员。另一种说法是客户端外加成员拓扑方法能够隔离纯粹群集级别事件的应用代码。
Hazelcast数据分区
Hazelcast中的数据分片被叫做partition。默认情况下,Hazelcast有271个partition。用一个数据的key,可以采用序列化哈希的算法将数据映射到具体的分区上面。分区会均匀分布在集群member的内存中。并且有多个副本保证高可用。
下面演示节点增加分区分布的情况:
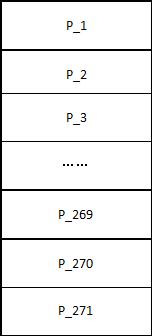
单个节点:
单仅启动一个节点的时候,该节点为master,且有默认的271个分区。
两个节点
启动第二个节点,第二个节点会加入第一个节点创建的集群中。第一个节点中的分区会重新分配,均匀分布在集群中。且集群中每个成员的数据分片都有一个副本。
加入更多节点
当加入更多节点的时候,原来节点中的数据分片会重新分布到新加入的节点上面,保证集群中数据分片的均匀分布。且同样会备份数据。下面是4个节点集群的数据分片分布:

分区算法
Hazelcast数据分片采用哈希算法。当给以一个map的key或是一个分布式对象的名称,会首先将key或对象名称进行序列化,转成byte array的形式,然后将byte array 进行哈希,将哈希结果对分区数求模得到分片ID。
分区表
分区表在第一个节点创建的时候就会生成。分区表是存储分区和节点的对应关系。作用在于让集群中的每个节点都可以知道分区和数据的信息。第一个启动的节点会将这个分区表周期性地发送给集群中的其他节点。这样,当集群中新增节点或是删除节点的时候,集群中的每个节点都可以拿到最新的分区信息。如果第一个节点(master)失败了,集群会选出新的master(第二个启动的节点),再由新的master将分区表发送给集群中的节点。发送的时间周期可以设置the hazelcast.partition.table.send.interval 系统属性,默认是15s.
以上是关于分布式缓存组件Hazelcast的主要内容,如果未能解决你的问题,请参考以下文章